BigQuery ML ile çok terimli regresyon
BigQuery ML, basit standart SQL sorguları kullanarak verinin ön işlenmesinden dönüştürülmesine ve model kurulumuna kadar birçok aşamada veri bilimciye yardımcı olabilecek çeşitli kolaylıkları içerisinde barındırarak veriyi taşımamıza gerek kalmadan model oluşturmamıza olanak tanır. Tahminler sırasında bu dönüşümleri otomatik olarak uygulayıp argümanlar ile ihtiyaç duyulan bütün işlemleri gerçekleştirdiğinden dolayı BigQuery ile birlikte makine öğrenimi modellerinin üretimi büyük ölçüde kolaylaşır. Model kurma sırasında kullanıma sunulan fonksiyonlar sayesinde modeli karmaşık yapılara sokmadan spesifik işlemleri tanımlamamız mümkün kılınmıştır.
Tamraparni Dasu ve Theodore Johnson Exploratory Data Mining and Data Cleaning başlıklı çalışmasında bir veri bilimi projesinin hayata geçme sürecinde zamanın yüzde 80'inin veri temizliği ile harcandığını belirtir. Harcanan efor hangi makine öğrenimi projesini gerçekleştiriyor olursak olalım pek değişmeyecektir. Bu noktada Google Cloud ortamında çalışmanın getirdiği birçok avantaj bulunmaktadır.
- BigQuery ML'de model veri tabanı içerisinde ETL işlemi kurulduğundan farklı ortamlara aktarırken karşılaşılabilecek sorunlar da ortadan kalkmakta.
- BigQuery motorunun yapısı gereği rastgele küçük örnekler almak yerine büyük veri kümeleri verimli bir şekilde tarandığından ve BigQuery ML stokastik sürüm yerine gradient descent standart varyantını temel aldığından daha hızlı bir şekilde çalışarak model efektifliği artmakta.
- ML modellerinin daha basit olmasını ve daha hızlı yakınsamasını sağlamak için özellik çaprazları gibi işlemleri kullanarak ham verilerden yeni özelliklerin tasarlanmasına imkan tanımakta.
- Herhangi bir kütüphane indirmeye gerek kalmadan ihtiyaç olan fonksiyonları tek bir argüman ile uygulayabilmekte.
- Python, Java gibi programlama dillerine gerek kalmadan yalnıza SQL ile bütün işlemleri tamamlayarak SQL bilen herkesin ML kütüphanelerine erişebilmesini sağlamakta.
- Sonuçları veri tabanında yorumlayıp çıktıyı farklı ortamlara aktarmadan çalışmalarda doğrudan kullanabilmekte.
Hangi algoritmalarla çalışmalar gerçekleştirilebilir?
BigQuery ML’in kullanıcılara sunmuş olduğu başlıca model tipleri:
- Linear Regression
- Binary Logistic Regression
- Multiclass Logistic Regression
- K-means Cluestering
- Matrix Factorization
- Time Series
- Boosted Tree
- DNN
- AutoML Tables
- TensorFlow Model
- Autoencoder
Seçilen konu bağlamında en uygun model tipi seçilerek algoritmalarımızı çalıştırabiliriz. Seçilen algoritmaların kullanıma açık olup olmadığına ve ilgili BigQuery fiyatlandırmasına çalışmaya başlamadan önce dikkat etmekte fayda olacaktır.
Bu yazıda BigQuery ML kullanımına örnek olarak UCI'ın paylaştığı otomobil veri seti üzerinden çok terimli lojistik regresyon kullanımını baştan sona inceleyeceğiz. Sigorta şirketleri araçların riskli olup olmadığına sembolleme denilen bir yöntemle karar verirler. Araç özellikleri ve fiyatlandırmasına göre atanan bu risk faktöründe +3 değeri otomobilin riskli olduğunu, -3 ise oldukça güvenli olduğunu gösterir.
Veri setimizde toplam 26 adet değişken bulunuyor ve içerisinde N/A değerler olan 205 satır veri var.
Veriyi içeriye nasıl aktarabiliriz?
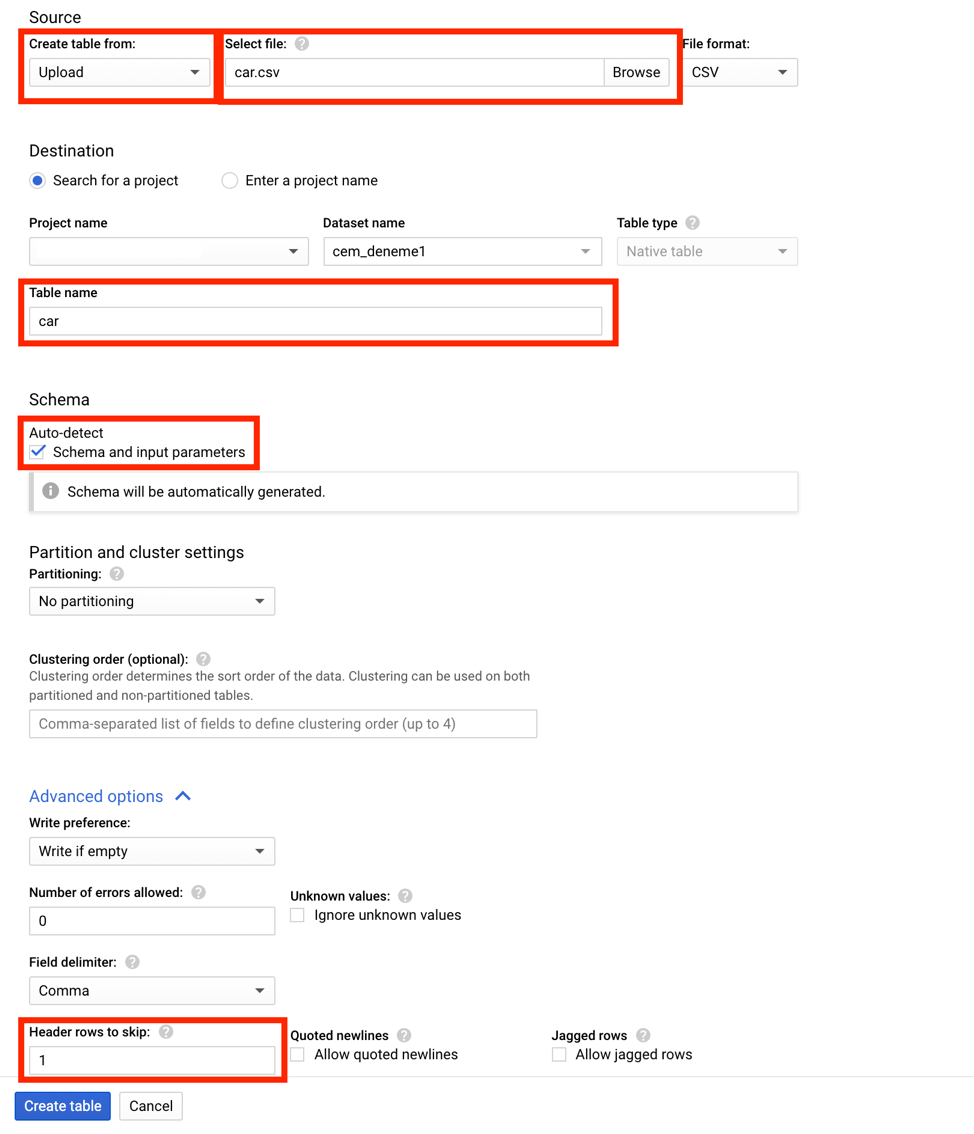
BigQuery içerisindeki çalışma alanına tıkladığınızda veri setini yüklemek için CREATE TABLEa bastıktan sonra eğer veri lokalde ise upload seçeneğini seçerek, değilse ilgili yükleme yöntemini seçerek ilerleyebilirsiniz. Veri setine isim verdikten sonra eğer sütun isimleri csv dosyasında mevcut ise BigQuery’nin bunu otomatik algılaması için auto-detect seçeneği seçilerek ilk satırın atlaması sağlanabilir ve sütun isimleri getirilebilir. Eğer veri setinde sütun isimleri yok ise isimlendirmeleri elle yaparak veriyi içeri alabilir ya da direkt BigQuery içerisinden veriyi çekerek işlemlere başlayabilirsiniz.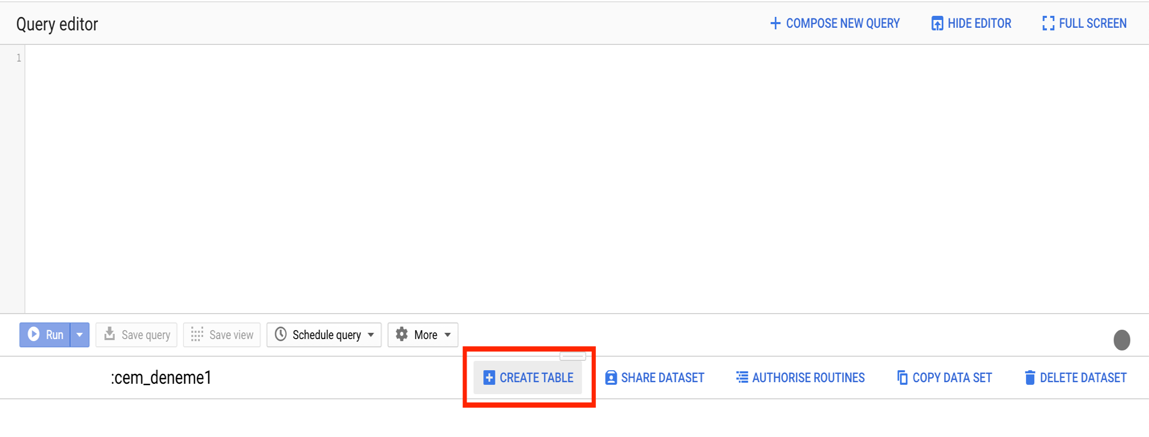
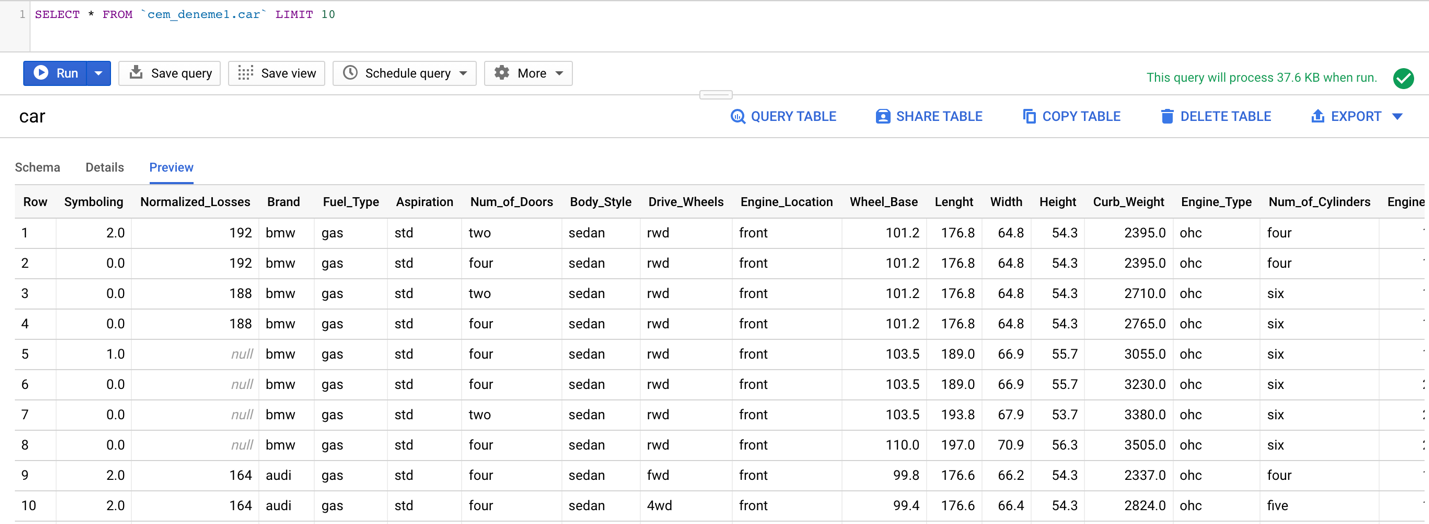
Veri setinin ilk 10 gözlemini incelediğimizde verinin eksiksiz bir şekilde yüklenmiş olduğunu görebiliyoruz.

Google araçları ile veri görselleştirme mümkün mü?
Veriyi EDA işlemleri için Google’ın bir başka ürünü olan DataStudio ortamına aktarıp görselleştirme işlemlerini gerçekleştirebiliriz. Bu uygulama veriyi istenilen kırılımlarda gruplayarak yorumlamak istediğimiz metotlar doğrultusunda grafikleri hazırlayıp ön bilgi sağlamak için yeterli desteği sunacaktır. Verideki marka ve kasa tipi kırılımında bağımlı değişkeni incelediğimizde aşağıdaki grafikleri elde edebiliriz. Bu da bize bazı ön bilgileri pratik bir biçimde kazandırmış oluyor. 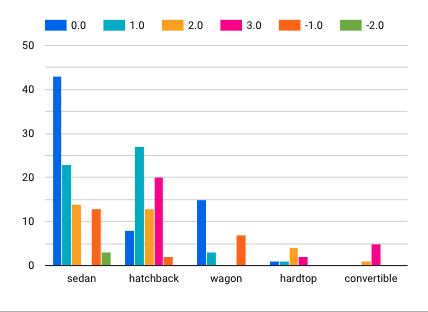
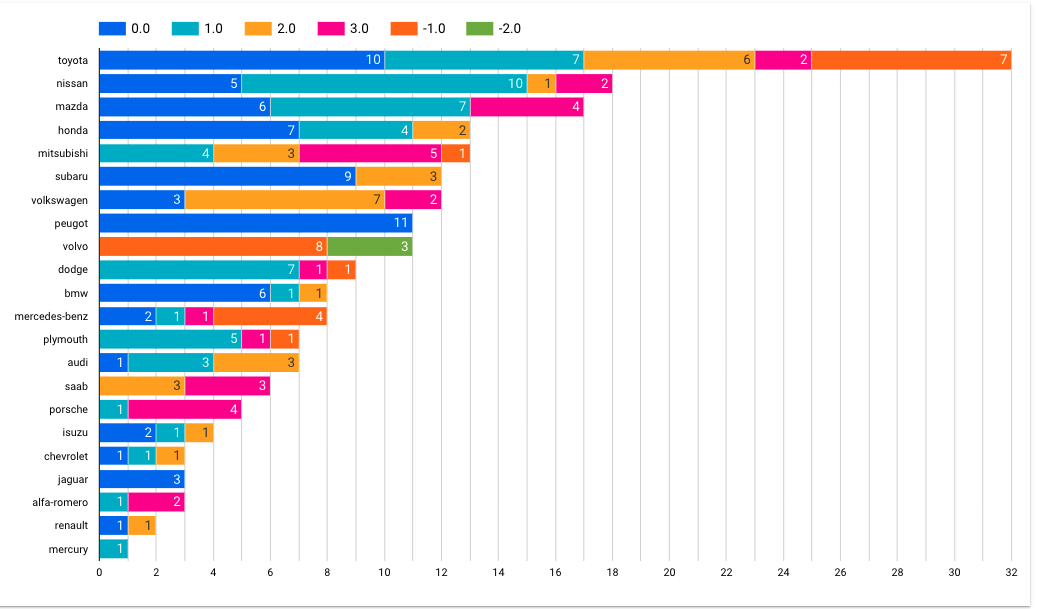
Ham veri model için nasıl hazırlanır?
Fiyat değişkenimizi dinamik bir şekilde çeyrekliklere ayıralım. Çekiş adında motor büyüklüğü birim başına 1 beygir düşüyorsa 1, düşmüyorsa 0 döndüren bir özellik türetelim. Araç ağırlığı ve yüzey alanını kullanarak araç basıncının hesaplandığı bir özellik daha ekleyip ortalama yakıt tüketimini hesaplayalım ve veriyi modele sokmadan önce yeni bir tablo olarak dizine kaydedelim.
Önemsiz olduğuna karar verdiğimiz ve içerisinde çok fazla N/A değer barındıran normalized losses gibi değişkenleri ise hazırladığımız tablonun dışında bırakarak işlemleri gerçekleştiriyoruz. 
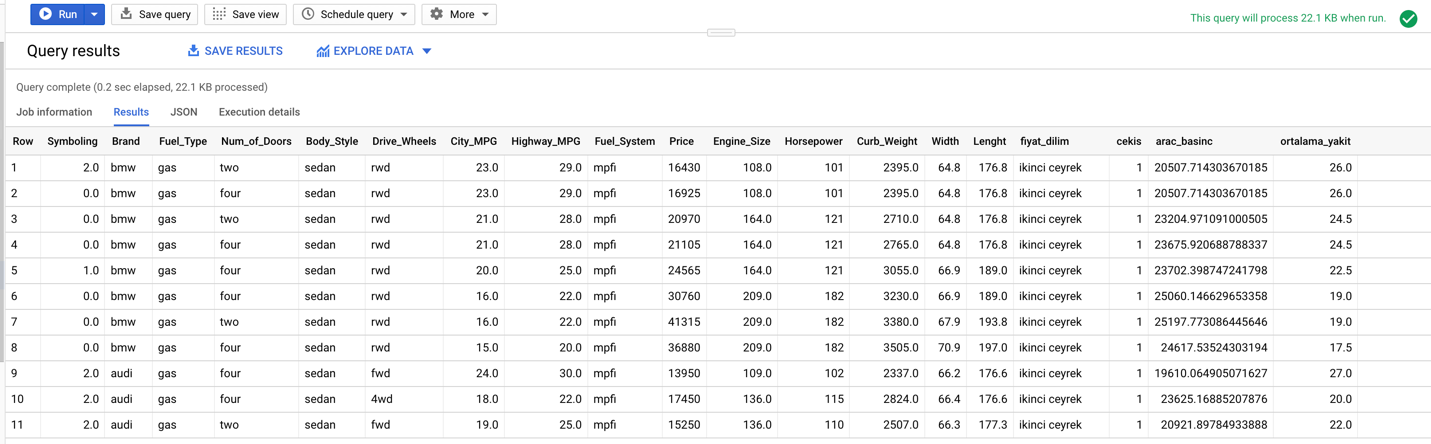
Model kurma
Dizine kaydolan tabloyu çağırıp uygulamak istediğimiz model tipini ve model parametrelerini girerek modeli kurup işlemleri tamamlayabiliriz. Model tipini, çok sınıflı sınıflandırma problemi olarak uygulayacağımızdan lojistik regresyon giriyoruz. Bağımlı değişken sütun ismini verdikten sonra modeli özelleştirecek argümanlara geçebiliriz. Burada kullanmış olduğumuz argüman ve değerler tamamen ihtiyaca yönelik olarak belirlenmiştir. Bunlar farklı değerlerle kullanılabileceği gibi daha fazla özellikte fonksiyonlar ekleyerek modeli özelleştirmek de mümkün. Bu argümanlar kullanılmadan önce her birini detaylı bir şekilde inceleyip ihtiyaç doğrultusunda çalıştırmakta da fayda olacaktır. Aşırı öğrenmeyi engellemek için model çaprazlanmasını durduran early_stop parametrelerini veriyoruz. Veri setimde değişken sayısı az olup elimizde validasyon ve test verileri olmadığı için kendi içinde eğitip değerlendirmesi adına auto_split_method argümanını da giriyoruz. Sınıf etiketlerinin, o sınıfın frekansıyla ters orantılı olarak her sınıf için ağırlıklar yardımıyla dengelenmesi yani değişkenlere özel ağırlıklandırma işlemi yapılması sürecinde model kurulurken kendi içinde karar verilsin diye auto_class_weights argümanını da True yapıyoruz. Tablodaki tüm sütunları modelde kullanmak istediğimiz için select içerisine hepsini yerleştiriyoruz.
Model başarısını nasıl ölçmeli?
Model doğrulama metriklerini yorumlayarak model başarısını ölçebileceğimiz tüm metrikleri BigQuery, otomatik olarak model içerisinde göstermekte.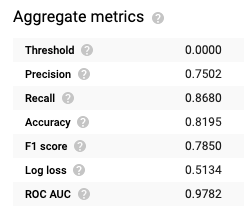
F1 skorunun ve AUC değerlerinin yüksek oluşu modele güvenebileceğimizin bir göstergesi olarak yorumlanabilir.
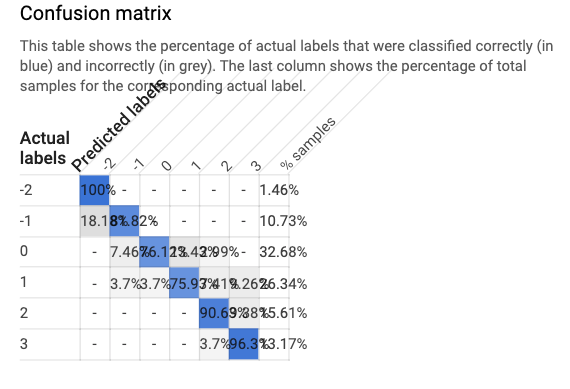
Doğrulama metriklerinin altında karmaşıklık matrisine yer verilse de daha detaylı bir çıktı elde etmek istiyorsak basit bir sorgu çalıştırabiliriz.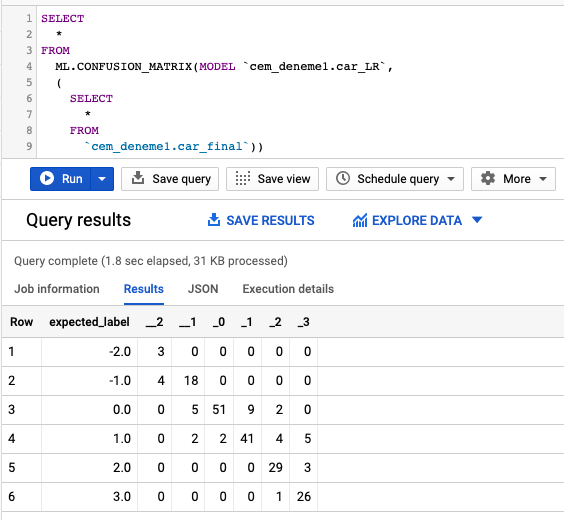
Karmaşıklık matrisininin detaylı analizinde hangi bağımlı değişkenlerde kaç tane hata yapıldığını ve hatayı hangi değer ile yaptığını gösteren grafiği yine BigQuery’nin sunduğu fonksiyonlar içerisinden getirebiliyoruz.
Peki ya sonra?

Predict fonksiyonunu çağırarak tahminlerimizi oluşturup çalışmalara doğrudan aktarabiliriz. Oluşan çıktıları tablo olarak kaydedip DataStudio ortamında rapor haline getirip görsel düzenlemeler ile okunabilirliği artırabiliriz.
Her gün veri tabanına dolan bilgiler ile ML.PREDICT fonksiyonunu scheduled query olarak ayarlayıp tahminleri elle müdahale etmeden düzenli olarak çalıştırıp sonuçlara erişebiliriz. Böylelikle zaman, maliyet ve yer tasarrufu sağlayarak veri tabanı üzerinden tahmin modelleri geliştirebilir, gündelik çalışmalarımıza doğrudan aktarım sağlayabiliriz.
Bu yazıda BiqQuery altyapısını kullanmama izin veren AloTech ailesine çok teşekkür ederim.
SQL hakkında daha geniş kapsamlı bilgiye erişmek ve kariyerinizde SQL bilginizle fark yaratmak isterseniz Miuul'un sunduğu MS SQL Developer eğitimine göz atabilirsiniz.
Kaynaklar
- Google Cloud, What is BigQuery ML?
- Google AI Blog, Machine Learning in Google BigQuery
- Google Cloud, Simplified data transformations for machine learning in BigQuery
- Kaggle, BigQuery Machine Learning Tutorial
- UCI, Automobile Data Set
