Power BI ile CRM analitiği IV: Müşteri yaşam boyu değeri tahmini
Elimizdeki müşterilerin kullanıcı davranışlarını göz önünde bulundurarak belli bir zaman projeksiyonu ile geleceğe yönelik Customer Life Time Value tahmini yapabilir ve bunu Power BI yardımıyla görselleştirebiliriz.
CLTV tahmini için kullanılan iki olasılıksal dağılım bulunmaktadır. Bunlar BGNBD (Beta Geometric Negative Binomial Distribution) ve Gamma Gamma olarak ifade edilebilir. Her iki dağılıma göre model oluşturup birleştirilerek final model oluşturulur.
BGNBD, expected number of transaction (beklenen işlem sayısı) ile ilgilenirken ilgili dağılımın içinde zaman değişkeni bulunmaktadır. Müşterinin satın alma davranışı yapısı model sayesinde öğrenilir. Modele fit ederken Frequency, Recency ve Tenure (müşteri yaşı) değerleri kullanılır.
Gamma Gamma ise expected average profit (beklenen ortalama karlılık) değeri ile ilgilenir. Modele fit edilirken Frequency ve Monetary değerleri kullanılır.
Veri müşteri bazında tekil olmalıdır. Her müşterinin aşağıda belirtilen değerleri hesaplanır:
- Recency değeri (son alışveriş yaptığı tarih - ilk alışveriş yaptığı tarih)
- Tenure değeri (bugünün tarihi - ilk alışveriş yaptığı tarih)
- Satın alma adedi
- Toplam getirdiği gelir
CLTV = Expected Number of Transaction (BGNBD) * Expected Average Profit (Gamma Gamma)
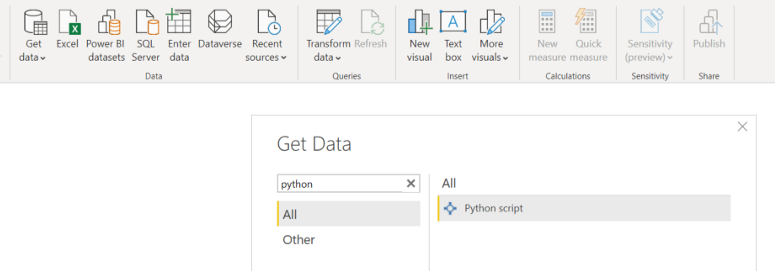
Veri setimizi artık tanıyoruz. PowerBI’ da python kodu çalıştırabilmek için “Get Data” — “More” tıklayıp arama çubuğuna python yazmamız yeterli. Şimdiye kadar CRM analitiği kapsamında elde ettiğimiz segmentleri final tablomuza ekleyelim. Oluşturduğumuz segmentasyon çalışmaları sırasıyla RFM , KMeans, CLTV_Calculation, CLTV_Prediction segmentleridir.
Çalışma kapsamında Online Retail II isimli veri setini kullanıyor olacağız. PowerBI’da Python kodu çalıştırabilmek için Get Data → More tıklayıp arama çubuğuna Python yazmamız yeterli. Bu kısma CLTV tahmini için yazdığımız final scriptimizi yapıştırıyoruz.
import datetime as dt
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.preprocessing import MinMaxScaler
from lifetimes import BetaGeoFitter
from lifetimes import GammaGammaFitter
pd.set_option('display.max_columns', None)
pd.set_option('display.max_rows', None)
from warnings import simplefilter
simplefilter(action='ignore', category=FutureWarning)
from warnings import simplefilter
simplefilter(action='ignore', category=FutureWarning)
##################################
# Verinin Çağrılması
##################################
df_ = pd.read_excel("C:\online_retail_II.xlsx", sheet_name="Year 2010-2011")
df = df_.copy()
##################################
# Veri Ön İşleme
##################################
def outlier_thresholds(dataframe, variable):
quartile1 = dataframe[variable].quantile(0.01)
quartile3 = dataframe[variable].quantile(0.99)
interquantile_range = quartile3 - quartile1
up_limit = quartile3 + 1.5 * interquantile_range
low_limit = quartile1 - 1.5 * interquantile_range
return low_limit, up_limit
def replace_with_thresholds(dataframe, variable):
low_limit, up_limit = outlier_thresholds(dataframe, variable)
# dataframe.loc[(dataframe[variable] < low xss=removed>
dataframe.loc[(dataframe[variable] > up_limit), variable] = up_limit
def crm_data_prep(dataframe):
dataframe.dropna(axis=0, inplace=True)
dataframe = dataframe[~dataframe["Invoice"].str.contains("C", na=False)]
dataframe = dataframe[dataframe["Quantity"] > 0]
replace_with_thresholds(dataframe, "Quantity")
replace_with_thresholds(dataframe, "Price")
dataframe["TotalPrice"] = dataframe["Quantity"] * dataframe["Price"]
return dataframe
df_prep = crm_data_prep(df)
##################################
# RFM Segmenti Oluşturma
##################################
def create_rfm(dataframe):
# RFM METRIKLERININ HESAPLANMASI
today_date = dt.datetime(2011, 12, 11)
rfm = dataframe.groupby('Customer ID').agg({'InvoiceDate': lambda date: (today_date - date.max()).days,
'Invoice': lambda num: num.nunique(),
"TotalPrice": lambda price: price.sum()})
rfm.columns = ['recency', 'frequency', "monetary"]
rfm = rfm[(rfm['monetary'] > 0)]
# RFM SKORLARININ HESAPLANMASI
rfm["recency_score"] = pd.qcut(rfm['recency'].rank(method="first"), 5, labels=[5, 4, 3, 2, 1])
rfm["frequency_score"] = pd.qcut(rfm["frequency"].rank(method="first"), 5, labels=[1, 2, 3, 4, 5])
# SEGMENTLERIN ISIMLENDIRILMESI
rfm['rfm_segment'] = rfm['recency_score'].astype(str) + rfm['frequency_score'].astype(str)
seg_map = {
r'[1-2][1-2]': 'hibernating',
r'[1-2][3-4]': 'at_risk',
r'[1-2]5': 'cant_loose',
r'3[1-2]': 'about_to_sleep',
r'33': 'need_attention',
r'[3-4][4-5]': 'loyal_customers',
r'41': 'promising',
r'51': 'new_customers',
r'[4-5][2-3]': 'potential_loyalists',
r'5[4-5]': 'champions'
}
rfm['rfm_segment'] = rfm['rfm_segment'].replace(seg_map, regex=True)
rfm = rfm[["recency", "frequency", "monetary", 'recency_score', 'frequency_score', "rfm_segment"]]
return rfm
rfm = create_rfm(df_prep)
rfm.recency_score = rfm.recency_score.astype(int)
rfm.frequency_score = rfm.frequency_score.astype(int)
##################################
# KMEANS CLUSTERING
##################################
k_means = KMeans(n_clusters=6, init='k-means++', random_state = 0).fit(rfm[['recency_score', 'frequency_score']])
rfm['K_means_label'] = k_means.labels_
rfm['K_means_label'] = rfm['K_means_label'] + 1
##################################
# CLTV Calculation
##################################
def create_cltv_c(dataframe):
# avg_order_value
dataframe['avg_order_value'] = dataframe['monetary'] / dataframe['frequency']
# purchase_frequency
dataframe["purchase_frequency"] = dataframe['frequency'] / dataframe.shape[0]
# repeat rate & churn rate
repeat_rate = dataframe[dataframe.frequency > 1].shape[0] / dataframe.shape[0]
churn_rate = 1 - repeat_rate
# profit_margin
dataframe['profit_margin'] = dataframe['monetary'] * 0.05
# Customer Value
dataframe['cv'] = (dataframe['avg_order_value'] * dataframe["purchase_frequency"])
# Customer Lifetime Value
dataframe['cltv'] = (dataframe['cv'] / churn_rate) * dataframe['profit_margin']
# minmaxscaler
scaler = MinMaxScaler(feature_range=(1, 100))
scaler.fit(dataframe[["cltv"]])
dataframe["cltv_c"] = scaler.transform(dataframe[["cltv"]])
dataframe["cltv_c_segment"] = pd.qcut(dataframe["cltv_c"], 3, labels=["C", "B", "A"])
dataframe = dataframe[["recency", "frequency", "monetary", "recency_score", "frequency_score", "rfm_segment", "K_means_label", "cltv_c", "cltv_c_segment"]]
return dataframe
rfm_cltv = create_cltv_c(rfm)
##################################
# CLTV Prediction
##################################
def create_cltv_p(dataframe):
today_date = dt.datetime(2011, 12, 11)
## recency kullanıcıya özel dinamik.
rfm = dataframe.groupby('Customer ID').agg({'InvoiceDate': [lambda date: (date.max()-date.min()).days,
lambda date: (today_date - date.min()).days],
'Invoice': lambda num: num.nunique(),
'TotalPrice': lambda TotalPrice: TotalPrice.sum()})
rfm.columns = rfm.columns.droplevel(0)
## recency_cltv_p
rfm.columns = ['recency_cltv_p', 'T', 'frequency', 'monetary']
## basitleştirilmiş monetary_avg
rfm["monetary"] = rfm["monetary"] / rfm["frequency"]
rfm.rename(columns={"monetary": "monetary_avg"}, inplace=True)
# BGNBD için WEEKLY RECENCY VE WEEKLY T'nin HESAPLANMASI
## recency_weekly_cltv_p
rfm["recency_weekly_cltv_p"] = rfm["recency_cltv_p"] / 7
rfm["T_weekly"] = rfm["T"] / 7
# KONTROL
rfm = rfm[rfm["monetary_avg"] > 0]
## recency filtre (daha saglıklı cltvp hesabı için)
rfm = rfm[(rfm['frequency'] > 1)]
rfm["frequency"] = rfm["frequency"].astype(int)
# BGNBD
bgf = BetaGeoFitter(penalizer_coef=0.01)
bgf.fit(rfm['frequency'],
rfm['recency_weekly_cltv_p'],
rfm['T_weekly'])
# exp_sales_1_week
rfm["exp_sales_1_week"] = bgf.predict(1, # 1 weeks
rfm['frequency'],
rfm['recency_weekly_cltv_p'],
rfm['T_weekly'])
# exp_sales_1_month
rfm["exp_sales_1_month"] = bgf.predict(4, #4 weeks
rfm['frequency'],
rfm['recency_weekly_cltv_p'],
rfm['T_weekly'])
# exp_sales_3_month
rfm["exp_sales_3_month"] = bgf.predict(12, #4*3 weeks
rfm['frequency'],
rfm['recency_weekly_cltv_p'],
rfm['T_weekly'])
# expected_average_profit
ggf = GammaGammaFitter(penalizer_coef=0.01)
ggf.fit(rfm['frequency'], rfm['monetary_avg'])
rfm["expected_average_profit"] = ggf.conditional_expected_average_profit(rfm['frequency'],
rfm['monetary_avg'])
# 6 aylık cltv_p
cltv = ggf.customer_lifetime_value(bgf,
rfm['frequency'],
rfm['recency_weekly_cltv_p'],
rfm['T_weekly'],
rfm['monetary_avg'],
time=6, #6 months
freq="W", #tenure
discount_rate=0.01)
rfm["cltv_p"] = cltv
# minmaxscaler
scaler = MinMaxScaler(feature_range=(1, 100))
scaler.fit(rfm[["cltv_p"]])
rfm["cltv_p"] = scaler.transform(rfm[["cltv_p"]])
# cltv_p_segment
rfm["cltv_p_segment"] = pd.qcut(rfm["cltv_p"], 3, labels=["C", "B", "A"])
# recency_cltv_p, recency_weekly_cltv_p
rfm = rfm[["recency_cltv_p", "T", "monetary_avg", "recency_weekly_cltv_p", "T_weekly", "exp_sales_1_week", "exp_sales_1_month", "exp_sales_3_month", "expected_average_profit", "cltv_p", "cltv_p_segment"]]
return rfm
rfm_cltv_p = create_cltv_p(df_prep)
crm_final = rfm_cltv.merge(rfm_cltv_p, on="Customer ID", how="left")
crm_final = crm_final.reset_index()
crm_final_country = crm_final.merge(df_prep[["Customer ID", "Country"]].drop_duplicates(), on="Customer ID", how="left")Kodu çalıştırmamızın ardından final tablomuz olan crm_final_countryi seçelim.
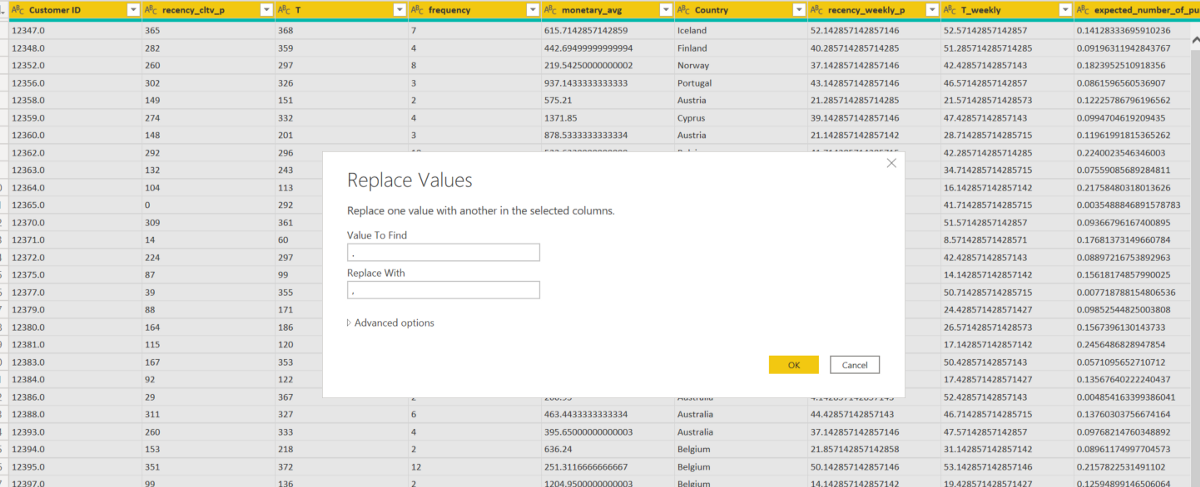
Yükleme sonrası verideki sayısal değerler otomatik numbera çevrilirken nokta-virgül uyumsuzlukları olduğunu göreceksiniz. Bu durumu istemediğimizden otomatik dönüştürme işlemini Applied Steps kısmından silelim. Queries sekmesindeki Transform Dataya basalım ve değiştilmesi gereken sütunları tamamen seçip Any Columnsta yer alan Replace Valuesa basarak noktayı virgüle çevirelim.
Dönüştürme ve nokta olarak beslenen değerleri virgül ile yer değiştirme işlemlerinden sonra tablonun son hali aşağıdaki gibi olmaktadır. Applied Steps kısmında dönüşümler görülebilir.
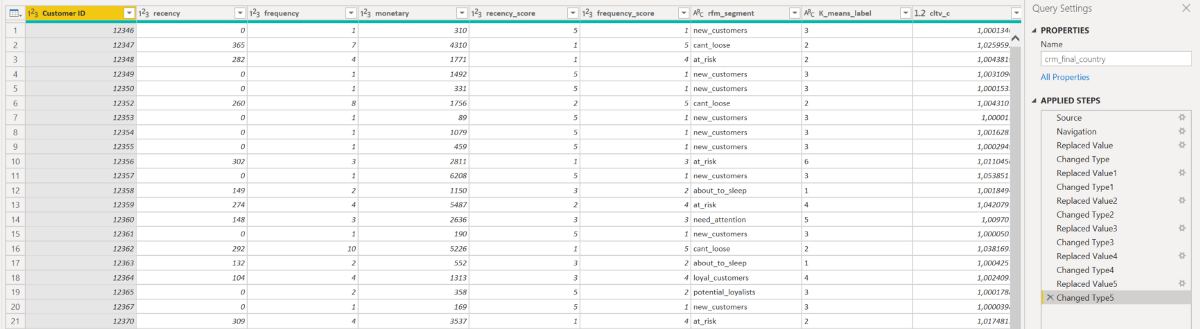
Dönüşüm işlemleri bittiğinde Close&Apply diyerek query editörden çıkalım.
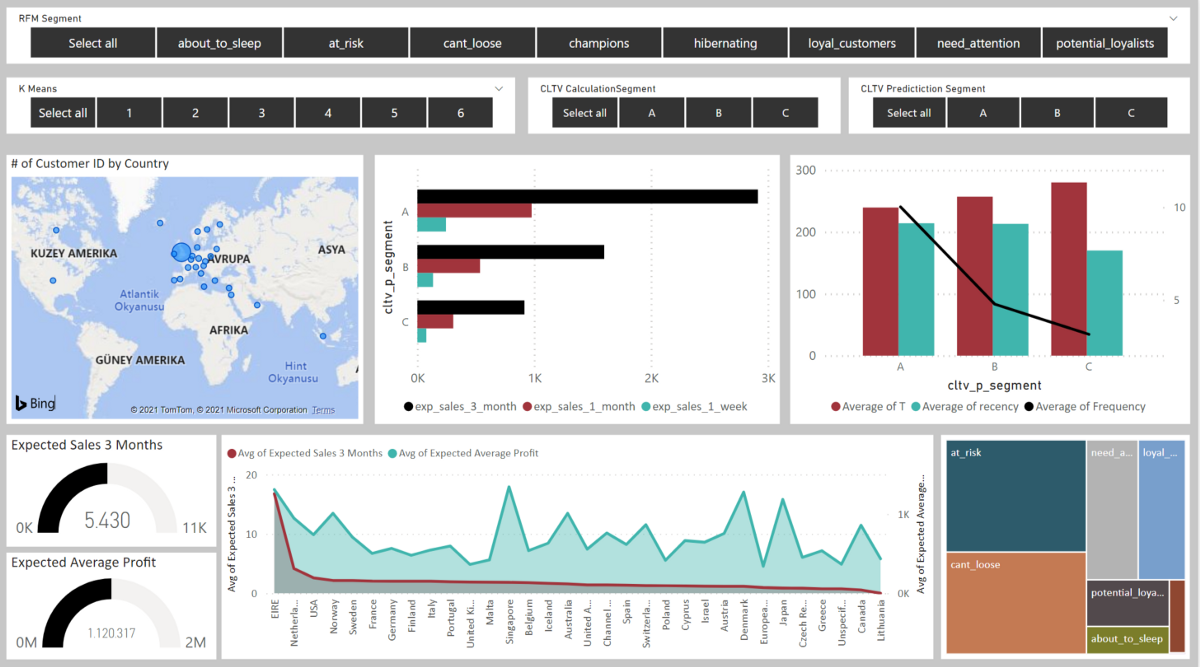
CLTV tahmini görselleştirmesi için ilk olarak Visualization kısmında yer alan Slicerı seçelim. Bu sayede elde ettiğimiz segmentleri kendileri özelinde veya birlikte seçerek adet ve tutarların değişimini görebiliriz. Slicerın yönünü yatay olarak çevirmek için görseli seçtikten sonra Formatta yer alan General → Orientation alanını Horizontal olarak seçelim.
Elde etmiş olduğumuz CLTV_Calculation ve CLTV_Prediction segmentleri sıralanırken A segmenti her ikisinde de en iyi müşteri grubudur.

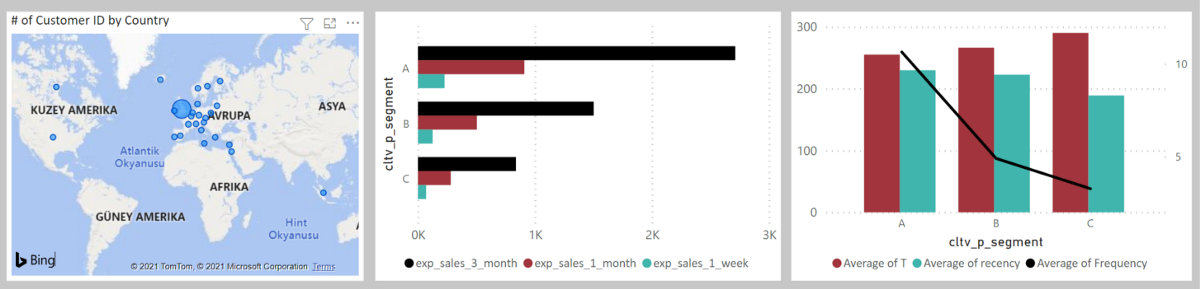
Harita için Customer ID adetleri, diğer tablo için beklenen haftalık (exp_sales_1_week), aylık (exp_sales_1_month) ve üç aylık (exp_sales_3_month) satış adetleri toplamı kullanılmaktadır. Son tablo içinde Shared Axiste cltv_p_segment, Column Valuesta ortalama müşteri yaşı (Tenure) ve Recency değeri, Line Values kısmında ise ortalama Frequency değeri karşılaştırılmıştır.
Son görsel satırda ise toplam dört görsel bulunmaktadır. İlk ikisinde Gauge görselinde belirli bir ölçünün durumu görselleştirilmiştir. Bunlar sırasıyla üç aylık beklenen satış adeti ve toplam beklenen karlılıktır. Diğerinde bu değerler ülkelere göre Area Chart kullanılarak görselleştirilmiştir. Son görselde ise RFM segmentleri Tree Map kullanılarak görselleştirilmiştir.

CRM Analitiği çalışmalarının ardındaki mantığı daha detaylı bir biçimde anlayabilmek için Miuul'un CRM Analitiği eğitimine katılabilirsiniz. Power BI yeteneklerinizi geliştirmek içinse Power BI ile Veri Analizi ve Veri Görselleştirme eğitimini inceleyebilirsiniz.
