Aşırı Öğrenme Problemleri Nedir ve Nasıl Çözülür?
Bir veri bilimi projesinde uygun bir model oluşturup uyguladıktan sonra, modelin başarısını değerlendirirken bazı sorunlarla karşılaşabiliriz. Bunlardan bazıları, makine öğrenimi modellerinde sıkça karşılaşılan “overfitting” ve “underfitting” terimleridir. Peki bunlar tam olarak ne anlama gelir ve bu iki uç arasında mükemmel dengeyi nasıl sağlarız? Hadi birlikte inceleyelim!
Geliştirilen bir modelin amacı, bağımlı ve bağımsız değişkenler arasındaki ilişkiyi ve bu ilişkinin anlamını çıkarmaktır. Bu durumda modelimizden veriyi ezberlemesini değil, veriler arasındaki yapıyı öğrenmesini bekleriz.
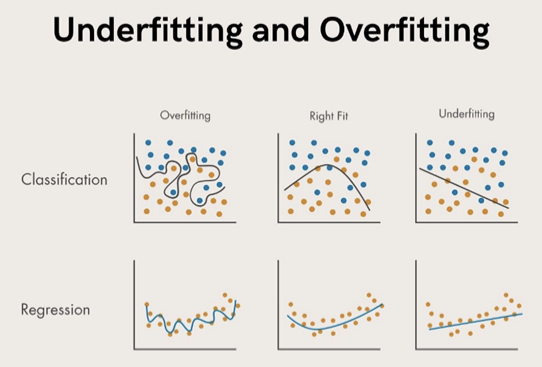
Underfitting
Modelin verilerdeki temel örüntüleri yakalamak için çok basit olması ve bu nedenle kötü performans göstermesi olarak tanımlanır.
Overfitting
Modelin çok karmaşık olması nedeniyle verilerdeki gürültüyü veya rastgele dalgalanmaları yakalamaya başlaması ve bu nedenle modelin daha önce karşılamadığı yeni verilere genelleme yaparken kötü performans göstermesi olarak tanımlanabilir.
Hedef, bu iki uç arasında dolaşan ve hem yanlılığı (modelin tahminlerinin gerçek değerlerden ne kadar farklı olduğu) hem de varyansı (modelin tahminlerinin farklı veri kümeleri için ne kadar değiştiği) en aza indiren optimal modeli bulmaktır. Bu model, eğitim veri setinin temsil edildiği veya ezberlendiği bir model değildir. Optimal modelin amacı veri setindeki ilişkinin, örüntünün yani yapının doğru temsil edilmesidir.
Aşırı öğrenme (overfitting) sorunu nasıl tespit edilir?
Aşırı öğrenme sorunu eğitim seti ve test setinin, model karmaşıklığı ve tahmin hatası çerçevesinde, birlikte değerlendirilmesi ile tespit edilebilir. Eğitim seti ve test setindeki hata değişimleri incelenir.
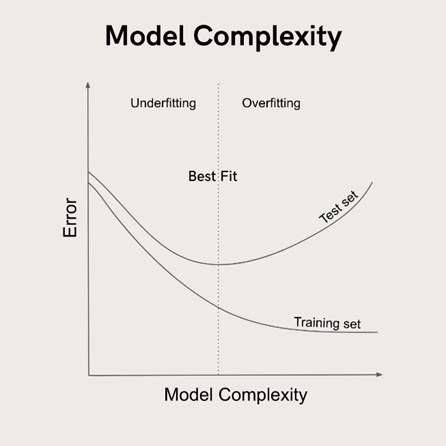
İki hatanın birbirinden ayrılmaya başladığı nokta (çatallanmanın başladığı nokta) itibariyle aşırı öğrenme başlamış demektir.
Overfitting (aşırı öğrenme) sorununu nasıl önleriz?
Kurulan bir modelin hassasiyetini artırarak daha detaylı tahminler yapabilmesi için özelliklerini güçlendirmeye odaklanırız. Bu süreç doğrusal modeller, ağaç yöntemleri ve sinir ağları gibi farklı yöntemler için değişiklik gösterir. Ancak bu durum model karmaşıklığını artırmak dolayısı ile aşırı öğrenme problemi ile karşılaşabilme ihtimalini artırmak demektir. Model karmaşıklığını (eğitim süresi, iterasyon süresi vb.) azaltmak, aşırı öğrenmenin önüne geçilmesindeki ana felsefedir. Model karmaşıklığını artırmak, belirli bir noktaya kadar hataları azaltasa da model performasının optimum olduğu noktanın ardından eğitim setinde ezberleme ve bunun neticesinde test seti ile yapılan analizlerde hataların artması durumu, yani overfitting ile karşılaşılacaktır.
Aynı zamanda aşırı öğrenmeyi önlemek için korelasyon, eksik değer ve aykırı değer analizleri büyük önem taşır. Örneğin, veri setinde yüksek korelasyona sahip bağımsız değişkenlerin varlığı, aynı bilgiyi taşımaları nedeniyle hem yanlılığa hem de aşırı öğrenmeye neden olabilir. Bu nedenle veri setinde yüksek korelasyon gösteren değişkenlerin yeniden irdelenmesi gerekebilir.
Overfitting sorununu çözümlendirmek için çeşitli yöntemler kullanılabilir. Bu yöntemlerden bazıları şunlardır:
- Regularizasyon: Modelin karmaşıklığını azaltarak aşırı öğrenmeyi önlemeye yardımcı olan bir tekniktir. L1 (Lasso) ve L2 (Ridge) regularizasyonu gibi çeşitli regularizasyon teknikleri mevcuttur. L1 regularizasyonu modeldeki özelliklerin ağırlıklarını sıfıra yaklaştırarak, önemsiz özelliklerin etkisini azaltır ve modelin genelleştirme yeteneğini artırır.
- Bagging (bootstrap aggregating): Modelin genelleştirme yeteneğini artırmak için birden fazla temel öğrenici kullanarak, rastgele örneklemle oluşturulan yeni veri kümeleri üzerinde eğitim yapar ve sonuçları birleştirir. Özellikle karar ağaçları gibi yüksek varyanslı modellerde etkilidir. Rassal orman (random forest) bu yöntemlerin en bilinen örneklerindendir.
- Data augmentation: Veri setini genişleterek modelin daha fazla öğrenme fırsatı bulmasını sağlar. Veri kümesindeki örneklerin dönüştürülmesi ve döndürülmesi gibi tekniklerle, modelin yeni verilere daha iyi genelleme yapabilmesi hedeflenir. Bu yöntem, özellikle derin öğrenme ve görüntü tanıma gibi alanlarda kullanılır.
- Erken durdurma (early stopping): Eğitim sürecini, test hatası artmaya başladığı anda durdurarak aşırı öğrenmeyi önleyen bir tekniktir. Bu sayede, modelin daha önce karşılaşmadığı verilere genelleme yaparken kötü performans göstermesi engellenir.
- Çapraz doğrulama (cross-validation): Veri setini birden fazla parçaya böler ve her bir parçayı sırayla test seti olarak kullanarak modelin başarımını değerlendirir. Bu yöntemle modelin farklı veri alt kümeleri üzerindeki performansı ölçülür ve aşırı öğrenme riski azaltılır. K-fold ve stratified k-fold çapraz doğrulama en yaygın kullanılan yöntemlerdendir.
Farklı makine öğrenimi modelleri, aşırı öğrenmeye neden olabilecek farklı değişkenlere sahiptir. Modellere göre çözümlendirme tekniklerine örnek verelim:
- Doğrusal yöntemler: Modele üstel terimler eklemek yani modeli hassaslaştırmak, modeli daha detaylı tahminler yapabilir hale getirmek anlamına gelir. Başka bir deyişle modeli karmaşıklaştırmak olarak ifade edilir.
- Ağaç yöntemleri: Dallandırma tekniği modeli karmaşıklaştırmak için kullanılır. Optimizasyon yöntemlerine dayalı ağaç yöntemlerinde (LightGBM gibi) iterasyon sayısı model karmaşıklığı parametresi olarak kullanılır. Örneğin iterasyon sayısının 100, 500, 1000 şeklinde artırılması eğitim aşamsında hatayı düşürebilecek ancak test aşamsında artırabilecektir.
- Yapay sinir ağları: Katman sayısı, hücre sayısı, iterasyon sayısı arttırıldığında, öğrenme oranı (learning rate) gibi parametrelerde ayarlamalar yapıldığında veya opsiyonlar artırıldığında bir noktaya kadar eğitim setinde hata düşecek ancak ardından test setindeki hata artacaktır.
Aşırı öğrenme problemine sektörün içinden gerçek iş problemi örneği verelim:
Yüz tanıma uygulamalarında, aşırı öğrenme probleminin önüne geçmek büyük önem taşır. Örneğin, bir güvenlik kamerası sistemi yüz tanıma özelliği kullanarak belirli kişilerin binaya girişini otomatik olarak denetlemek isteyebilir. Eğitim setindeki yüz görüntüleri, farklı ışık koşulları, açılar ve yüz ifadeleri ile sınırlıdır. Bu durumda, modelin eğitim setini ezberlemesi ve yeni, daha önce görülmemiş yüz görüntülerine kötü genelleme yapması büyük bir sorun teşkil eder.
Bu problemin çözümü için data augmentation ve çapraz doğrulama yöntemleri kullanılabilir. Data augmentation ile eğitim veri setindeki yüz görüntülerini döndürerek, yeniden ölçeklendirerek ve farklı ışık koşulları altında görüntüleyerek veri seti zenginleştirilir. Bu sayede model, farklı koşullar altında daha iyi genelleme yapabilecek şekilde eğitilir. Çapraz doğrulama ile de modelin performansı sürekli olarak kontrol edilerek aşırı öğrenme riski azaltılır.
Sonuç olarak, aşırı öğrenme probleminin çözümü için farklı teknikler ve yöntemler kullanılabilir. İdeal çözüm, projeye ve kullanılan makine öğrenimi modeline bağlı olarak değişkenlik gösterebilir. Aşırı öğrenme problemini önlemeye yönelik bu tekniklerin uygulanması, modelin başarımını artırarak gerçek hayatta daha güvenilir ve doğru tahminler yapabilmesini sağlar.
Aşırı öğrenme problemi ve makine öğrenmesi ile ilgili eğitimler almak için Miuul’un sunmuş olduğu içeriklere göz atabilir; böylece veri bilimi kariyerinizde, Miuul’un uzman kadro ve desteği ile, emin adımlarla ilerleyebilirsiniz.
Kaynaklar
Towards Data Science, Overfitting
Wikipedia, Overfitting
Veri Bilimi Okulu, Aşırı öğrenme (overfitting)
Miuul, Makine öğrenmesi
GeeksforGeeks, ML | Underfitting and Overfitting
