Power BI ile CRM analitiği III: CLTV ile müşteri segmenti oluşturma
Bir şirket için müşteri segmentasyonu oldukça önem taşıyan bir konudur. Kısaca CLTV (Customer Lifetime Value) sayesinde müşterilerin satın alma ve karlılık patternları göz önünde bulundurularak müşteriye özel teklifte bulunulabilir.
CLTV hesaplamasından ve bu hesaplamada kullanılan kavramlardan bahsedelim.
CLTV = (Customer Value / Churn Rate) * Profit Margin
Customer Value = Avg Order Value * Purchase Frequency
Avg Order Value = Total Revenue / Total # of Orders
Purchase Frequency = Total # of Orders / Total # of Customers
Churn Rate = 1-Repeat Rate
Yukarıda yer alan formüllerdeki değerleri açıklamak gerekirse:
Customer Value: Müşteri Değeri
Avg Order Value: Müşterinin sipariş başına bırakacağı ortalama para
Purchase Fequency: Satın alma sıklığı
Total # of Orders: Toplam sipariş miktarı
Total #of Customers: Toplam müşteri sayısı
Profit Margin: Karlılık
Churn Rate: Müşterinin bir daha alışveriş yapmaması
Repeat Rate: Birden fazla alışveriş yapan müşteri sayısı / Toplam müşteri sayısı
Çalışma kapsamında Online Retail II isimli veri setini kullanıyor olacağız. PowerBI’da Python kodu çalıştırabilmek için Get Data → More tıklayıp arama çubuğuna Python yazmamız yeterli. Bu kısma CLTV değerlerini elde etmek için uygulayacağımız işlemleri ve segmentlere atanmış final scriptimizi yapıştırıyoruz.
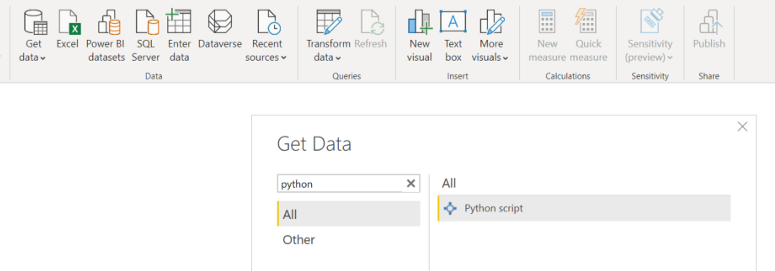
Beş gruba ayrılmış CLTV hesaplaması için aşağıdaki Python kodunu ilgili alana yapıştırıp çalıştırabilirsiniz.
import datetime as dt
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
import warnings
warnings.filterwarnings("ignore", category=DeprecationWarning)
warnings.filterwarnings("ignore", category=FutureWarning)
pd.set_option('display.max_columns', None)
pd.set_option('display.max_columns', None)
df_ = pd.read_excel("D:/online_retail_II.xlsx",sheet_name="Year 2010-2011")
df = df_.copy()
def outlier_thresholds(dataframe, variable):
quartile1 = dataframe[variable].quantile(0.01)
quartile3 = dataframe[variable].quantile(0.99)
interquantile_range = quartile3 - quartile1
up_limit = quartile3 + 1.5 * interquantile_range
low_limit = quartile1 - 1.5 * interquantile_range
return low_limit, up_limit
def replace_with_thresholds(dataframe, variable):
low_limit, up_limit = outlier_thresholds(dataframe, variable)
# dataframe.loc[(dataframe[variable] < low xss=removed>
dataframe.loc[(dataframe[variable] > up_limit), variable] = up_limit
def crm_data_prep(dataframe):
dataframe.dropna(axis=0, inplace=True)
dataframe = dataframe[~dataframe["Invoice"].str.contains("C", na=False)]
dataframe = dataframe[dataframe["Quantity"] > 0]
replace_with_thresholds(dataframe, "Quantity")
replace_with_thresholds(dataframe, "Price")
dataframe["TotalPrice"] = dataframe["Quantity"] * dataframe["Price"]
return dataframe
df_prep = crm_data_prep(df)
##########################################
# Creating RFM Segments
##########################################
def create_rfm(dataframe):
today_date = dt.datetime(2011, 12, 11)
rfm = dataframe.groupby('Customer ID').agg({'InvoiceDate': lambda date: (today_date - date.max()).days,
'Invoice': lambda num: num.nunique(),
"TotalPrice": lambda price: price.sum(),
"Country": lambda country: country.min()})
rfm.columns = ['recency', 'frequency', "monetary", "Country"]
rfm = rfm[(rfm['monetary'] > 0)]
rfm["recency_score"] = pd.qcut(rfm['recency'], 5, labels=[5, 4, 3, 2, 1])
rfm["frequency_score"] = pd.qcut(rfm["frequency"].rank(method="first"), 5, labels=[1, 2, 3, 4, 5])
rfm['rfm_segment'] = rfm['recency_score'].astype(str) + rfm['frequency_score'].astype(str)
seg_map = {
r'[1-2][1-2]': 'hibernating',
r'[1-2][3-4]': 'at_risk',
r'[1-2]5': 'cant_loose',
r'3[1-2]': 'about_to_sleep',
r'33': 'need_attention',
r'[3-4][4-5]': 'loyal_customers',
r'41': 'promising',
r'51': 'new_customers',
r'[4-5][2-3]': 'potential_loyalists',
r'5[4-5]': 'champions'
}
rfm['rfm_segment'] = rfm['rfm_segment'].replace(seg_map, regex=True)
rfm = rfm[["recency", "frequency", "monetary", "recency_score","frequency_score", "rfm_segment", "Country"]]
return rfm
rfm = create_rfm(df_prep)
##########################################
# Creating CLTV
##########################################
def create_cltv_c(dataframe):
dataframe['avg_order_value'] = dataframe['monetary'] / dataframe['frequency']
dataframe["purchase_frequency"] = dataframe['frequency'] / dataframe.shape[0]
repeat_rate = dataframe[dataframe.frequency > 1].shape[0] / dataframe.shape[0]
churn_rate = 1 - repeat_rate
dataframe['profit_margin'] = dataframe['monetary'] * 0.05
dataframe['cv'] = (dataframe['avg_order_value'] * dataframe["purchase_frequency"])
dataframe['cltv'] = (dataframe['cv'] / churn_rate) * dataframe['profit_margin']
scaler = MinMaxScaler(feature_range=(1, 100))
scaler.fit(dataframe[["cltv"]])
dataframe["cltv_c"] = scaler.transform(dataframe[["cltv"]])
dataframe["cltv_c_segment"] = pd.qcut(dataframe["cltv_c"], 5, labels=["E", "D", "C", "B", "A"])
dataframe = dataframe[["recency", "frequency", "monetary","recency_score","frequency_score", "rfm_segment","cltv_c", "cltv_c_segment", "Country"]]
return dataframe
rfm_cltv = create_cltv_c(rfm)
Görselleştirmede kullanacağımız rfm_cltv tablosunu seçelim ve Loada basarak yüklenmesini sağlayalım.
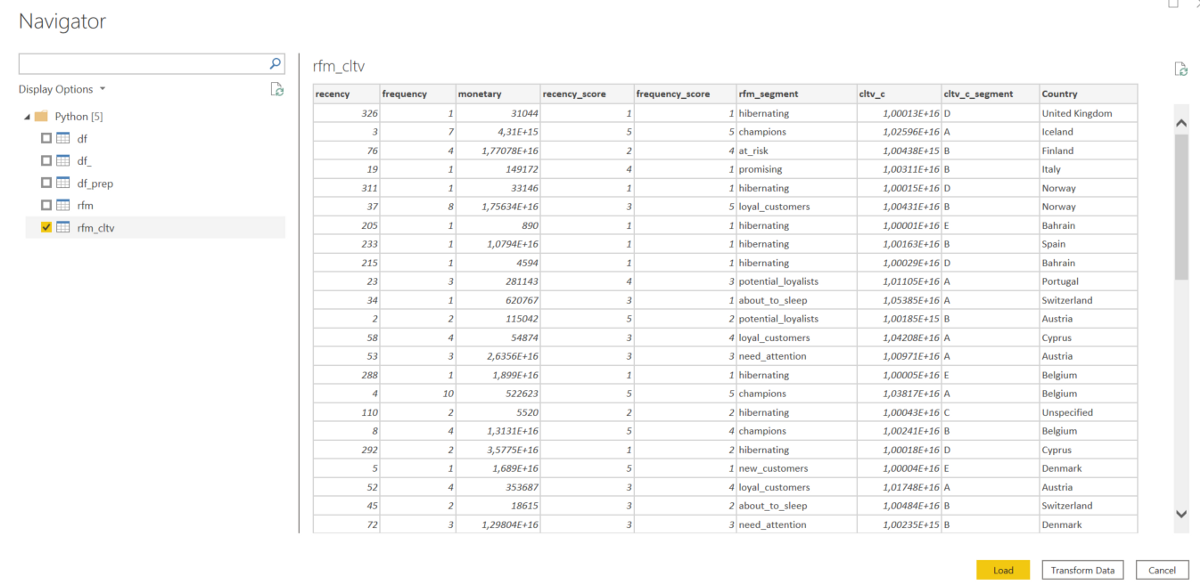
Yükleme sonrası veride sayısal değerlerin string olarak yüklendiğine ve nokta-virgül uyumsuzlukları olduğunu göreceksiniz. Bunları düzenlemek için Queries sekmesindeki Transform Dataya basalım ve değiştirilmesi gereken sütunu tamamen seçip Any Columnsta yer alan Replace Valuesa tıklayarak noktayı virgüle çevirelim. Fakat bu haliyle bazı sütunlar hala string yapıda. Sütunların hepsini seçip Data Type kısmından Decimal Numbera dönüştürebiliriz. Tablonun Close & Apply demeden önceki son hali aşağıdaki gibi olmaktadır.
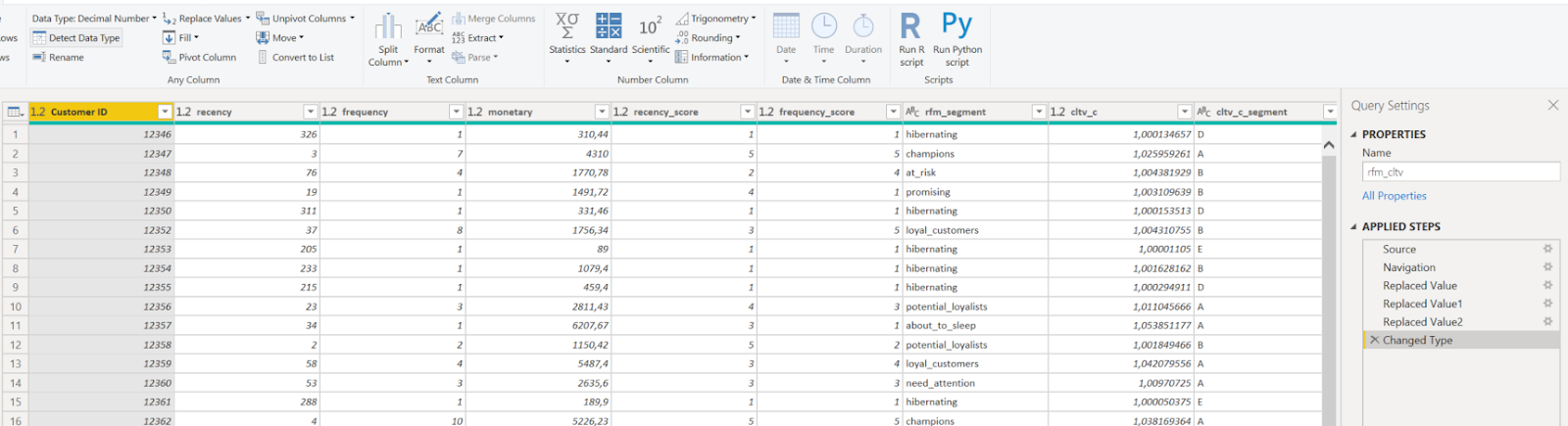
Veriyi hazırlama aşaması sona erdi.
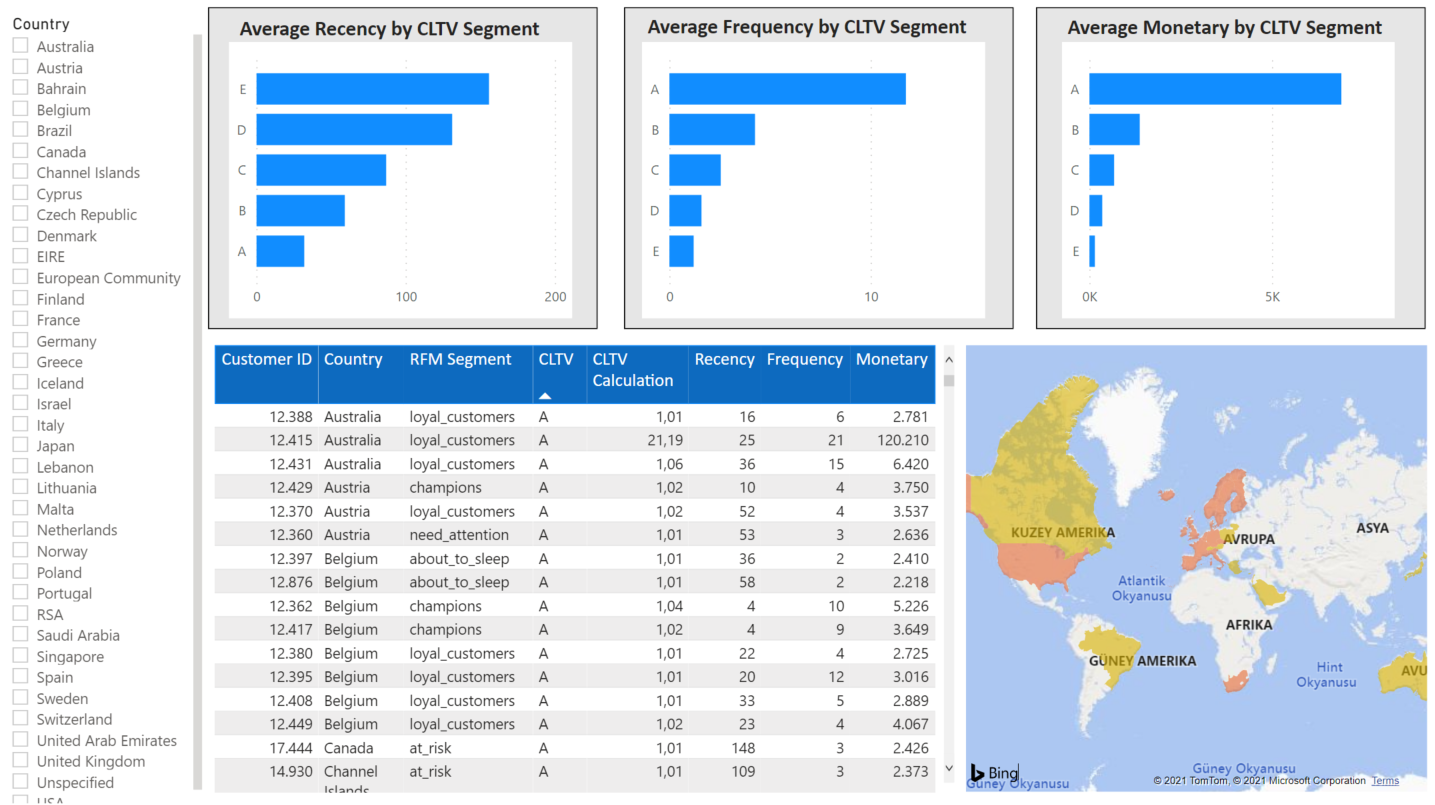
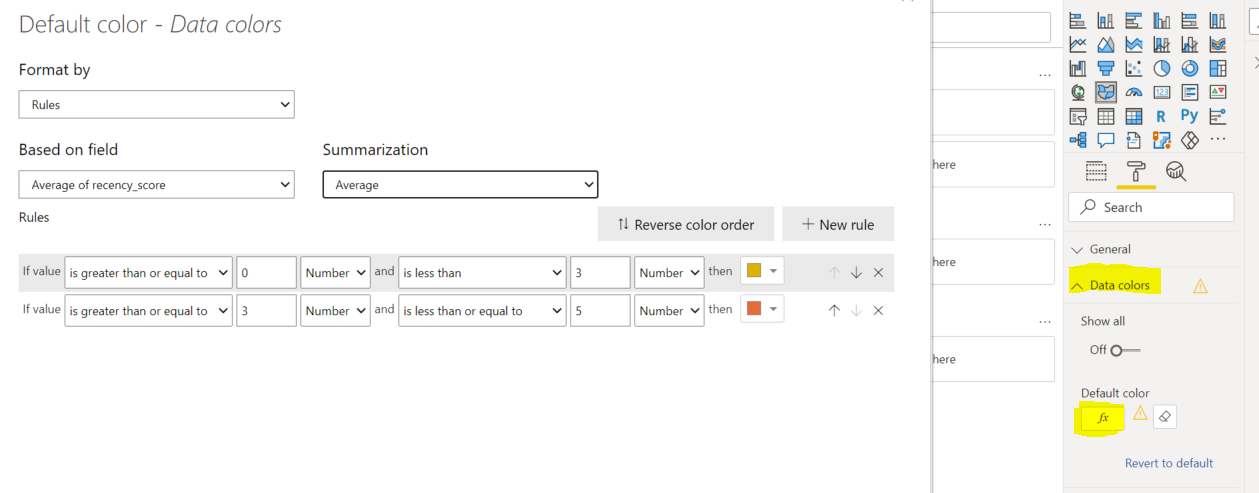
İlk olarak ülkeleri ortalama Recency skor değerlerine göre renklendirelim. Bunun için format kısmından Data colors için default değil, kurala göre renklendirme yapmasını seçiyoruz. Müşterilerin son alışveriş yaptığı skor değeri 3 ve 5 arasında ise turuncuya, 3'ten küçük ise sarıya boyayacak şekilde renklendiriyoruz.
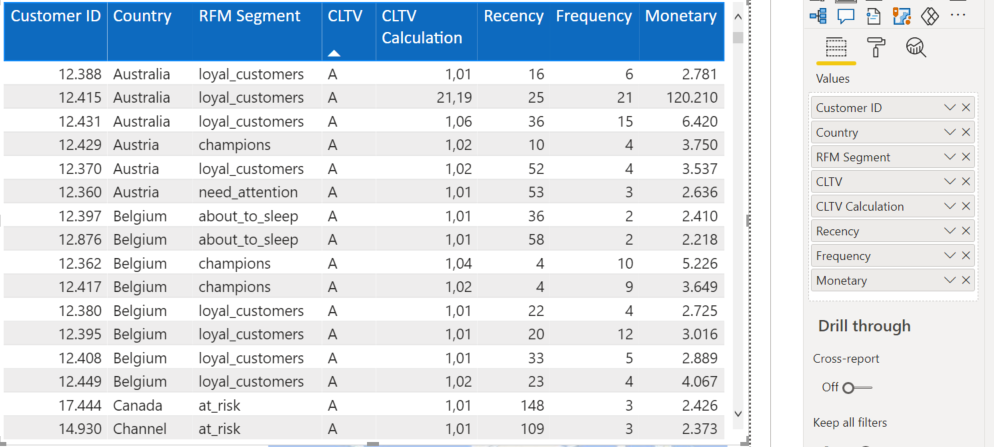
Bir de tüm müşteriler için Country, Recency, Frequency, RFM Segment ve CLTV segmentleri ile CLTV hesaplama değerlerini Visualization kısmındaki Table seçeneğine tıklayarak görselleştirelim.
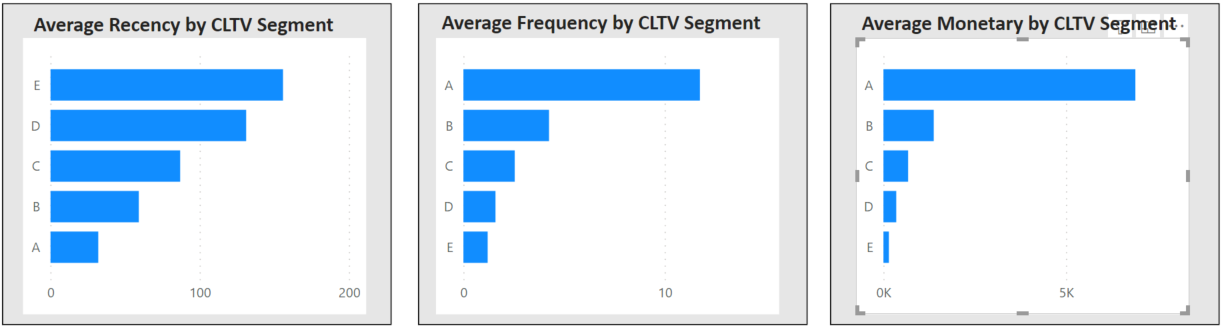
Son görsel olarak Insert kısmında Elementste yer alan Shapes içinden üç adet Rectangle seçelim. Her birine Text Box ekleyelim. Format shapete yer alan Fill kısmında gri rengi seçerek arka planı renklendirebilriz. CLTV segmentlerine göre ortalama Recency, Frequency ve Monetary metriklerini görselleştirelim.

Bunun için Visualizations kısmındaki Clustered Bar Chart seçeneğini kullanabilirsiniz. Axis kısmına cltv_c_segment değişkenini, Values kısmına ise Recency, Monetary, Frequency değerlerini her görsel için ayrı ayrı sürükleyip bırakalım. Ortalama değeri için ok tuşuna basarak Average değerlerini seçelim.
Son olarak Slicer seçerek Field alanına Country değerini koyabiliriz. Böylece ülkelere göre filtreleme işlemini kolayca gerçekleştirebiliriz.
CRM Analitiği çalışmalarının ardındaki mantığı daha detaylı bir biçimde anlayabilmek için Miuul'un CRM Analitiği eğitimine katılabilirsiniz. Power BI yeteneklerinizi geliştirmek içinse Power BI ile Veri Analizi ve Veri Görselleştirme eğitimini inceleyebilirsiniz.
