Derin Öğrenme ile Derinlere Yolculuk
Son yıllarda yapay zeka alanında yeni haberlerin çıkmadığı gün neredeyse yok denecek kadar az. Siz de şu anda bu yazıyı okuyorsanız muhtemelen derin öğrenmenin yakın zamanda yapay zeka alanındaki sıra dışı ilerlemesi hakkında bilgi sahibisinizdir.
Günümüzde yaygınlaşmakta olan chatbotlar, sesli asistanlar ve otonom araçlar gibi teknolojilerin ileride tamamen yaşamımıza gireceği dünyada siz de bunların nasıl yapıldığını merak ediyorsanız ve geliştiricisi olmak istiyorum diyorsanız bu noktada devreye derin öğrenme girmektedir.
Derin öğrenme, insan beyninin çalışma şeklini referans alan bir makine öğrenmesi alt dalıdır. “Birbirini takip eden katmanlarda veriler işlenirken giderek artan şekilde daha kullanışlı gösterimler elde edebilen öğrenme türüdür.” Derin öğrenme, makinelerin dünyayı algılama ve anlamasına yönelik yapay zeka geliştirmede en popüler yaklaşımlardan biri olmuştur.
Derin öğrenme ile derin bilgiler elde etmek mümkün mü?
Tabii ki de hayır. Derin öğrenmede katmanlar aracılığı ile öğrenme işlemi gerçekleştiği için bu katmanların bir araya gelerek oluşturduğu yapının derinliğinden kaynaklı olarak derin öğrenme denilmektedir. Oluşturmuş olduğunuz modeldeki katman sayısı modelinizin derinliğini oluşturmaktadır. Modelde yer alan katman sayısı ne kadar fazla ise modeliniz o kadar derindir.
Klasik makine öğrenmesi yöntemleri olarak bildiğimiz modellerde nasıl öğrenme işlemi oluyor?
Klasik olarak bildiğimiz makine öğrenmesi modelleri genelde bir veya iki katmandan oluşur bazen karşınıza “sığ öğrenme” olarak da çıkabilmektedir. Derin öğrenmenin günümüzde adını bu kadar sıkça duymamızın en önemli sebeplerinden birisi ise 2012 yılında nesne sınıflandırma için düzenlenen, ImageNet yarışmasında elde ettiği başarı ile yapay zeka dünyasında büyük bir sıçrama gerçekleştirmesi.
Derin öğrenmenin günümüzde bu kadar yaygınlaşmasının sebepleri nedir?
En temelde iki sebebi bulunmakta:
“Veri mi artıyormuş? Artsın bana ne!” diyenlerden misiniz? Yoksa artan bu veriyi en iyi şekilde işleyip bu veriden değer çıkarmak mı istiyorsunuz? Günümüzde büyük veri kavramı oldukça gelişti. Her geçen gün dünyada üretilen veri miktarı hızlı bir şekilde artmakta. Derin öğrenmenin günümüzde bu kadar yaygınlaşma sebeplerinden ilki ise işte tam da bu eğitim için gerekli olan verilerin artması. Anlayacağınız aranan kan bulundu. Artan veriler etiketlenerek derin öğrenmede eğitim için rahatlıkla kullanılabilmektedir. Sonuç olarak derin öğrenme yüksek hesaplama gücüne sahiptir.
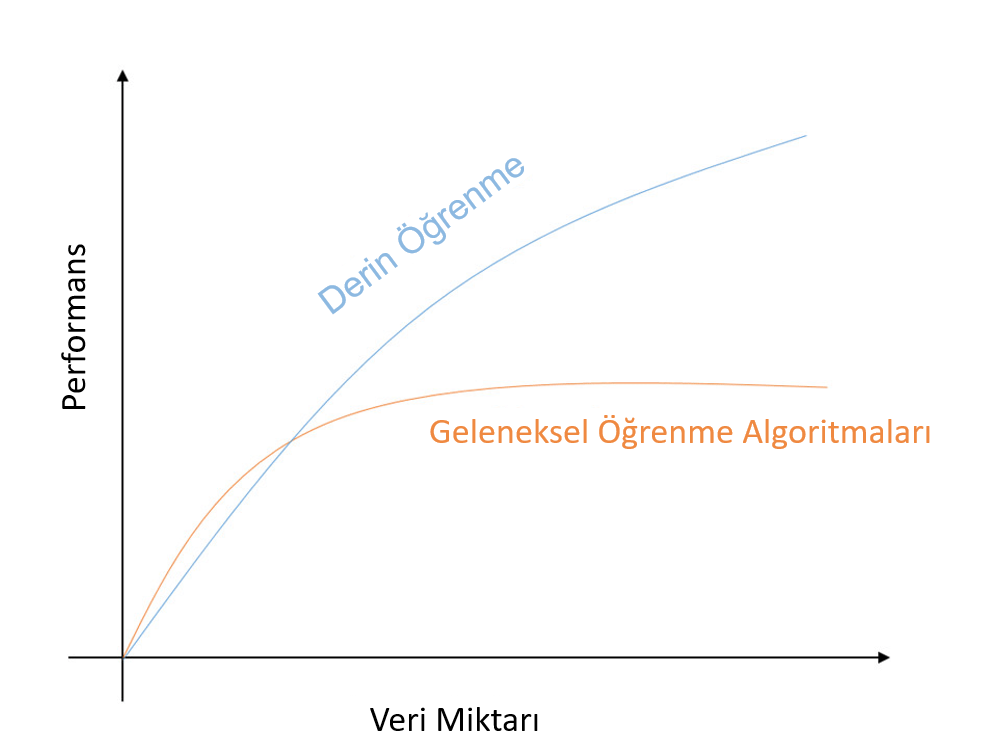
İkinci temel sebep ise donanımda yaşanan gelişmelerdir. Elimizde bu kadar fazla veri bulunmakta ancak bunları makul sürelerde işleyebilmemiz gerekir. Bu noktada Merkezi İşleme Birimleri kısaca CPU’lar (Central Processing Unit) üzerinde yapılan hesaplamalar yetersiz kaldığından dolayı yerlerini verileri paralel işleyen Grafik İşleme Birimlerine kısaca GPU’lara (Graphics Processing Units) bırakmıştır. Bu sayede etiketlenen veriler makul sürelerde işlenebilmekte ve derin öğrenme uygulamalarının önü açılmaktadır.
Derin öğrenme bugüne kadar neler başardı?
Neredeyse insan seviyesinde görüntü sınıflandırma, ses tanıma, el yazısı tanıma ve otonom araç sürüşü gibi işlemleri başardı. Bunlara ek olarak metinden ses üretiminde daha önce elde edilen seviyenin üstüne çıkılması, çeviri araçlarının gelişmesi, Google Now ve Amazon Alexa gibi dijital yardımcıların hayat bulması, sorulan sorulara yanıtlar verebilmesi ve sentetik veri üretimi gibi günümüzde hayatımızı kolaylaştıracak birçok alanda başarıları bulunmakta. Her geçen gün bu listeye yenileri eklenmeye devam ediyor. Bu konu hakkında bir örnek vererek neleri başarabildiğini birlikte görelim.
Örneğin girmiş olduğunuz anahtar kelimeler ile ilgili tweet üreten bir derin öğrenme modeli olduğunu söylesem tepkiniz ne olurdu?
Evet yanlış duymadınız. Siz bir anahtar kelime giriyorsunuz ve size onunla ilgili tweetler üretiyor. OpenAI tarafından geliştirilen dil modeli GPT-3 ile bunu gerçekleştirebilirsiniz. Sizler için birkaç derleme yaptım. Aşağıda görmüş olduğunuz tweetleri bir derin öğrenme modeli yazdı. Bu örnekler “deep learning” anahtar kelimesi kullanılarak hazırlanmıştır.
"İnsan beyni nasıl bu kadar verimli olabilir? Derin öğrenme, öğrenebileceğimiz ipuçları ortaya çıkardı."
“Derin öğrenme bir rönesanstır.”
"Sinir ağları en temel mimarilerden biridir. GPU'lar onları çalıştırabildiğinde, oldukça iyidirler."
"Derin Öğrenme, 21. yüzyılın ilk bilgisayar bilimi Nobel ödülü olabilir, ancak bu sonuncusu değil."
Sizce de dikkat çekici değil mi? Derin öğrenme hakkında bu bilgileri edindikten sonra biraz daha detaya inelim.
Yapay sinir ağı nedir?
Yapay sinir ağları, sinapslar ile birbirine bağlanan sinirlerden oluşan insan beyninin öğrenme kabiliyetinden esinlenilerek oluşturulmuştur ve ilk defa 1957 yılında Frank Rosenblatt tarafından tanımlanmıştır.
İnsan beyninin öğrenme yapısı referans alınarak makinelere karar verebilme, kendi kendine öğrenebilme ve değerlendirebilme gibi yetkinlikler kazandırılarak insan beyni modellenmeye çalışılmaktadır. Tıpkı yeni doğan bir bebeğe her şeyin sıfırdan öğretilmesi gibi makinelerin de öğrenmesi ve karar verebilmesi amaçlanmaktadır.
Yapay sinir ağları derin öğrenme algoritmalarının merkezinde yer almaktadır. Şimdi biraz insan sinir sistemi ve yapay sinir ağlarının yapılarını inceleyelim:
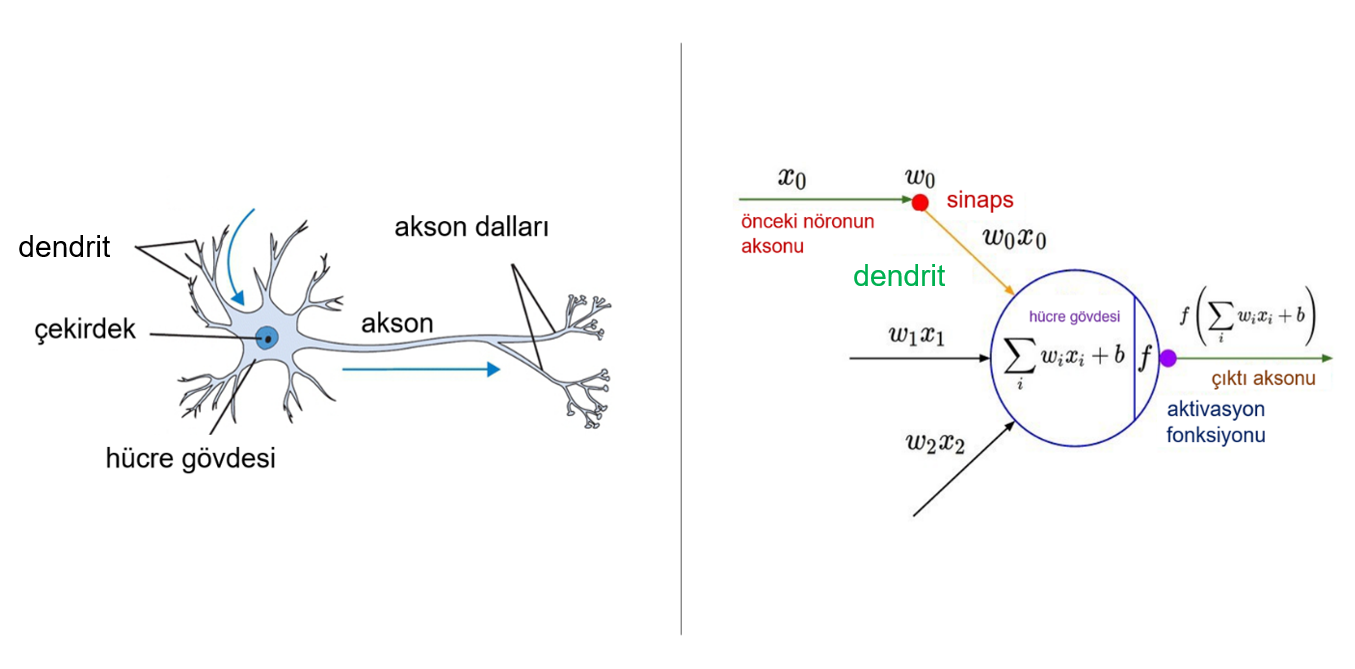
İnsan sinir sisteminin temel fonksiyonel birimi nöronlardır. Başlıca görevi bilgi transferidir. İnsan sinir sisteminde yaklaşık olarak 100 milyar nöron olduğu tahmin edilmektedir. Normal bir nöron 50 ila 250 bin kadar başka nöronla bağlantılıdır.
Nöronlar hücre gövdelerinden çıkan iki ana dal tipine sahiptir bunlar dendritler ve aksonlardır. Dendritler diğer sinir hücrelerinden gelen mesajları alırlar. Aksonlar hücre gövdesinden diğer hücrelere giden sinyalleri evdeki elektrik kabloları gibi hedef organa taşırlar. Birbirleriyle bağlantılı olarak nöronlar verimli ve yıldırım hızında iletişim sağlayabilirler.
Nöron uyarıldığında elektriksel uyarılar yoluyla diğer hücrelerle bu şekilde iletişim kurar. Böylece beyinden gelen bu uyarılar hareket etmemize, düşünmemize, hissetmemize ve iletişim kurmamıza olanak tanıyan bir iletişim ağı oluşturur.
“Beyindeki tek bir nöron, bugün bile hala anlamlandıramadığımız inanılmaz derecede karmaşık bir makinedir. Bir sinir ağındaki tek bir 'nöron', biyolojik bir nöronun karmaşıklığının çok küçük bir bölümünü yakalayan inanılmaz derecede basit bir matematiksel işlevdir.” Andrew NG
Tıpkı nöronlardaki bu iletim sistemi gibi yapay sinir ağlarında da benzer bir yapı bulunmaktadır. İnsandaki bir nöronun matematiksel modeli ise şu şekilde gösterilmektedir:
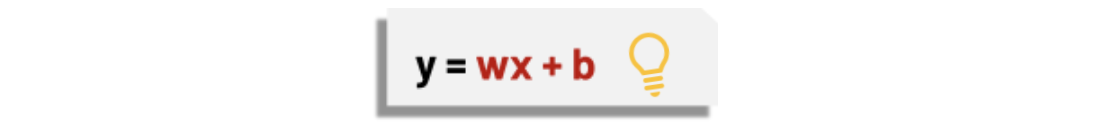
y = bağımlı değişken
x = bağımsız değişken
w = ağırlık parametresi
b = bias değeri
Yapay sinir ağları sığ sinir ağları ve derin sinir ağları olmak üzere en temelde iki yapıya ayrılmaktadır. Bir yapay sinir ağı giriş katmanı, gizli katman ve çıkış katmanı olmak üzere üç katmandan oluşmaktadır. Sığ sinir ağlarında giriş katmanı, bir gizli katman ve çıkış katmanı bulunmaktadır. Derin sinir ağlarında ise giriş katmanı, birden fazla gizli katman ve çıkış katmanı yer almaktadır.

Evrişimli sinir ağları (convolutional neural network - CNN) nedir?
Biz insanların en önemli duyularından birisi de görme duyusu. İnsanlar her şeyden çok gördüklerine güvenirler. Gezerken, nesneleri tanırken, insanların yüz ifadelerini yorumlarken ve daha birçok alanda görmeye dayalı işlemler gerçekleştiriyoruz. Bunu bir makineye yaptırmak isteseydik nasıl yapardık? Görüntü işleme alanında en iyi derin öğrenme algoritmalarından birisi olan evrişimli sinir ağları ile bunu gerçekleştirebiliriz.
Evrişimli sinir ağları temel olarak görüntüleri sınıflandırmak ve nesne tanıma için kullanılmaktadır. Bir girdi görüntüsünü alıp, görüntüdeki çeşitli görünüşleri veya nesneleri birbirinden ayırabilen derin öğrenme ağ çeşididir.
Evrişimli sinir ağlarının ilk uygulaması, 1989 yılında Yann LeCun tarafından evrişimli sinir ağları ile geriye yayılım algoritması birleştirilerek el yazısı ile yazılmış rakamların tanınması üzerine başarılı bir şekilde gerçekleştirilmiştir. LeCun bu ağın ismine LeNet adını vermiştir. Yapılan bu çalışma ABD Posta Servisi tarafından posta kodlarının zarflardan okunması işleminin otomatikleştirilmesi için kullanılmıştır.

Evrişimli sinir ağının yapısının dünyaca duyulmasını sağlayan en önemli olaylardan biri ise 2012 yılında düzenlenen ImageNet yarışması olmuştur.
Evrişimli sinir ağları hakkında bilgi edindikten sonra biraz daha derine inelim ve evrişimli sinir ağlarının katmanlarını inceleyelim.
Evrişimli sinir ağı katmanları
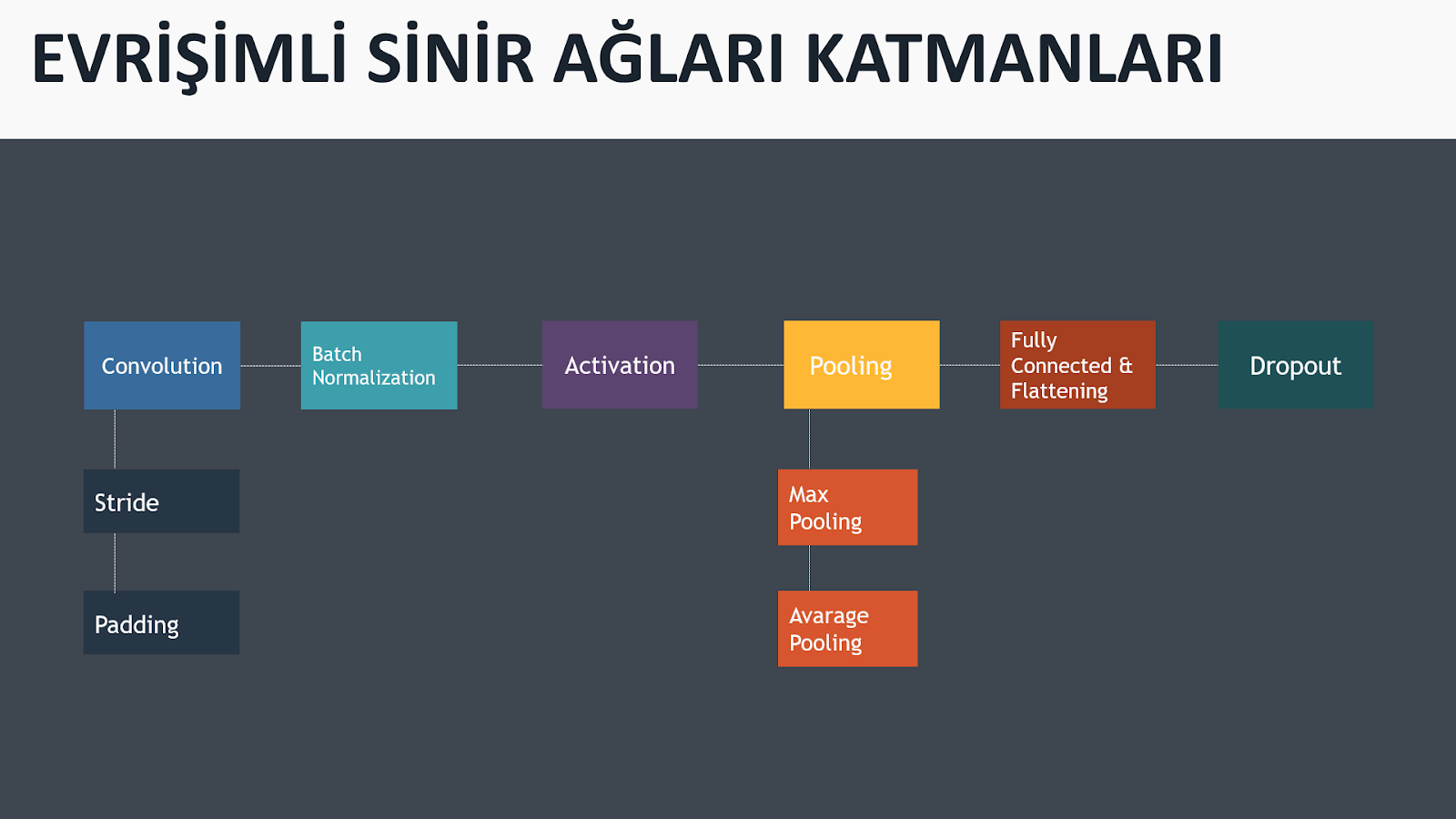
Evrişimli sinir ağlarında görüntüler katmanlardan geçirilerek öğrenme işlemi gerçekleştirilmektedir. Temel anlamda bir evrişimli sinir ağı mimarisinde şu katmanlar yer almaktadır:
- Evrişim katmanı (convolution layer)
- Aktivasyon katmanı (activation layer)
- Pooling katmanı (pooling layer)
- Fully connected & flattening katmanları
Bu katmanlara ek olarak batch normalization ve dropout katmanları da yer almaktadır. Bu katmanlar kurmuş olduğunuz modelin hız, performans ve overfitting gibi durumlarını etkileyecek katmanlardır.
Evrişim katmanı (convolution layer)
Bu katmanda giriş görüntüsü üzerinden öznitelik (kenar bulma, köşe bulma, görüntü üzerinde nesne bulma) çıkarımı yapılmaktadır. Bu çıkarım filtreler aracılığı ile gerçekleştirilmektedir. Bilgisayarlara bir görüntüyü tanıtıyorken, bilgisayarlar her pikselin matematiksel karşılığını hafızasında tutarak görüntüyü tanımlamaktadır. Görüntüler genellikle matrisler şeklinde temsil edilmektedir. Matrislerin içerisinde yer alan değerler ise görüntüye ait piksel değerleridir. Evrişimli sinir ağlarında görüntüler matrisler ile temsil edilmekte ve bunlar üzerinden işlemler gerçekleştirilmektedir.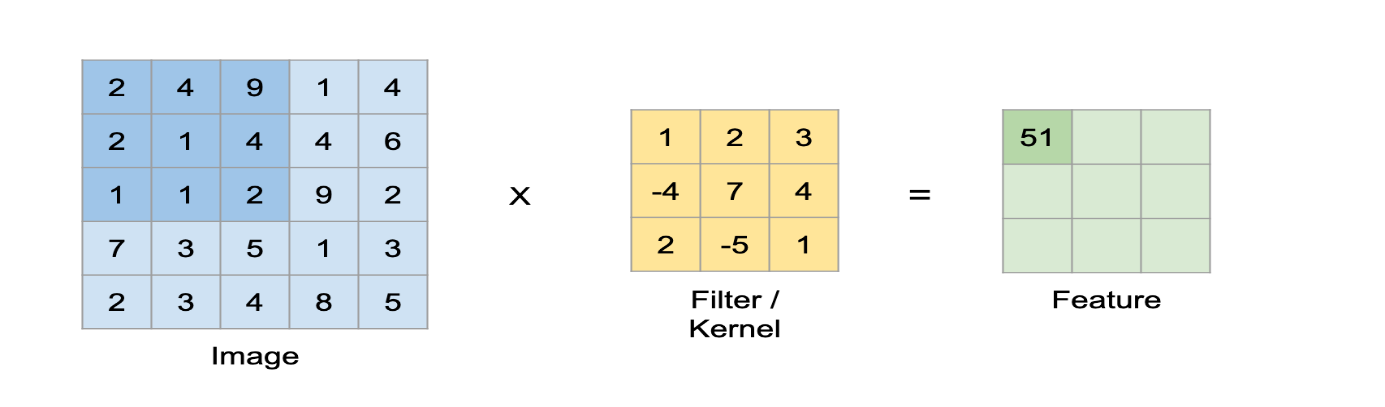 Örnek bir evrişim işlemini ele alalım. Elimizde 5 x 5 boyutlarında bir görüntü ve 3 x 3 boyutlarında bir filtre olduğunu varsayalım ve bu görüntü üzerinde evrişim işlemi uygulamak istediğimizi düşünelim.
Örnek bir evrişim işlemini ele alalım. Elimizde 5 x 5 boyutlarında bir görüntü ve 3 x 3 boyutlarında bir filtre olduğunu varsayalım ve bu görüntü üzerinde evrişim işlemi uygulamak istediğimizi düşünelim.
İlk olarak çıkış matrisinin boyutunun hesaplanılması gerekmektedir.
Çıkış Matrisi Boyutu Hesaplama Formülü:
Giriş görüntüsü = (n x n), Filtre = (f x f) ile temsil edilmektedir.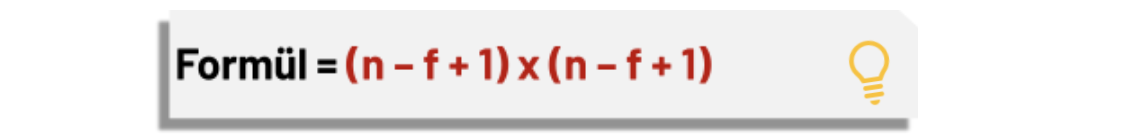
Formül yardımıyla çıkış matrisinin boyutu hesaplanmaktadır. Örneğimizi ele alacak olursak formülde yerine yazdığımızda,
Çıkış matrisi boyutu:
(5 – 3 + 1) x (5 – 3 + 1) = 3 x 3 boyutunda bir çıkış matrisi elde edilir.
Çıkış matrisi boyutu hesaplandıktan sonra, filtre görüntünün sol üst köşesine konumlandırılır ve iki matris (görüntü ve filtre) arasındaki eşleşen indisler birbirleri ile çarpılarak çıkan sonuçlar toplanır ve elde edilen bu değer çıkış matrisinin ilk değerini oluşturmaktadır. Bir sonraki adımda filtre bir piksel sağa kaydırılarak bu işlemler tekrarlanır ve çıkış matrisi elemanı hesaplanır. Bu şekilde görüntü üzerinde filtre gezdirilerek çıkış matrisi oluşturulmaktadır.
Oluşan çıkış matrisi bize ne anlatıyor?
Çıkış matrisinin bazen “Özellik haritası (Feature Map)” olarak da adlandırıldığını görebilirsiniz. Filtreyi görüntü üzerinde hareket ettirerek ve basit matris çarpımı kullanılarak, görüntüdeki özellikleri tespit etme işlemi gerçekleştirilmektedir. Genellikle, birden çok özelliği tespit etmek için birden fazla filtre kullanılır, sonuç olarak bir evrişimli sinir ağında birden fazla evrişim katmanı bulunabilir.
Adım Kaydırma
Evrişim işlemini anlattığımız kısımda ele aldığımız örnekte filtre görüntü üzerinde bir piksel kaydırılarak çıktı matrisi oluşturulmaktaydı ancak filtreyi görüntü üzerinde kaç piksel adımla kaydıracağımızı belirleyebiliriz. Bu işleme adım kaydırma (stride) adı verilmektedir. Adım kaydırma değerini değiştirdiğimizde çıkış matrisi de buna bağlı olarak değişecektir.
Stride = 1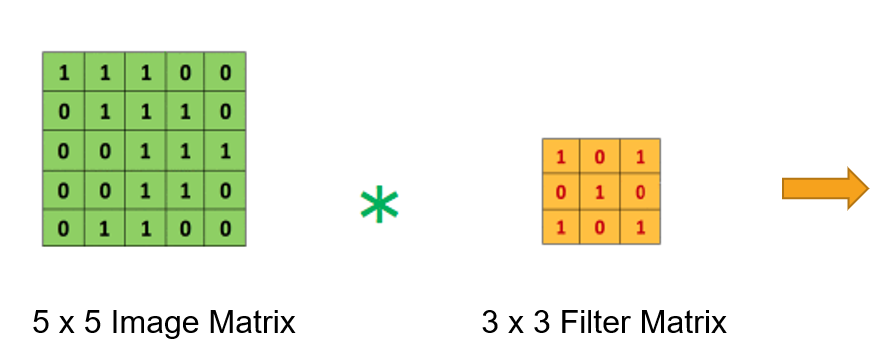 Stride = 1 olduğu işlemlerde daha hassas çıktılar elde edilirken iki ya da üçer piksel adım kaydırma işlemi sonrasında daha düşük hassasiyetli çıkış matrisi elde edilebilir. Bunun sebebi ise bilgi kaybı olmaktadır. Buna bağlı olarak çıkış matrisinin boyutu da küçülecektir.
Stride = 1 olduğu işlemlerde daha hassas çıktılar elde edilirken iki ya da üçer piksel adım kaydırma işlemi sonrasında daha düşük hassasiyetli çıkış matrisi elde edilebilir. Bunun sebebi ise bilgi kaybı olmaktadır. Buna bağlı olarak çıkış matrisinin boyutu da küçülecektir.
Stride = 2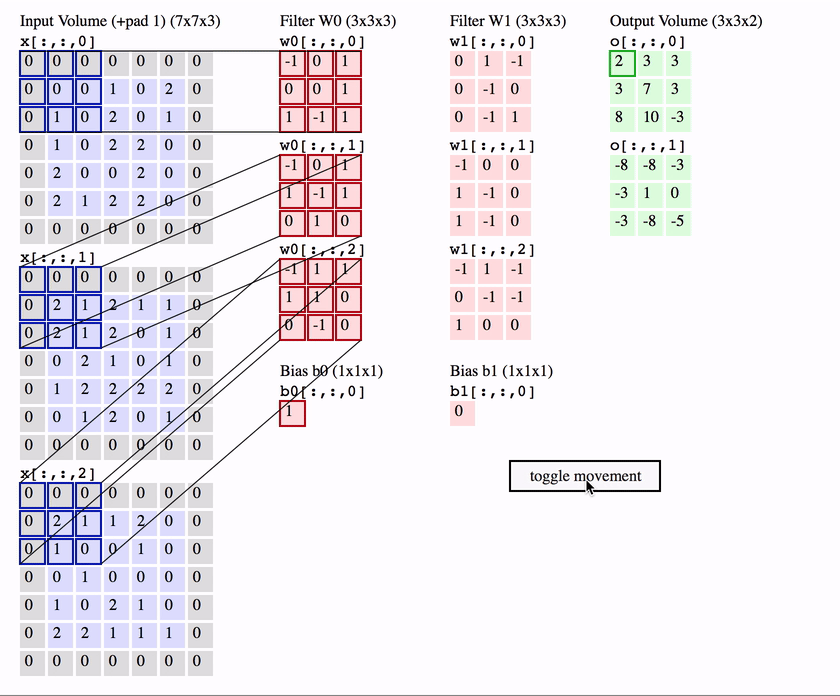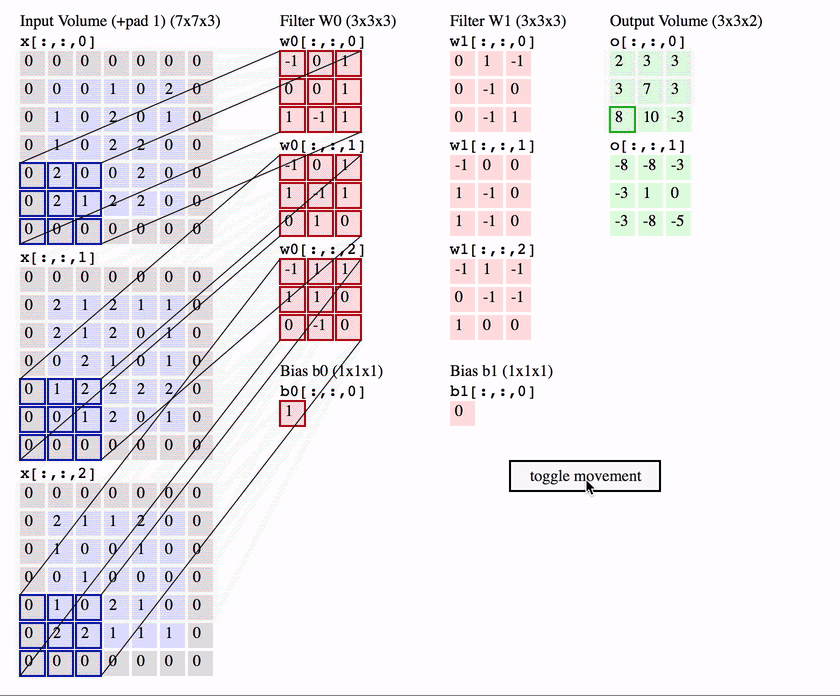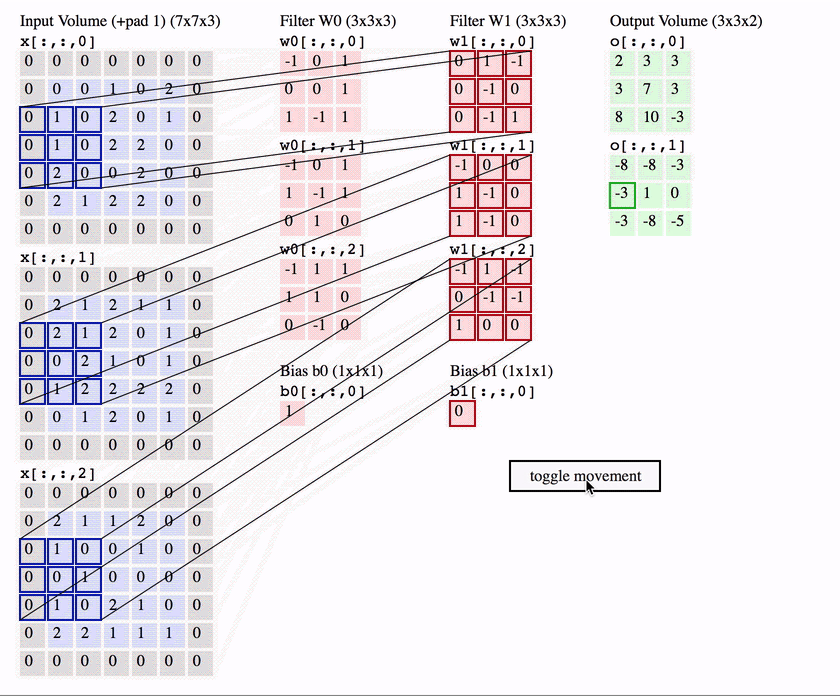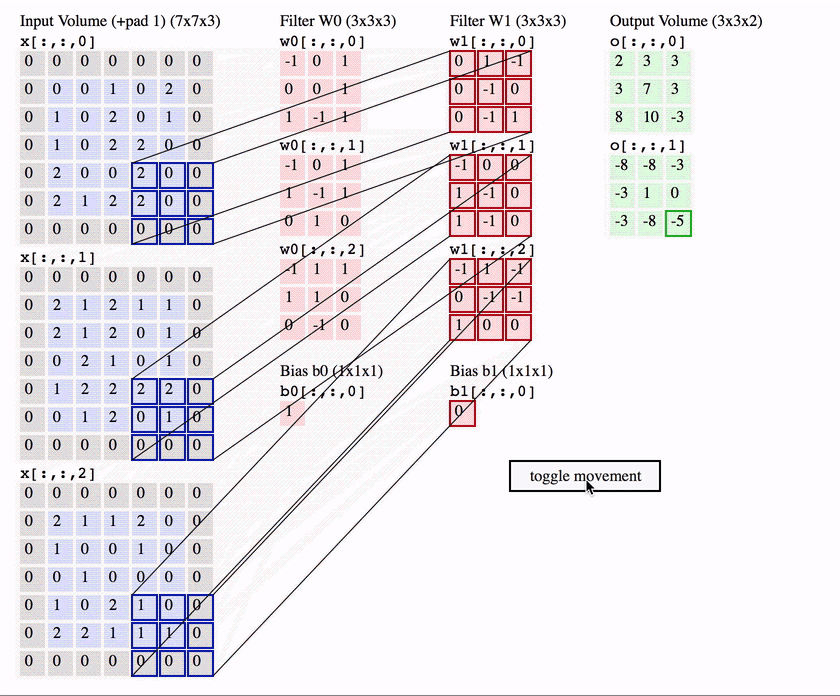
Yukarıdaki görselde yer alan örneği incelediğimizde normal şartlarda çıkış matrisi boyutumuz 5 x 5 olması gerekir ancak çıkış matrisi incelendiğinde 3 x 3 boyutlarında olduğu gözlemlenmektedir. Adım kaydırma (stride) değeri birden farklı olduğu durumlarda çıkış matrisinin boyutunun hesaplanan formülünde de değişiklikler meydana gelmektedir.
Bu durumda burada yer alan formüle göre yukarıdaki örnek ele alınıldığında çıkış matrisi 3 x 3 boyutlarında olduğu hesaplanmıştır.
Neden adım kaydırma işlemi yapılmaktadır ?
Filtrenin görüntüye ait olan matris üzerinde gezme işlemini daha kısa sürede tamamlaması için tercih edilmektedir. Fakat hassasiyeti daha düşük çıkış matrisi elde edilmektedir. Evrişim işlemi sonrasında giriş matrisi boyutu ile çıkış matrisi arasındaki boyut farkı dikkatinizi çekti mi? Bu problemin önüne geçebilmek için piksel ekleme işlemini ele alacağız.
Piksel ekleme (padding)
Evrişim işlemi sonrasında giriş matrisi boyutu ile çıkış matrisi boyutu birbirine eşit olmadığı gözlemlenmiştir. Bu problemin önüne geçebilmek için piksel ekleme işlemi gerçekleştirilerek giriş matrisi boyutu ile çıkış matrisi boyutu arasındaki oluşan boyut farkı ortadan kaldırılmaktadır.
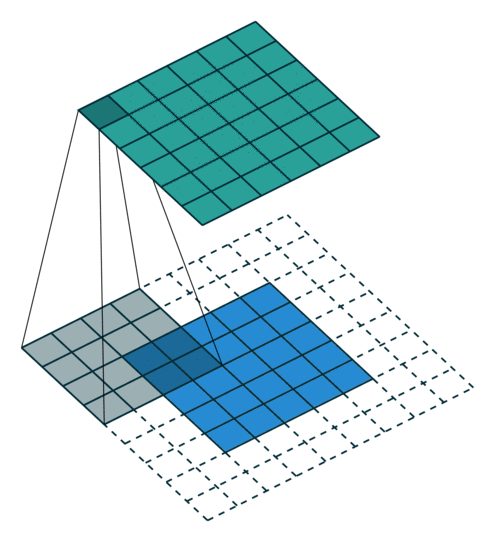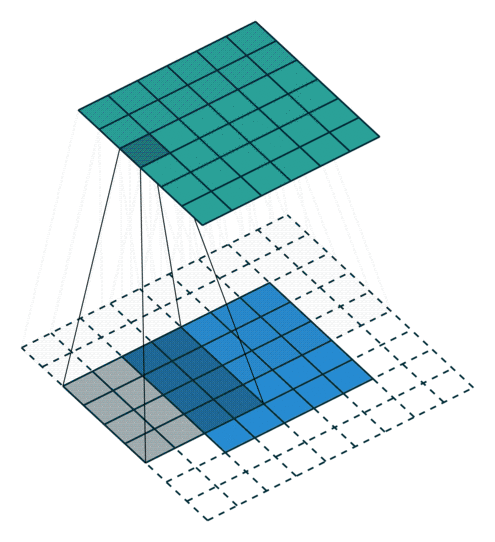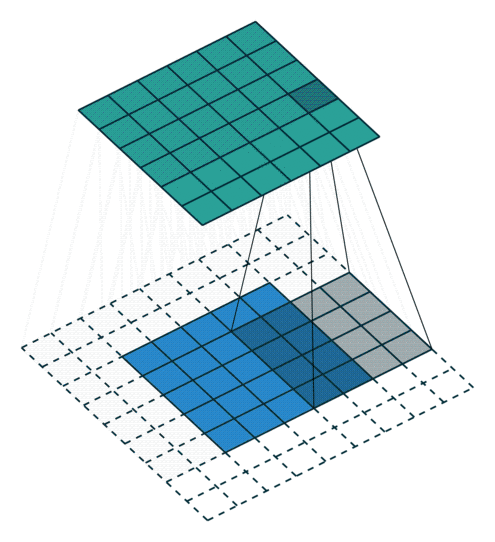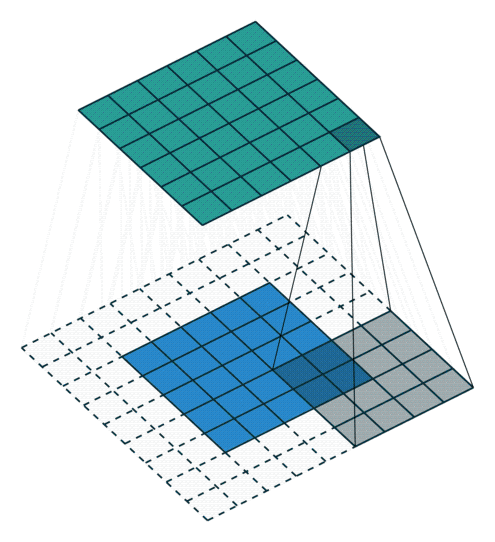
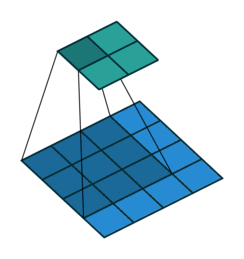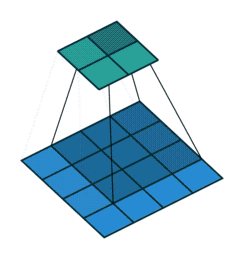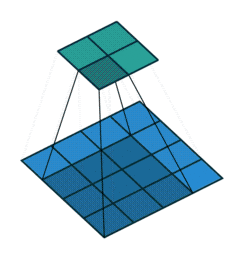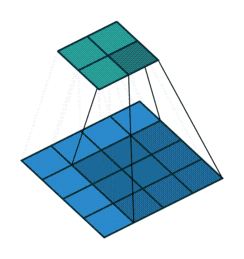
Piksel ekleme işlemi nasıl gerçekleşmektedir?
1) Giriş görüntüsüne ait matrisin çevresine sıfırlardan oluşan pikseller eklenerek piksel ekleme işlemi gerçekleştirilebilmektedir.
2) Bir diğer yöntem ise giriş görüntüsü matrisinin elemanlarından oluşan piksel değerleri kopyalanarak piksel ekleme yapılabilmektedir.
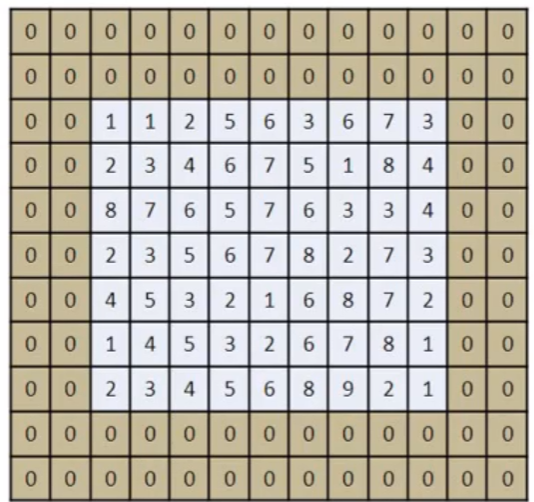
Giriş matrisi ile çıkış matrisi arasındaki bu boyut farkını korumak için kaç piksel ekleme işlemi gerçekleştirilmesi gerekmektedir?
Bir örnek ele alalım 7 x 7 boyutlarında bir giriş görüntüsü ve 5 x 5 boyutlarında bir filtre elimizde olduğunu düşünelim. İlk olarak piksel ekleme olmadan çıkış matrisi boyutunu hesapladığımızda;
Çıkış Matrisi Boyutu = (n – f + 1) x (n – f + 1) = 3 x 3 boyutunda bir çıkış matrisi elde edilmektedir. Gözlemleyeceğiniz üzere giriş matrisi ile çıkış matrisi arasındaki boyut farkı bulunmaktadır.
Piksel ekleme işlemi gerçekleştirilirse;
Padding = (f - 1) / 2 = (5 - 1) / 2 = 2 piksel ekleme işlemi gerçekleştirilecektir.
Çıkış Matrisi Boyutu = (n + 2p – f + 1) x (n + 2p – f + 1) = 7 x 7 boyutunda çıkış matrisi elde edilmektedir. Bu durumda giriş matrisi ile çıkış matrisi arasındaki boyut farkı ortadan kalkmıştır.
Hangi piksel ekleme adımı kullanılmalı ve neden?
Bir evrişim işlemi gerçekleştiriyor olduğumuzu düşünelim ve sıfırlardan oluşan pikseller ekleyerek piksel ekleme yaptığımızı varsayalım. Bu durumda evrişim işlemi gerçekleşiyorken filtre sıfırların olduğu bölge üzerinde çıkış matrisini oluşturuyorken düşük değerler alacağından çıkış matrisinde aykırılıklara sebep olacaktır. Sonuç olarak çıkış matrisinde giriş matrisine göre birbirinden aykırı değerler oluşacaktır. Buradaki avantaj ise ekstra işlem yükü olmaması ve hız performans anlamında daha hızlı sonuçlar üretmesidir.
Eğer diğer yöntem olan içteki piksellerin değeri kopyalanarak piksel ekleme işlemi gerçekleştirilirse bu eklenen pikseller adeta giriş görüntüsüne aitmiş gibi davrandığından dolayı evrişim işlemi sonrasında görüntüde aykırılıklar oluşmayacaktır. Bu da çıkış matrisinde hassas çıktılar elde edilmesini sağlamaktadır. Buradaki dezavantaj ise ekstra işlem yükü artmasıdır.
- Aktivasyon fonksiyonu katmanı (activation layer): Yapay sinir ağlarına doğrusal olmayan gerçek dünya özelliklerini tanıtmak için aktivasyon fonksiyonlarına ihtiyaç duyulmaktadır. Relu, tanh, sigmoid gibi aktivasyon fonksiyonları yaygın olarak kullanılmaktadır. Çıkış katmanındaki aktivasyon fonksiyonunuz ise probleminize göre farklılık gösterebilmektedir. Eğer bir ikili sınıflandırma modeli gerçekleştiriyorsanız yani bir görüntü verdiğinizde kedi mi köpek mi olduğunu ayırt etmesini istiyorsanız bu durumda genellikle çıkış katmanı aktivasyon fonksiyonunuz sigmoid olmalıdır. Çoklu sınıflandırma problemlerinde ise genellikle çıkış katmanında softmax aktivasyon fonksiyonu kullanılmaktadır.
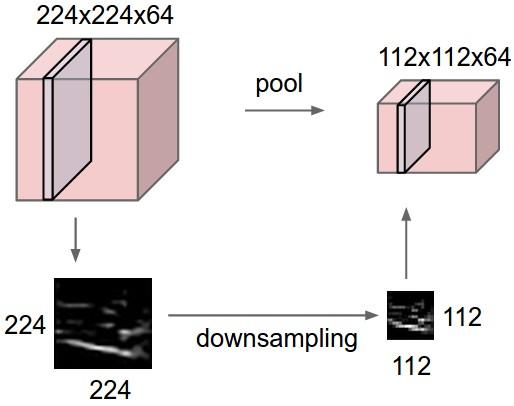
- Havuzlama katmanı (pooling layer): En temelde görüntünün özelliklerini kaybetmeden boyutunun azaltılması işlemi gerçekleştirilmektedir. Karşınıza down sampling (boyut azaltma) olarak da çıkabilmektedir. Bu katmanda herhangi bir öğrenme işlemi yapılmamaktadır. Evrişim katmanı sonrasında kullanılan bir katmandır. Yapılan işlem giriş matrisinin kanal sayısını sabit tutarak yükseklik ve genişlik bilgisini azaltmaktır. Bu işlemin sağlamış olduğu katkı ise hesaplama karmaşıklığını azaltmasıdır. En yaygın iki havuzlama türü bulunmaktadır.
1. Ortalama havuzlama (avarage pooling): Evrişim işleminden sonra oluşan çıkış matrisi üzerinde filtrenin gezmiş olduğu noktaların ortalama değeri alınarak çıkış matrisi oluşturulmaktadır. Aşağıdaki görüntüye dikkat ederseniz 4 x 4 boyutlu bir matris 2 x 2 boyutlarına düşürülmüştür. Kısaca boyut azalması meydana gelmiştir.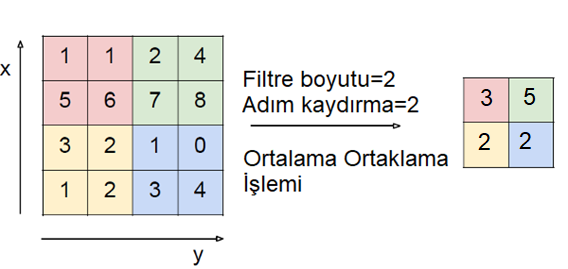
2. Maksimum havuzlama (maximum pooling): Evrişim işleminden sonra oluşan çıktı matrisi üzerinde filtrenin gezmiş olduğu noktaların maksimum değeri alınarak çıkış matrisi oluşturulmaktadır. Aşağıdaki görüntüye dikkat ederseniz 4 x 4 boyutlu bir matris 2 x 2 boyutlarına düşürülmüştür. Kısaca boyut azalması meydana gelmiştir.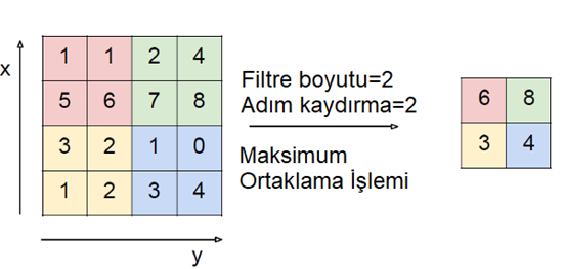
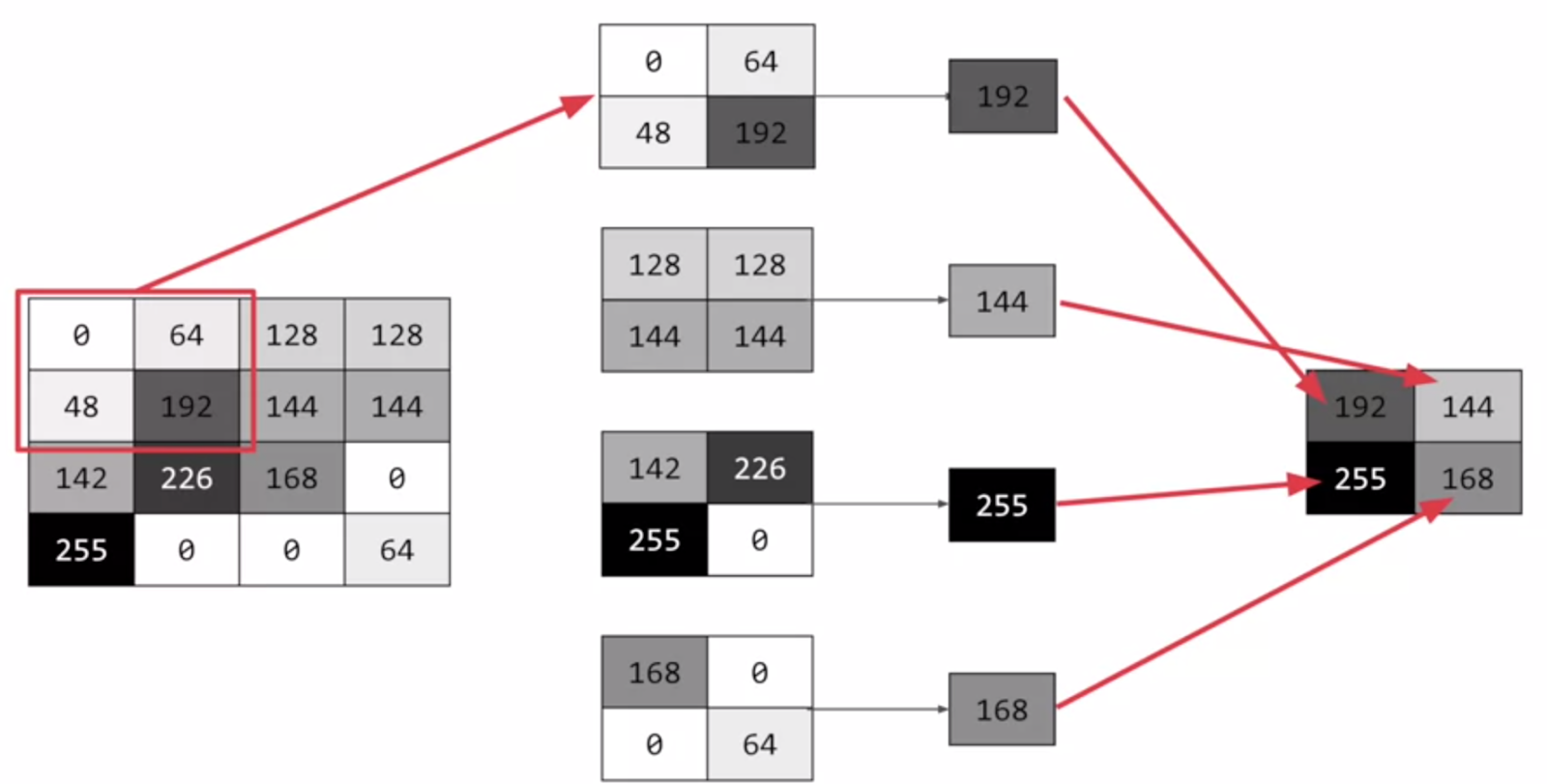
Hangi havuzlama yöntemi daha iyidir? Bu, probleme göre değişmektedir. Ortalama havuzlama ve maksimum havuzlama en sık kullanılan yöntemlerdir. Amacımız boyut azaltmaktır. Havuzlama işlemi sayesinde görüntünün boyutu azalmakta ve işlem yükü düşürülmektedir. Aynı zamanda çok daha fazla resmi bilgisayara öğretme imkanı sağlamaktadır.
Fully connected & flattening katmanları
Flattening katmanı: Bu aşamaya kadar görüntü üzerindeki feature learning (öznitelik çıkarımı-öğrenimi) işlemini gerçekleştirdik. Feature learning işleminde saptanan özniteliklere göre görüntünün sınıflandırma işlemi gerçekleştirilmelidir fakat bir problem söz konusu. Görüntüler hala matrisler şeklinde. Genel olarak sinir ağları, giriş verilerini tek boyutlu bir diziden almaktadır. Bu problemin çözümü ise flattening katmanıdır. Bu katman feature learning işleminden gelen matris düzeyindeki verileri tek boyutlu diziye çevirme işlemi gerçekleştirmektedir. 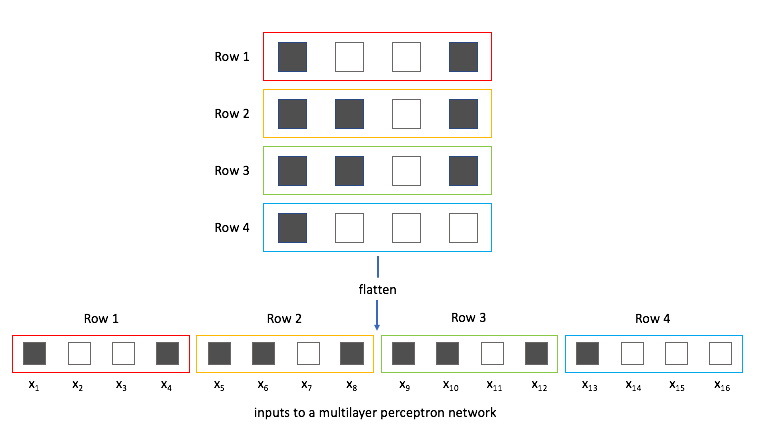
Fully connected katmanı: Evrişimli sinir ağının son ve en önemli katmanıdır. Verileri flattening katmanından alır ve sinir ağı yoluyla öğrenme işlemini gerçekleştirir.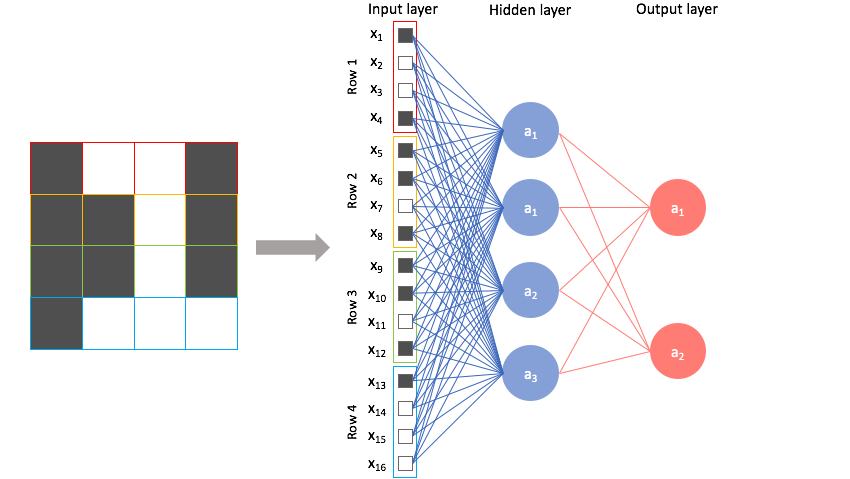
Batch normalization ve dropout katmanları
Bu katmanlar kurmuş olduğunuz modelin hız, performans ve overfitting gibi durumlarını etkileyecek katmanlardır.
Batch normalization katmanı: Normalleştirme verileri standartlaştırmak için kullanılan bir ön işleme tekniğidir. Batch normalization ise bir sinir ağının katmanları arasında yapılan bir normallleştirme işlemidir. Tüm veri üzerinde değil de mini gruplar halinde normalleştirme işlemi yapılmaktadır. Eğitimi hızlandırmaya ve daha yüksek öğrenme oranlarını kullanmaya olanak sağlayarak öğrenmeyi kolaylaştırılır. Genellikle evrişim katmanı ile aktivasyon fonksiyonu katmanı arasında yer almaktadır.
Dropout katmanı: Seyreltme katmanı olarak da karşınıza çıkabilir. Temel amacı overfittingi engellemektir. Sinir ağı içerisinde yer alan bazı nöronların rastgele olarak ortadan kaldırılmasında seyreltme (dropout) katmanı kullanılmaktadır. Sinir ağında nöronların yüzde kaçı ortadan kaldırılacağı kullanıcı tarafından belirlenmektedir. Böylece ağın overfitting olması önlenerek performansın artması sağlanmaktadır. Basitliği ve etkili olması nedeniyle, günümüzde çeşitli mimarilerde, genellikle fully connected katmanından sonra dropout katmanı kullanılmaktadır.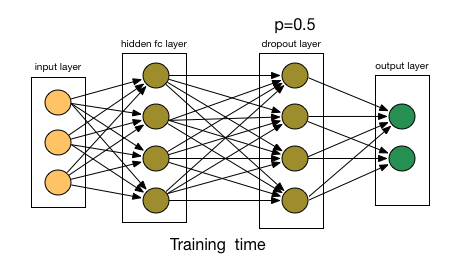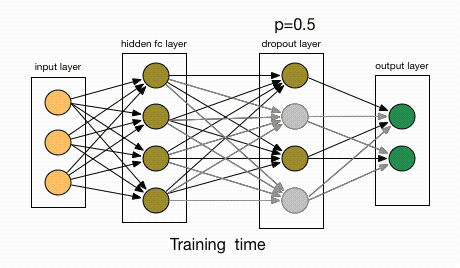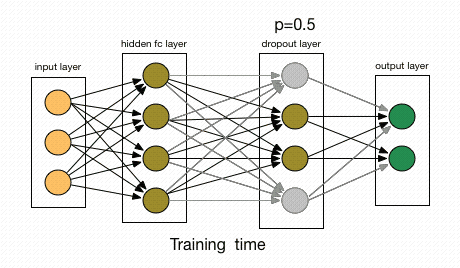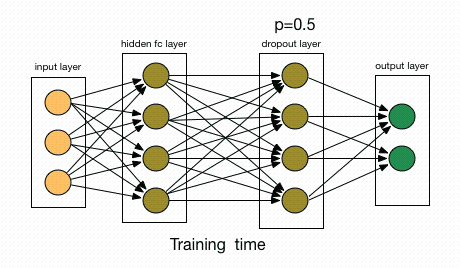
Kaynaklar
