Dengesiz Veri Seti Ne Zaman Problem Olur?
Dengesiz veri seti, sınıflandırma problemlerinde farklı sınıflar için eşit sayıda gözlem olmaması durumunu tarif eder. Gerçek dünya verilerinde zaten bu sınıflar hemen hemen hiçbir zaman aynı sayıda olmazlar.
Örneğin bir veri seti düşünelim:
- 10 bin gözlem içersin.
- Hastaların kanser olup olmama durumlarını tahmin etmeye çalışıyor olalım.
- Hedef değişkendeki 1'ler kanser, 0'lar sağlıklı insanları temsil etsin.
Eğer burada kanserli insanlarla sağlıklı insanların sayıları birbirine eşit değilse (hedef değişkende 0–1 dengesi yarı yarı yarıya değilse) dengesiz veri seti ile karşı karşıyayız demektir. Zaten bir düşünecek olursanız, dengesiz veri çoğu sınıflandırma problemleminin doğasında var. Kanser olanlar olmayanlardan, dolandırıcılar dürüstlerden, spam e-postalar spam olmayanlardan daha az olur, biz de bu az gözleme sahip sınıfı tahmin etmeye çalışırız.
Dengesiz veri seti her zaman problem olarak karşımıza çıkmayabilir. Sınıflar arası fark küçükse göz ardı edilebilir.
Peki ama dengesiz veri seti ne zaman bir problem olarak karşımıza çıkar?
Google tanımı
Bazı kaynaklar azınlık sınıfın (minority class) tüm veriye oranı yüzde 20’den az ise bu direkt problemdir diye belirtirken, Google problemin şiddetini yukarıdaki tabloda belirtildiği şekilde sınıflandırmış.
Dengesiz veri setine müdahale etmemiz gerektiğini nasıl anlarız?
Cevap: Accuracy paradox! Sınıflandırma problemlerinde başarı değerlendirme yöntemlerinden biri de karmaşıklık matrisidir (confusion matrix).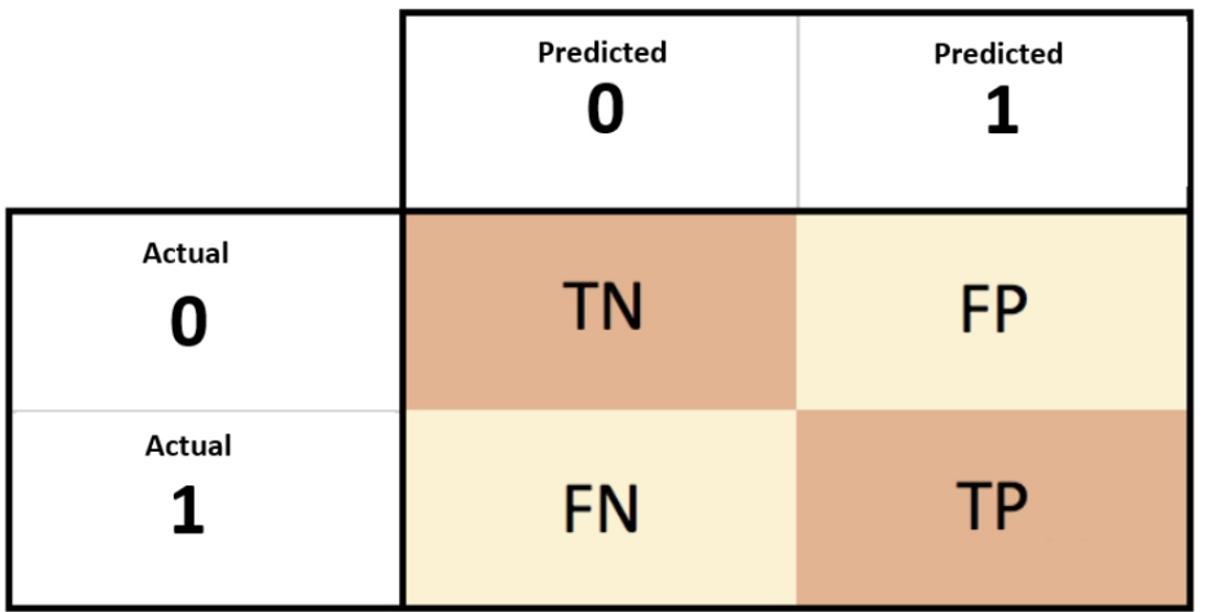
Kaynak: Packtup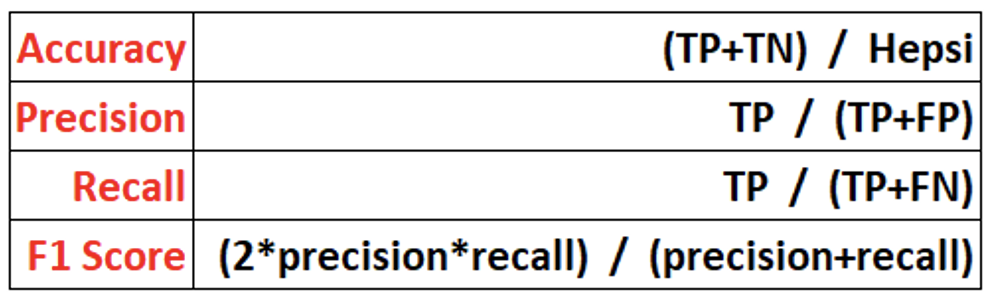
Accuracy, tahminlerin yüzde kaçının doğru olduğunu belirtir. Dengesiz veri setlerinde accuracy yüksek çıkar, biz de çok iyi tahmin yaptık diye düşünürüz. İşte bu duruma accuracy paradox denir. Tahmin doğruluğunu gösteren bu metrik dengesiz veri setlerinde anlamsız olabilir. Recall ve precision değerleri önem kazanır.
Yani, accuracy yüksek fakat recall veya precision düşük çıkıyorsa burada bir dengesizlik var sanırım demelisiniz!
Accuracy neden anlamsız olsun?
Örneğim 100 tane gözlem içinde 90 sağlıklı, 10 spam e-posta olsun.
Burada zaten tüm e-postaların sağlıklı olduğunu belirtirsek accuracy değerimiz yüzde 90 çıkar! Aşağıda confusion matrix ve başarı metrikleriyle belirtmeye çalıştım.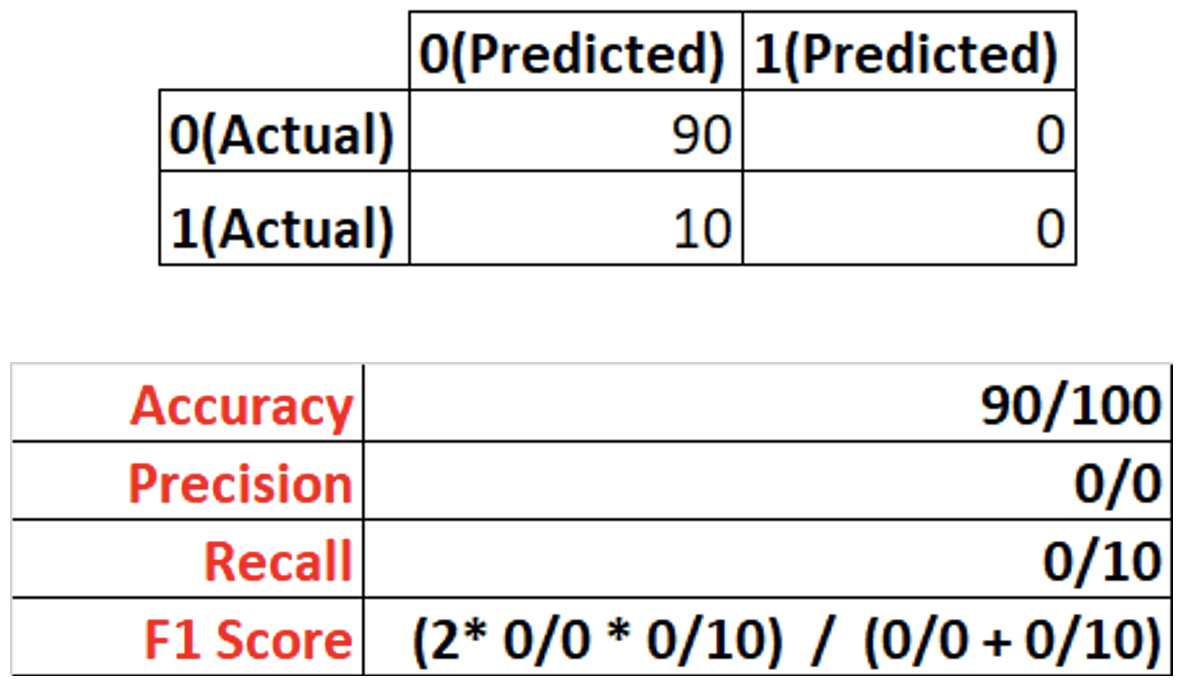
Dengesiz veri setinde confusion matrix nasıl yorumlanmalı?
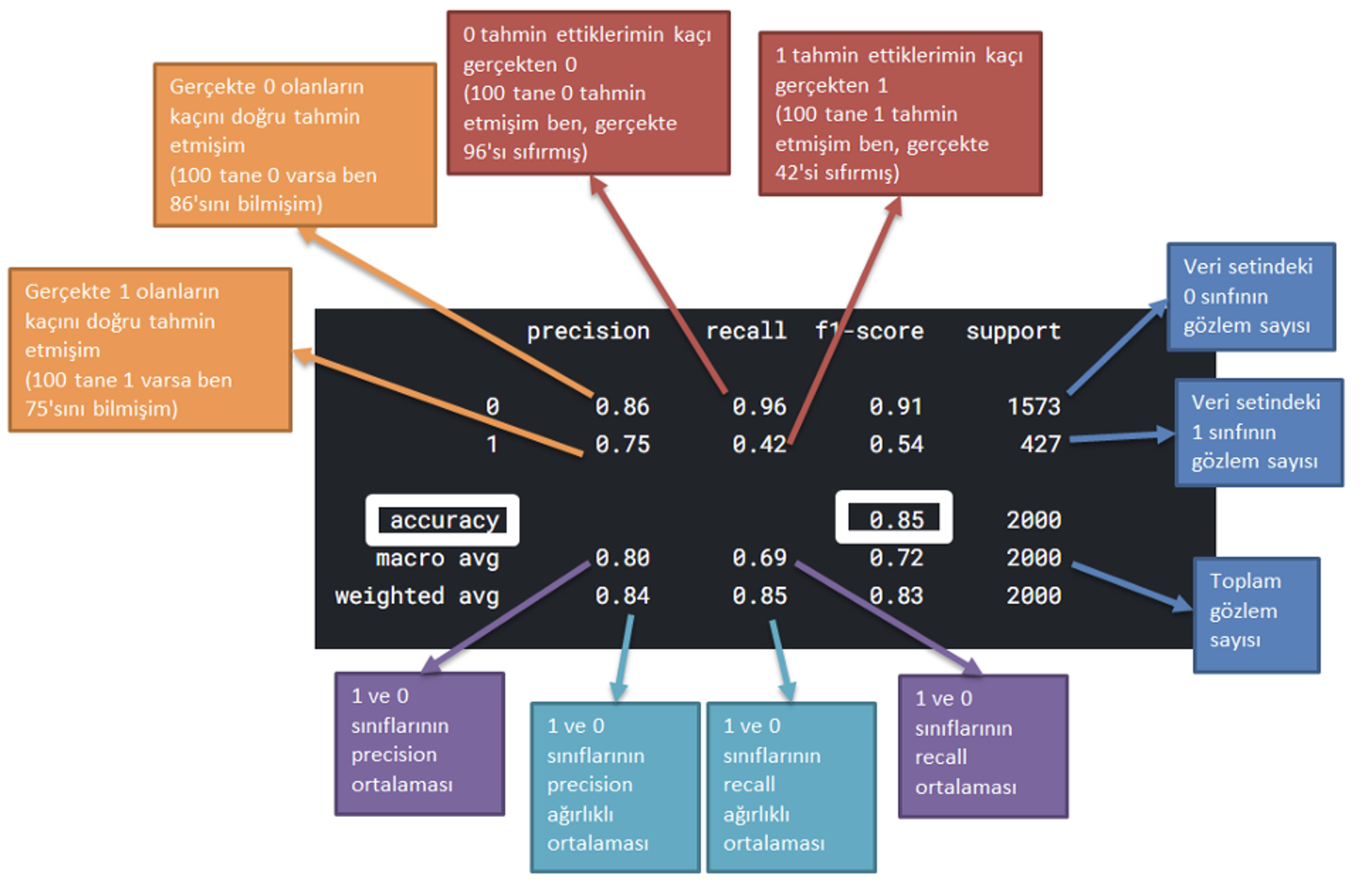
Çözüm Yolları
- Daha fazla veri toplama: Az gözlem bulunan sınıftaki gözlem sayısı artırılabilir.
- Undersampling: Azınlık sınıfta yeteri sayıda veri varsa, çoğunluk sınıfının gözlem sayısı rastgele seçim yapılarak azaltılabilir. Veri boyutu az değilse tercih edilir, bir miktar bilgi kaybı göze alınır.
- Oversampling: Kanaatimce undersampling yapılamıyorsa tercih edilmelidir. Overfite sebebiyet verme ihtimali çok yüksektir. Azınlık sınıftaki gözlem sayısı yeterli değilse, bu sınıftaki gözlemlerin kopyası oluşturularak çoğunluk sınıf sayısına eşitlenebilir.
- Biraz oversampling biraz undersampling: Veri setindeki azınlık sınıftaki gözlem sayısı az ise, oversampling yapılması gerektiyse, önce çoğunluk sınıf için undersampling sonra azınlık sınıf için oversampling uygulanabilir.
Resampling teknikleri arasında en sık kullanılan yöntem ise SMOTE (Synthetic Minority Oversampling Technique) olarak bilinir. Klasik veri kopyalama şeklinde hareket etmez. Veri kopyalama modele yeni bilgi vermez.
- K en yakın komşu algoritmasını kullanır.
- Öncelikle azınlık sınıftan random veri seçer.
- Seçilen random veri etrafındaki komşuları seçer. Komşu ile seçilen veri arasındaki yerde veri üretir.
- Bu işlem çoğunluk sınıftaki gözlem sayısına ulaşana dek tekrar eder.
SMOTE sadece continous verilere uygulanabilirken SMOTE-NC (Synthetic Minority Oversampling Technique - Nominal Continous) hem nominal hem continous verilere uygulanabiliyor. Bunların dışında ise Borderline-SMOTE, SVM-SMOTE ve ADASYN gibi resampling teknikleri bulunmakta.
Son bir not: Resampling metodlarının sadece train veri setine uygulanması önerilir.
Ham veriyi temizleyerek, ilgili veriden yeni özellik çıkarmak ve modele girmeye uygun olmayan değişkenleri dönüştürmek, kariyerinizde fark yaratacak adımlar atmak isterseniz Miuul'un sunduğu Özellik Mühendisliği eğitimine göz atabilirsiniz.
Kaynaklar
- Machine Learning Mastery, 8 Tactics to Combat Imbalanced Classes in Your Machine Learning Dataset
- Google, Imbalanced Data
- Towards Data Science, 5 SMOTE Techniques for Oversampling your Imbalance Data
- Elite Data Science, How to Handle Imbalanced Classes in Machine Learning
