Makine öğrenmesine giriş
Son yıllarda günlük hayatta en büyük yardımcılarımız teknolojik aletler olurken yapay zeka ürünleri yaşamımızın bir parçası oldu. Yapay zeka, makine öğrenmesi gibi kavramlar her ne kadar kamuoyunda makineler işimizi elimizden alacak gibi endişelere neden olarak görünse de bu kaygılara farklı bir açıdan bakmak gerekiyor. İçinde bulunduğumuz yeni dünyada, insanlar olarak yaptığımız işler artık değer yaratan işler olmalı ve rutin, sıkıcı işler makinelere bırakılmalı. Tabi işi devretmeden önce o işi öğretme prensibi makineler için de geçerli.
Makine öğrenmesi nedir?
Makine öğrenmesi, insanların öğrenme becerisini taklit edebilme amacıyla makinelerin veri odağında algoritmalar geliştirerek çalışan bir yapay zeka ve veri bilimi dalıdır.
Makine öğrenimi ve geleneksel programlamada temel fark nedir?
- Geleneksel programlama: Veri Girişi + Program ile beslenir. Makinede çalıştırılır ve çıktı alınır.
- Makine öğrenimi: Veri Girişi + Çıkışı ile beslenir. Eğitim sırasında makinede çalıştırılır ve makine, test sırasında değerlendirilebilecek kendi programını(mantığını) oluşturur.
Makineler öğrenirken insanların öğrenme davranışını taklit eder. İnsanlar, bir bilgi ile ilk temasında onu örneklerle, uygulamalarla pekiştirdiğinde öğrenmiş olur. Makineler de buna benzer olarak ona verilen veriyi eğitim(train) ve test olarak ikiye ayırır. Eğitim veri setini çeşitli algoritmalar ile kendini eğitmek için kullanırken test seti ile öğrendiklerini test eder. Daha sonra ona bir soru sorduğumuzda sonucunu tahmin eder.
Peki ya makineler nasıl öğrenir?
Makineler için üç ayrı öğrenme türü vardır. Bunlardan biri denetimli öğrenmedir (supervised learning). Veri setinde hedef değişken (target) varsa kuracağımız model bağımlı ve bağımsız değişken arasındaki ilişkiyi hedef değişken denetiminde öğreniyor olacaktır.
Bir diğeri, veri setinde hedef değişken yoksa makine tarafında segmentasyon yapılabilen ve benzerliklere göre kümeleme yaparak öğrenme gerçekleştiren denetimsiz öğrenmedir (unsupervised learning).
Son olarak da makinenin deneme-yanılma yöntemi ile öğrenmesi olarak bildiğimiz pekiştirmeli öğrenmedir (reinforcement learning). Bir robotun cezalandırma ile öğrenmesi bir bebeğin sıcak bir nesneye dokununca yandığında ona dokunmamayı öğrenmesine benzetilebilir. Otonom araçların deneme sürüşlerinde doğruyu öğrenene kadar kaza yaparak öğrenmesi de buna örnek verilebilir.
Problem türleri
Sınıflandırma problemi
Veri setinde hedef yani bağımlı değişken kategorik ise bu bir sınıflandırma problemidir. Müşteri terki, bir kazada hayatta kalma durumu ya da bir takımın şampiyon olup olamayacağı sınıflandırma modeli ile tahmin edilir.
Regresyon problemi
Veri setindeki hedef yani bağımlı değişken sayısal (numeric) ise bu bir regresyon problemidir. Bir gayrimenkul değerlemede evin parasal değeri tahmini ya da bir sektörde maaş tahmini regresyon modeli ile gerçekleştirilebilir.
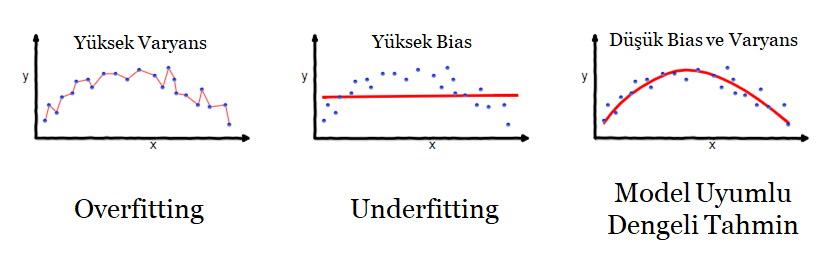
Yanlılık - Varyans ilişkisi (bias - variance tradeoff)
Makine öğrenmesinde sıklıkla “Overfitting nedir? Bununla nasıl başa çıkabiliriz?” sorusu sorulmaktadır. Bu konuda iki kavram karşımıza çıkar: underfitting ve overfitting.
- Underfitting (Yüksek yanlılık ): Modelin veriyi öğrenememesidir.
- Overfitting (Yüksek varyans): Aşırı öğrenme, model tarafından verinin ezberlenmesidir.
Bu kavramları regresyon modellerinde inceleyecek olursak karşımıza aşağıdaki gibi bir gösterim çıkacak.
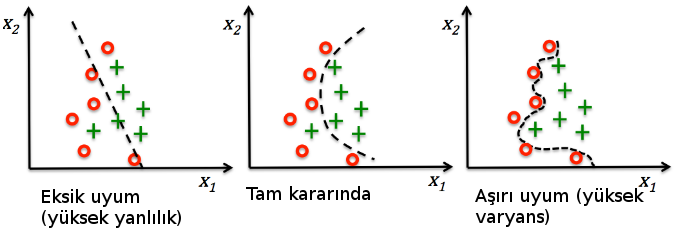
Sınıflandırma modellerinde de buna benzer bir durumla karşılaşırız.
Makine öğrenmesi metotları kullanılarak probleme uygun modeller elde edilir. Sadece eğitim (train) veri seti kullanmak her zaman için kabul edilebilir bir durum değildir çünkü modelde overfitting (yüksek yanlılık,aşırı uyum) durumu olabilir. Bu durumdan kurtulmak için iki farklı yaklaşım önerilir: hold-out ve cross validation.
Overfitting’ten kaçınmak ve model performansını ölçmek için her iki yöntem de modelin daha önce görmediği bir test veri seti kullanır. Çünkü, modelin asıl başarısını hiç görmediği verilerdeki tahmin gücü belirler.
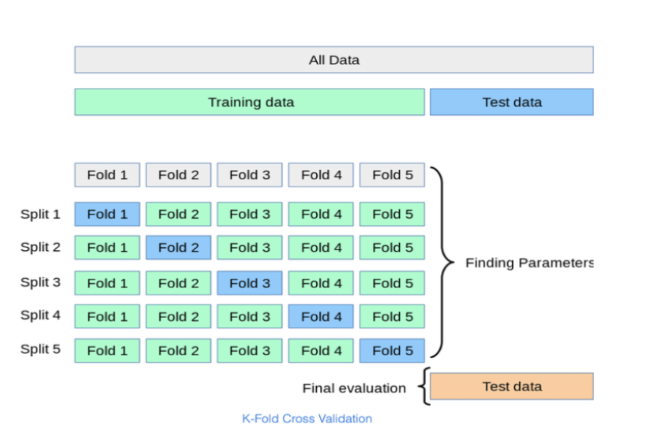
Kurulan modelin tahmin sonucu bazı teknikler ile değerlendirilir ve model başarısını, yani bu öğrenme sürecinin ne oranda doğru sonuca ulaştığını öğrenebiliriz. Bu başarıyı etkileyen en önemli faktör ise veri ön işleme(data proprecessing) aşamasıdır. Yani tahminleme, sınıflandırma gibi bir yapay zeka projesinin temelini, veri ön işleme yöntemleriyle oluşturur, daha sonra makine öğrenmesi teknikleri ile model kurarız.
Makine öğrenmesi ve veri bilimi hakkında daha detaylı bilgi sahibi olmak için Miuul Makine Öğrenmesi eğitimine göz atabilirsiniz. FLO, THY ve Scoutium gibi şirketlerin gerçek hayat verileri ile projeler yapmak için Data Scientist eğitimine kayıt olabilir ve mentorluk sistemi ile oluşturulmuş kariyer yolculuklarımızda yerinizi alabilirsiniz.
Kaynaklar
- Miuul, Data Scientist Path
- Veri Bilimi Okulu, Veri Bilimi Okulu/Makine Öğrenmesi
- IBM, What is the machine learning?
- TechTarget, Machine-Learning
