Eğitim Setimiz Test Setimizi Temsil Edebiliyor mu? Adversarial Validation Yöntemi
Her alanda bazı kavramlar vardır ki o alanın alfabesidir, temelidir, olmazsa olmazıdır. Veri bilimi dünyasının kapılarını aralayan herkesin karşısına çıkan ve bu dünyanın da alfabesi olan bazı kavramlar mevcuttur. Örneğin yalnızca "veri seti" kelimesinin ne anlama geldiğini bilmek yetmez, eğitim ve test setlerini, bunların nasıl kullanılacağını bilmek de oldukça önem teşkil eder. Açıktır ki, eğitim seti modelimizi kurduğumuz veri seti iken test seti modelin eğitim sırasında hiç karşılaşmadığı ve modelin başarısının ölçülmesinde kullanılan veri setidir. Bu noktada bir de göz ardı edilmemesi gereken validasyon kavramı bizi karşılar. Bu yazımızda öncelikle validasyonun ne olduğuna ve kullanılan yaygın validasyon yöntemlerine değindikten sonra adversarial validation yönteminin ne olduğunu ve nasıl kullanıldığını inceleyeceğiz.
Validasyonun tanımı ve kullanım amacı
Elimizde eğitim ve test setleri olunca aklımıza haliyle bir soru geliyor: Acaba eğitim setimiz, test setimizi gerçekten de temsil edebiliyor mu? Belki de elimizde öyle bir eğitim seti var ki test setinden tamamen bağımsız.
Validasyon, modellerin ürettiği sonuçların doğru değerlendirilmesi çalışmasıdır. Modelin eğitim işlemini gerçekleştirildikten sonra test setimizle test edilmeden önce, validasyon setimiz üzerinden hiperparametre ayarlarıyla geliştirilmeye çalışılması gerekmektedir. Yani aslında validasyon, model başarısının sınandığı bir aşama değildir.
Validasyon için yaygın olarak kullanılan yöntemleri aşağıdaki gibi sıralayabiliriz:
- Holdout (sınama seti yaklaşımı)
- K-fold cross validation (k-katlı çapraz doğrulama)
- Leave-one-out
- Bootstrap (örnekleme yöntemi)
Adversarial validation kullanım amacı
Bu noktanın biraz daha derinlerine gidersek aklımıza şöyle sorular gelebilir: Acaba eğitim setimiz, test setimizi gerçekten de temsil edebiliyor mu? Eğitim setimizin başarısını testle ölçmeden önce optimize etmekten bahsediyoruz ama ya test setimizde eğitim setiyle açıklayamayacağımız değerler varsa? Yani yukarıdaki validasyon yöntemlerini daha geçerli kılmanın bir yolu yok mu?
İşte bu soruların cevabı olarak yardımımıza adversarial validation yetişiyor. Genel fikir, özellik dağılımı açısından eğitim ve testler arasındaki benzerlik derecesini kontrol etmektir. Eğer dağılımlar benzerse olağan validasyon teknikleri işe yarayacaktır fakat eğitim setindeki özellik dağılımı test setinden ayrılıyorsa, validasyon tekniklerimiz yanıltıcı sonuç verecektir. Özetle, eğitim ve test setlerimizin gerçekten de benzer olup olmadıklarını gözlemleyebileceğimiz basit ve etkili bir yöntemdir.
Adversarial validasyonun faydaları
- Overfitting (aşırı öğrenme) ve underfitting (az öğrenme) durumlarını engeller.
- Veriyi daha iyi analiz etmemizi sağlar.
- Model başarısını daha doğru değerlendirmemize olanak tanır.
Adversarial validasyonun uygulama adımları
- Kendimiz sadece 0 ve 1'lerden oluşan bir label yaratılır. Eğitim 0, test ise 1 değerinden (ya da tam tersi olacak şekilde eğitim 1, test 0 değerinden) oluşturulur.
- Hedef değişken dışarıda bırakılır.
- Test ve eğitim setleri birleştirilir.
- Bir "binary classification", yani sınıflandırma algoritması seçilip bir model kurulur ve modelin, ürettiğimiz label’ı öğrenmesi beklenir.
- Son olarak ROC-AUC skoruna bakılır.
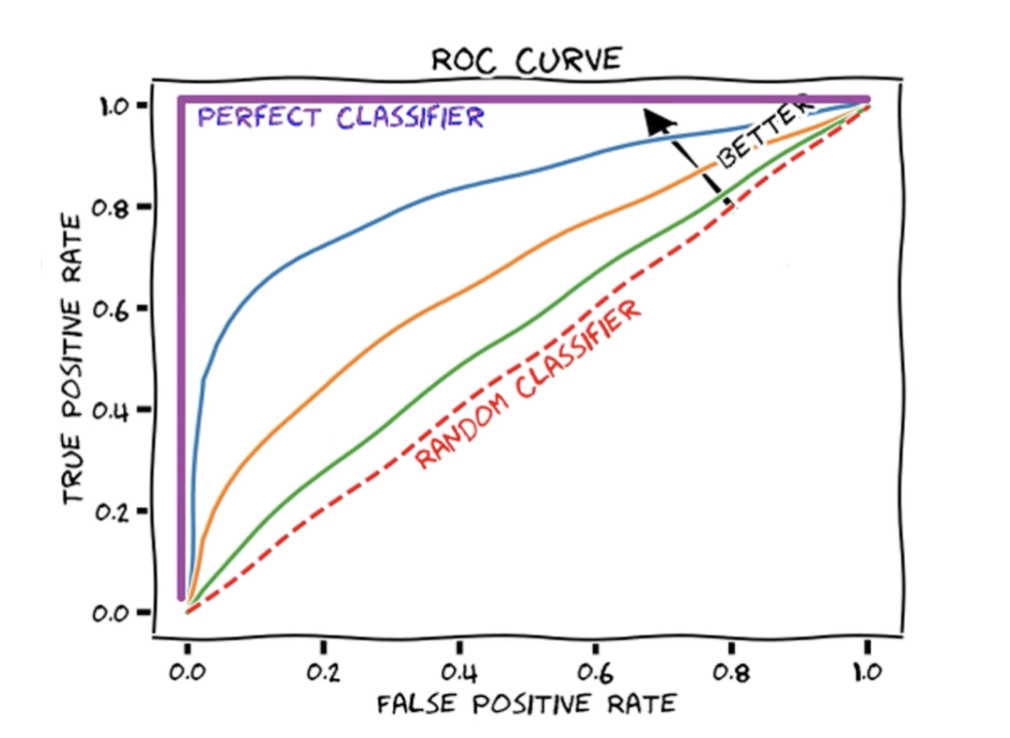
ROC-AUC skoru aslında bir sınıflandırma başarı metriğidir. Bu metrik der ki “eğer hiçbir model kurmasak ve rastgele 1-0 atamaları yapsak elde edeceğimiz başarı kırmızı çizgidir” ve temel karşılaştırma noktası da budur. Bundan yola çıkarak adversarial validasyon metodu ROC-AUC skorunun yaklaşık 0.5 civarında olmasını bekler ve bu skoru elde ettiğimiz takdirde aslında bize modelin eğitim ve test setleri arasında ayrım olmadığını, yani birbirlerine benzediğini söyler. Bu puandan önemli ölçüde daha yüksek bir puanın alınması durumunda, eğitim ve test özellikleri arasında önemli farklılıklar olacaktır. Bu farklılıklar, feature’lar düşürülerek veya dönüştürülerek düzeltilmelidir.
Yöntemin uygulanışı
Kullanıma örnek olması adına 2 farklı veri setini inceleyeceğiz. İlk uygulama bilindik veri setlerinden birisi olan "Titanic" ile ikincisi ise “Data Scientist Job Salaries” veri seti üzerinden gerçekleştirilecek.
Örnekleri uygularken asıl amaç yöntemin nasıl uygulanacağını göstermek olduğundan veri setlerinin detaylı analizlerine değinmeyeceğiz. Elbette ki pratikte detaylı analizlerimizden sonra adversarial validasyon yöntemini uygulamak daha yararlı olacaktır.
Öncelikle kullanacağımız kütüphaneler import edilir:

İlk kullanacağımız veri seti olan “Titanic” ile başlayalım. 1912’de buz dağına çarpması sonucu batan Titanic isimli geminin yolcu bilgilerini içeren veri setimiz, en bilindik veri setlerinden birisidir. Eğitim ve test setlerimizi aşağıdaki gibi gözükmektedir:
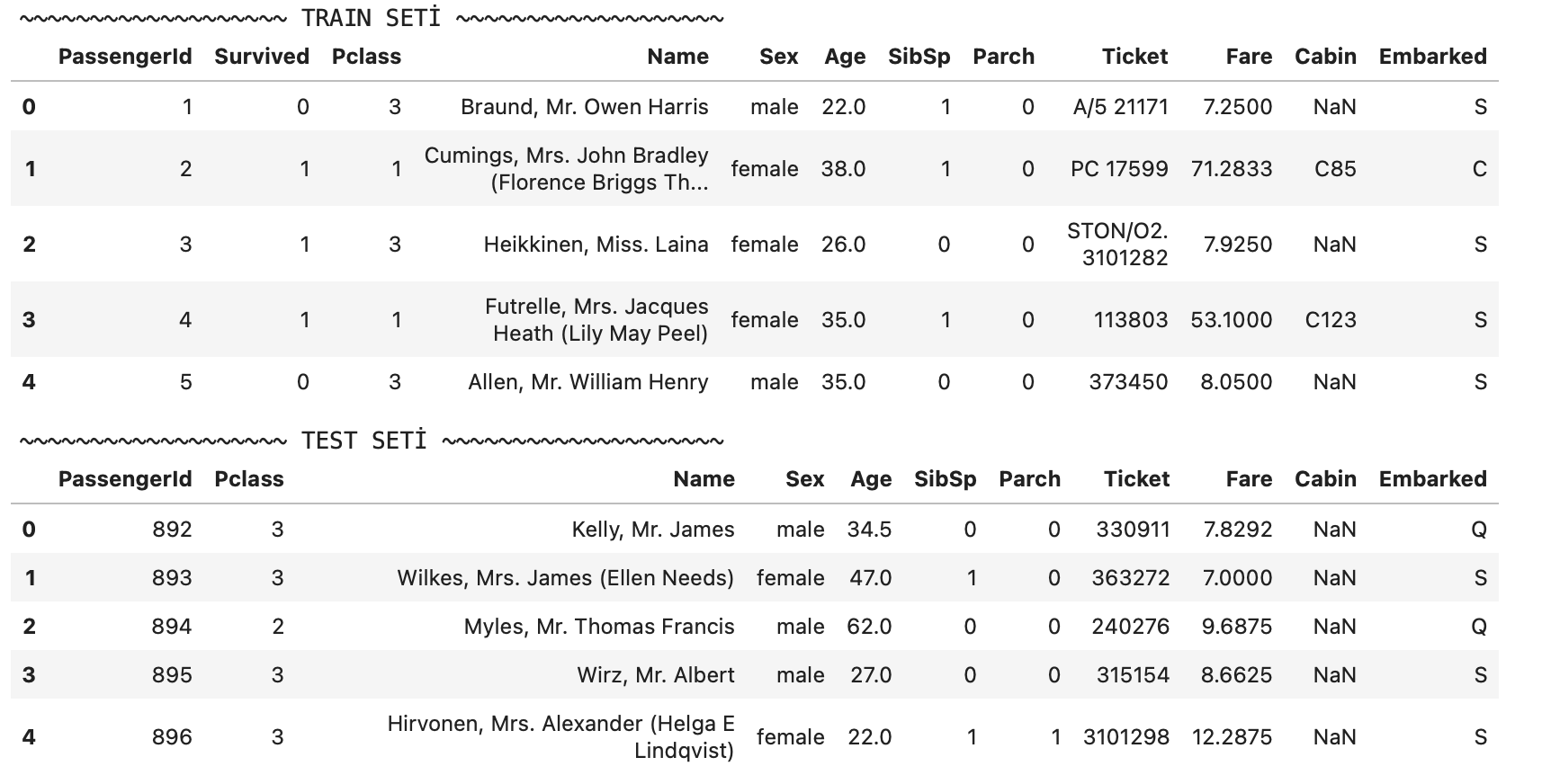
Veri setlerimizi aldıktan sonra metodun uygulanış aşamalarını tek tek uygulayalım.
- Target değişkenimizi çıkaralım:

2. Adversarial validation yöntemi için eğitim ve test setlerine label atamalarımızı yapalım: Yukarıda da belirttiğimiz gibi hangisine 0, hangisine 1 verdiğimizin burada bir önemi bulunmuyor.

3. Veri setlerimizi birleştirelim:

4. Modelimizi kuralım: Buradaki önemli nokta, modeli kurarken bir “binary classification” yani ikili sınıflandırma algoritmalarından birinin seçilmesi gerektiğidir. Bu örnek için ben LightGBM’i seçtim fakat başka bir algoritma da kullanılabilir. LightGBM algoritması hakkında detaylı açıklamalara erişebileceğiniz yazımız:

5. ROC-AUC skorumuza bakalım:
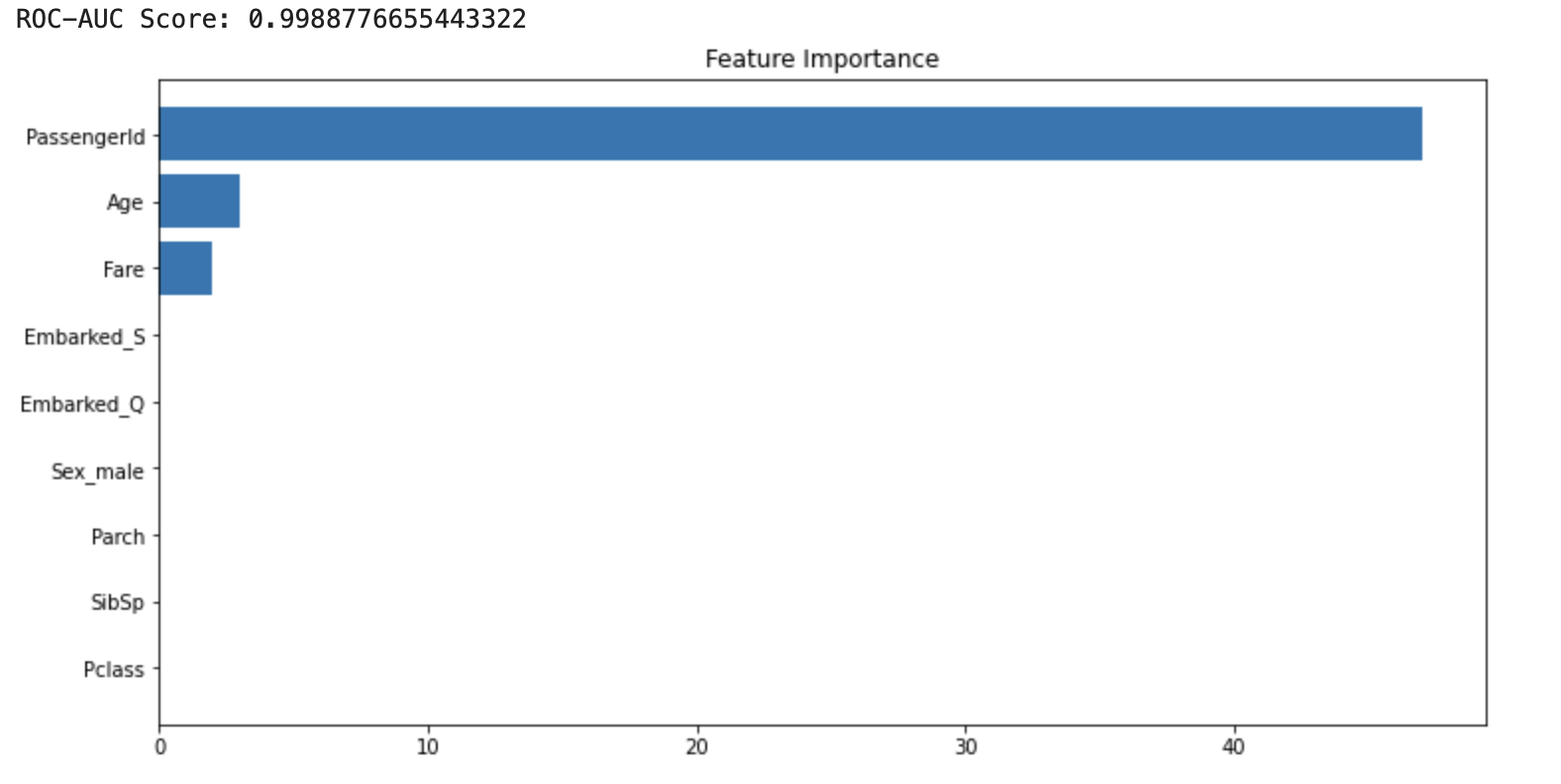
PassengerId sütunu eğitim ve test setlerinin ciddi bir şekilde benzerliğini bozan bir özellik. Çalışmamıza bu şekilde devam etmemiz durumunda, kullanacağımız validasyon yöntemleri de yanıltıcı olacaktır. Dolayısıyla bu değişkeni veri setinden düşürüp son duruma tekrar bakalım.
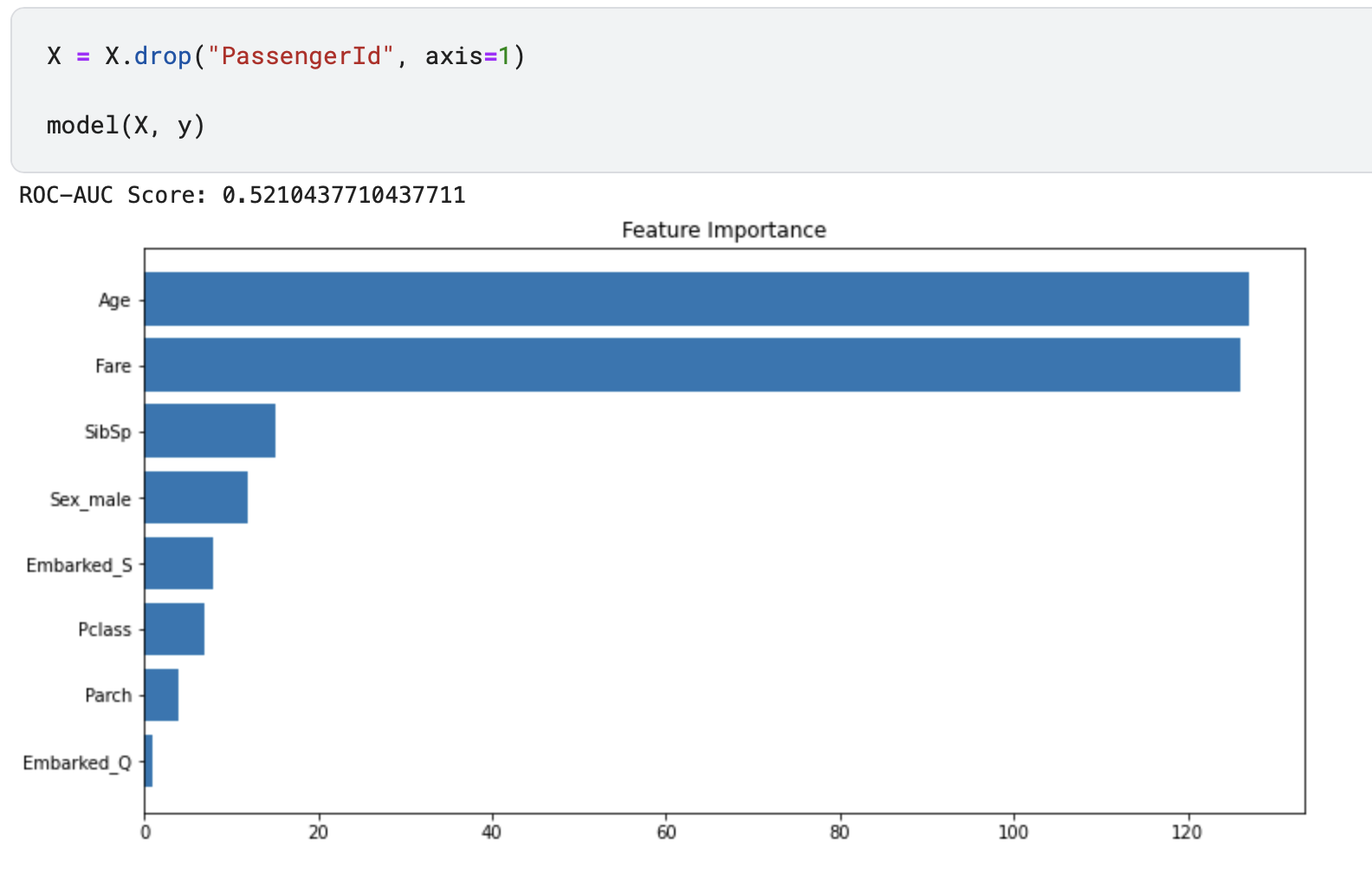
ROC-AUC değerimiz 0.5 civarına geldi ve bu şekilde validasyon yapmamız haliyle daha doğru olacaktır. İşlemimiz bu kadar!
Normal şartlarda bir veri setinin nasıl olması gerektiği, eğitim setinin test setini tam anlamıyla temsil ettiğinde nasıl bir tablo ile karşılaşıldığını incelemek için diğer örneğimiz olan “Data Scientist Job Salaries” veri setine bakalım: Veri bilimcilerinin maaşları, ülkeleri, deneyim süreleri gibi özellikler içeren veri setimizin sütunlarının bir kısmı aşağıdaki gibi gözükmekte.
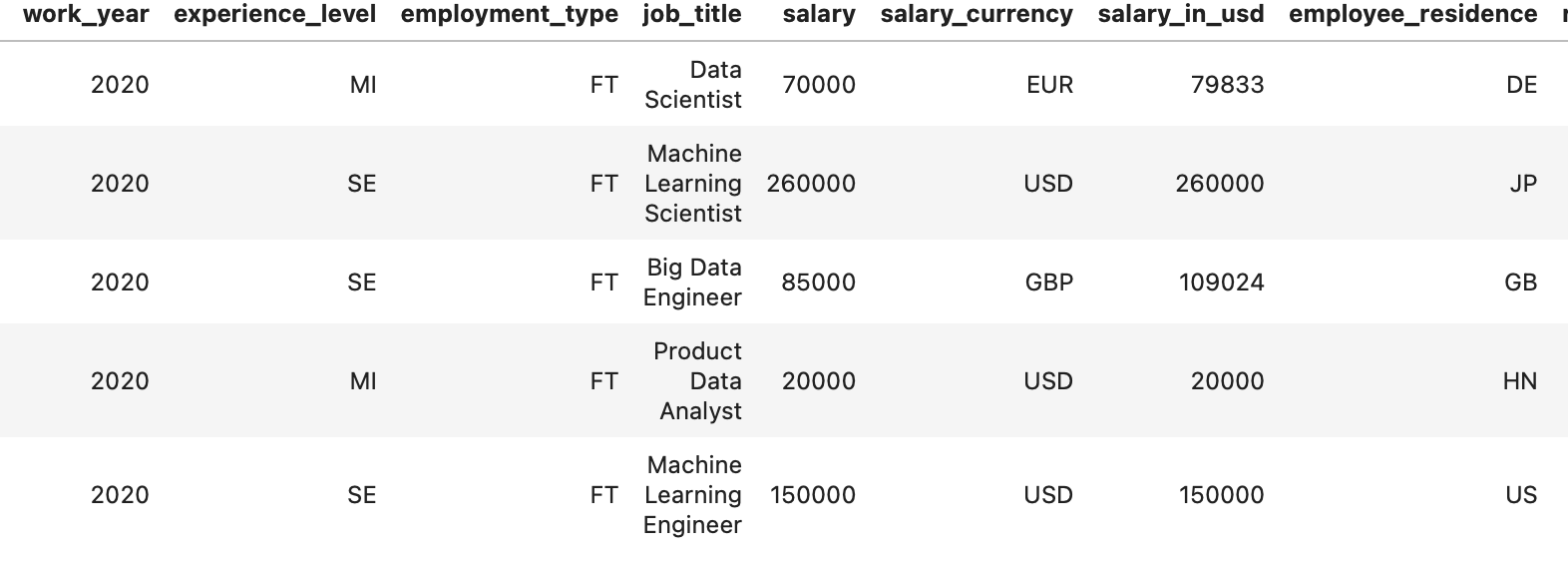
Bu örnekte önceki örnekten farklılık olması adına CatBoost yöntemini kullanalım. Makine öğrenmesi algoritmaları hakkında detaylı eğitim almak isterseniz Veri Bilimci Yetiştirme Programı veya Data Scientist · Miuul sayfalarını inceleyebilirsiniz.
Veri setinin eğitim-test ayrımı, hedef değişken olan “salary” değişkeninin çıkarılıp yerine adversarial validation yöntemi için 1 ve 0’ların label olarak eklenmesi ve model kurulması işlemlerini yukarıdaki gibi adım adım uygulayalım.


ROC-AUC skoru bizim anahtar noktamız. Değerin 0.5 civarında çıkmasını bekleriz.
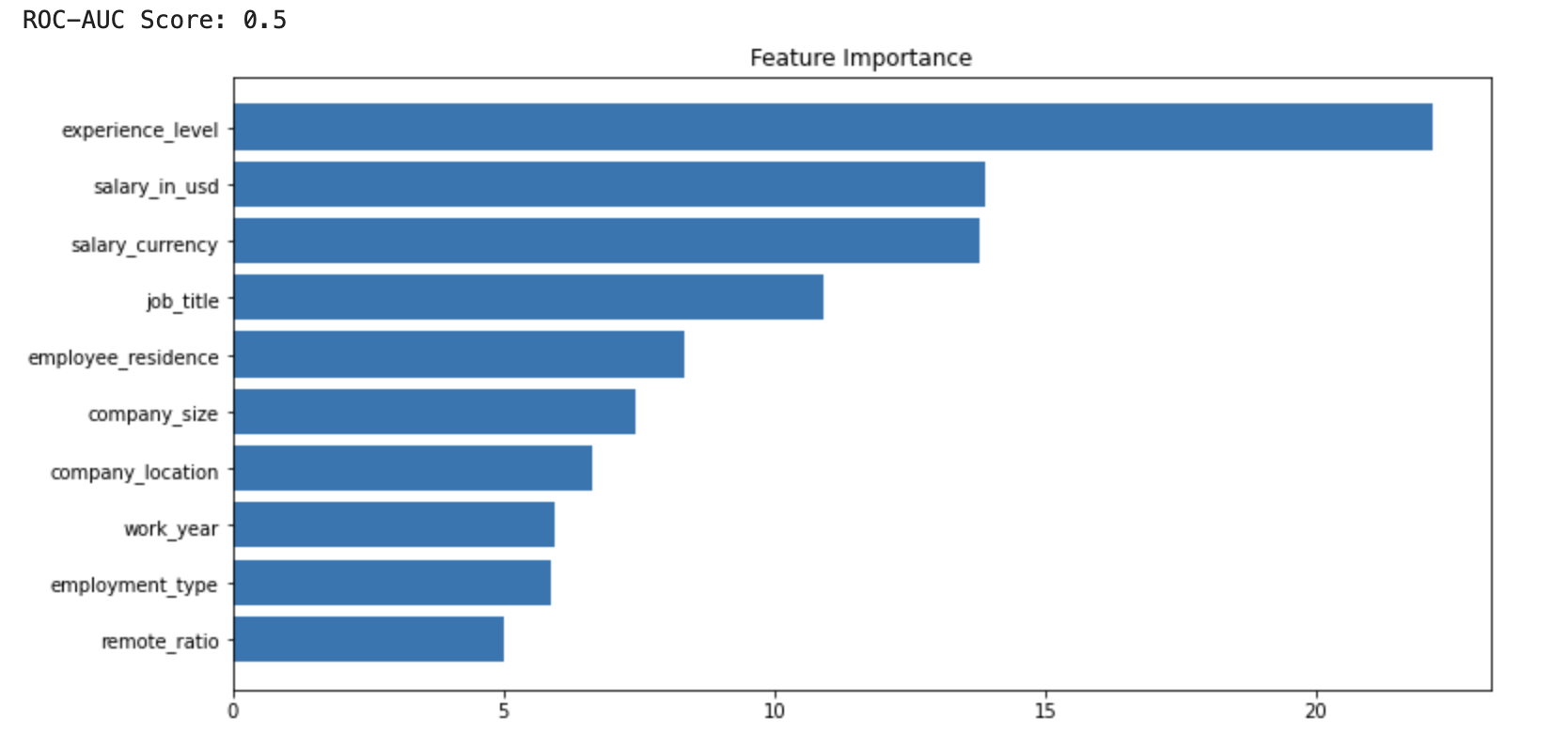
Bu örneğimizde göreceğimiz üzere bu veri seti için eğitim seti, test setimizi başarılı bir şekilde temsil edebiliyor. İşte adversarial validation yöntemi bu kadar basit!
Adversarial validation sonucunda çıkan ROC-AUC skoruna bakarak validasyon tekniklerinin bizi yanıltıp yanıltmayacağını bu şekilde anlayabiliriz.
Bonus
İşleri biraz daha ilerletmek ister misiniz? Adversarial validation yöntemiyle elimizdeki feature’lara bakarak eğitim setinin test setini ne kadar başarılı temsil ettiğini görmüş olduk. Peki bu yöntemi feature’ları incelemeden de kullanamaz mıyız? Cevabımız: Evet, kullanabiliriz! Burada sklearn model seçimi içerisinden StratifiedKFold, yani “katmanlı k-katlı çapraz doğrulama” yöntemini kullanmak.
Bu yöntem içinse yapılması gereken şey; 3. adımımız olan veri setlerini birleştirme adımından sonra model kurma aşamasında birleştirdiğimiz veri setlerini StratifiedKFold ile bölüp her katmanın ROC-AUC skoruna bakmak. Eğer değerler birbirine yakın ve 0.5 çevresindeyse eğitim ve test seti birbirini temsil ediyor diyebiliriz fakat yine de “feature importance” ile önem derecelerine bakmakta fayda olduğunu belirtmekte fayda var.
Titanic veri setindeki adımları en baştan yapmaya başladığımızı ve 3. adımdan sonra StratifiedKFold uygulayarak modelleme yaptığımızı düşünelim. Başta yaptığımız gibi yine Titanic veri seti ve LGBM ile bir model kuralım.
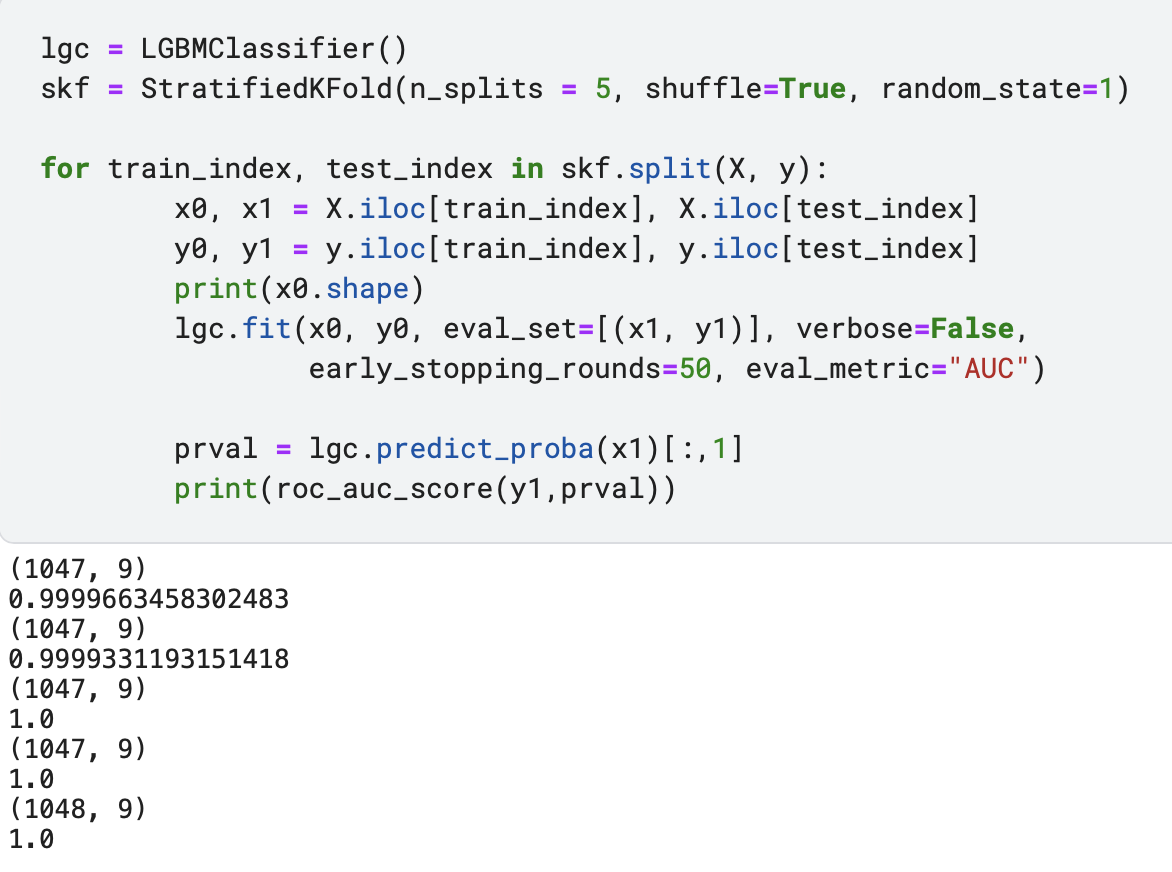
Görülebileceği üzere 5 katmanın her birinin ROC-AUC değerleri 0.5’ten ciddi derecede yüksek olduğunda, burada alarm çanları çalıyor yorumunu yapabiliriz ve değişken önem derelerine de baktıktan sonra PassengerID sütunu yüzünden olan bozulmayı görebiliriz.
Benzer bir şekilde diğer data setimiz olan “Data Scientist Job Salaries” veri setini de aynı işlemle inceleyelim. Aynı şekilde 3. adımdan sonra CatBoost ile bir model kurup çıkan ROC-AUC skorlarını incelersek aşağıdaki sonuçlara ulaşabiliriz.
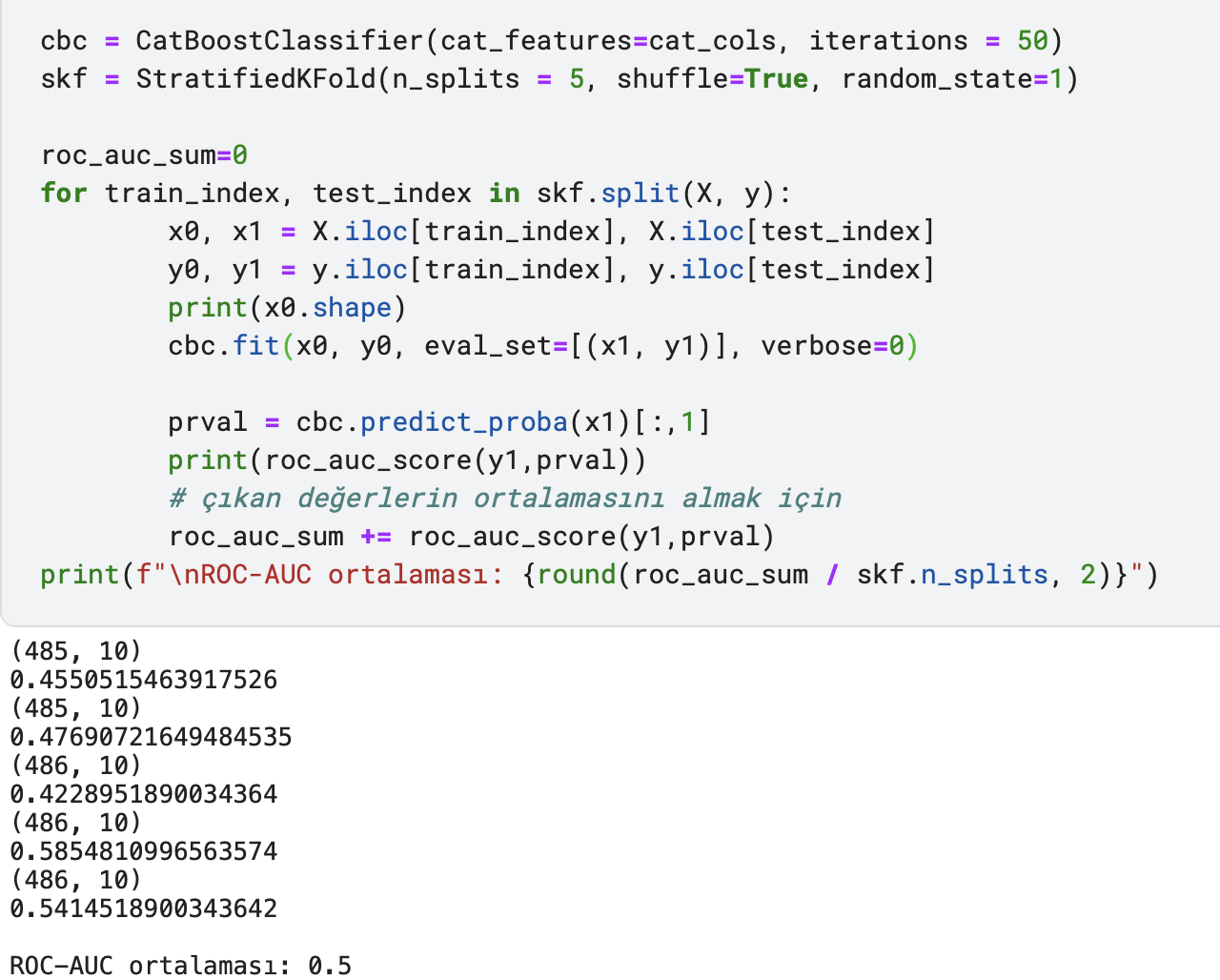
Görülebileceği üzere katlarımız 0.5 çevresine belirli bir oranda dağılmış şekilde. Ortalama ROC-AUC değerine baktığımız zaman 0.5’i yakalamış oluyoruz. İlk bakışta bu veri seti için “eğitim seti, test setini temsil edebiliyor” yorumunu yapıp, sonrasında da bunu feature importance grafiğiyle de destekleyebiliriz.
Sonuç olarak, kullanılması oldukça faydalı olan ve gerek aşırı öğrenme probleminin, gerek validasyon yöntemlerinde oluşabilecek yanılgıların önüne geçebilecek olan adversarial validation yönteminin kullanımı bu şekildeydi.
Kaynaklar
- FastML, Adversarial validation, part one
- FastML, Adversarial validation, part two
- Medium, MLearning.ai, Adversarial Validation: Battling Overfitting
- Kaggle, Titanic - Machine Learning from Disaster
- Kaggle, Data Science Job Salaries
- scikit-learn, StratifiedKFold
