RFM ile Müşteri Segmentasyonuna Kısa Bir Bakış
Recency, frequency ve monetary kelimelerinin baş harflerinden oluşan RFM, müşteri segmentasyonu için kullanılan bir tekniktir. Müşterilerin satın alma alışkanlıkları üzerinden gruplara ayrılmasında ve şirketlerin bu gruplar özelinde stratejiler geliştirilmesinde sıkça kullanılmaktadır. Müşteri ilişkileri yönetimi (Customer relationship management, CRM) çalışmaları kapsamında veriye dayalı aksiyon alma imkânı sağlayan RFM’i oluşturan kavramlara kısa bir göz atalım.
Recency
Bir müşterinin en son satın alım yaptığı dönemden bu yana geçen süreyi ifade eder. Gün bazlı bir inceleme yapılıyorsa, bir müşterinin recency değerinin 1 olması, 1 gün önce alışveriş yaptığını gösterir.
Frequency
Müşterinin yaptığı toplam işlem sayısı, yani satın alma sıklığıdır.
Monetary
Müşterinin şirkete bıraktığı parasal değeri ifade eder.
Müşterilerimizin alışveriş yaptıkları tarihleri, her alışverişlerinde aldıkları ürün sayısını ve alışverişinlerin tutar bilgilerini içeren bir veri setine sahip olduğumuzu ve bu veri setinden R, F ve M değerlerini hesapladığımızı düşünelim.
| Recency | Frequency | Monetary | |
| Müşteri 1 | 80 | 250 | 5200 |
| Müşteri 2 | 7 | 560 | 2300 |
| Müşteri 3 | 1 | 120 | 3000 |
| . | . | . | . |
| . | . | . | . |
| . | . | . | . |
| Müşteri N | 35 | 300 | 4500 |
Bu değerlere göre şirket için hangi müşterilerin daha değerli olduğu yorumu yapılabilir. Ancak hangi metrik veya metriklerin şirket için daha önemli olduğu kararlaştırılmalıdır. Örneğin, müşteriler yalnızca recency değerine göre değerlendirildiğinde Müşteri 3 diğer müşterilere kıyasla şirket için daha değerli gözükmektedir. Nitekim diğer müşterilere göre daha yakın zamanda alışveriş yapmıştır. Müşteriler yalnızca frequecy değerine göre incelendiğinde ise Müşteri 2 diğer müşterilere kıyasla şirket için daha değerli yorumu yapılabilir. Çünkü alışveriş yapma sıklığı diğer müşterilere oranla daha yüksektir. Son olarak müşteriler yalnızca monetary değerine göre incelenirse Müşteri 1’in şirket için daha değerli olduğu anlaşılır. Zira kendisi şirkete parasal anlamda en çok katkıyı sağlayan müşteridir.
Örnekte görülebildiği gibi değerlendirme metriğinin değişmesi, şirket için en değerli müşterinin de değişmesine neden olabilmektedir. Frekans değeri düşük olan ancak tek seferde çok yüksek maliyetli ürün satın alımı yapan bir müşteri olduğu gibi frekans değeri yüksek olan ancak tutar açısından düşük ürünler satın alan müşteriler de olabilmektedir. Bu nedenle bu metrikleri hem kendi içlerinde hem de birbirleri ile dikkatlice değerlendirmek gerekir. Tekil recency, frequency ve monetary metriklerinin RFM skorlarına çevrilmesi gerekmektedir. RFM skorlarınının kullanımı, metriklerin hepsinin aynı cinsten ifade edilebilmesini sağlar. Bir çeşit standartlaştırma işlemi olarak düşünülebilecek bu işlemde, metrikler hem kendi içlerinde hem de birbirleri arasında kıyaslanabilir bir formata gelmektedir.
Yukarıdaki tabloda verilen metrikler 1-5 ölçeğine indirgendiğinde aşağıdaki tablo elde edilebilir. Örneğin, Müşteri 1’in monetary skorunun 5 olması, müşterinin alışverişlerinin parasal değer olarak en yüksek seviyede olduğunu göstermektedir. Müşteri 2’nin frequency skorunun 5 olması ise ilgili müşterinin en sık alışveriş yapan müşteriler arasında yer aldığını göstermektedir. Aynı şekilde Müşteri 3’ün recency skorunun 5 olması ise ilgili müşterinin en yakın zamanda alışveriş yapan müşteriler arasında yer aldığını göstermektedir. Burada dikkat edilmesi gereken nokta, yukarıdaki ilk tabloda recency metriği içerisindeki en düşük değerin (yakın zamanda alışveriş yapan müşteriler) aşağıdaki tabloda en yüksek değer olan 5'e karşılık gelmesidir. Yani recency metriğinin düşük olması, müşterinin yakın zamanda alışveriş yaptığını ve bu nedenle recency skorunun yüksek olduğunu göstermektedir.
| Recency Score | Frequency Score | Monetary Score | |
| Müşteri 1 | 1 | 4 | 5 |
| Müşteri 2 | 4 | 5 | 4 |
| Müşteri 3 | 5 | 1 | 3 |
| . | . | . | . |
| . | . | . | . |
| . | . | . | . |
| Müşteri N | 2 | 4 | 4 |
Standartlaştırma işleminin ardından tekil skorların yan yana getirilmesi ile RFM skoru oluşturulur.
| Recency Score | Frequency Score | Monetary Score | RFM Score | |
| Müşteri 1 | 1 | 4 | 5 | 145 |
| Müşteri 2 | 4 | 5 | 4 | 454 |
| Müşteri 3 | 5 | 1 | 3 | 513 |
| . | . | . | . | . |
| . | . | . | . | . |
| . | . | . | . | . |
| Müşteri N | 2 | 4 | 4 | 244 |
RFM skorunun elde edilmesinin ardından her bir müşterinin şirket için değeri daha sağlıklı bir şekilde değerlendirilebilir. Örneğin, her metrik için en yüksek skor olan 5 değerlerinin bir araya gelmesi ile oluşan 555 RFM skoruna sahip müşterilerin şirket için en değerli müşteriler olduğu, her metrik için en düşük skor olan 1 değerlerinin bir araya gelmesi ile oluşan 111 RFM skoruna sahip müşterilerin ise şirket için en düşük önem kategorisindekiler olduğu yorumu yapılabilir. Ancak R, F ve M skorlarının çeşitli kombinasyonlarda bir araya gelebilmesi, müşterileri segmentlere ayırırken karşılaşılan zorluklardan biridir. Bu nedenle elde edilen skor kombinasyonlarının sayısını azaltarak, ayrımların mantıksal bir biçimde ve iş bilgisine daha uygun şekilde oluşturulabilmesine olanak sağlanmalıdır. Bunun için üç boyutlu RFM skorunu iki boyuta indirgemek bir çözüm olabilir.
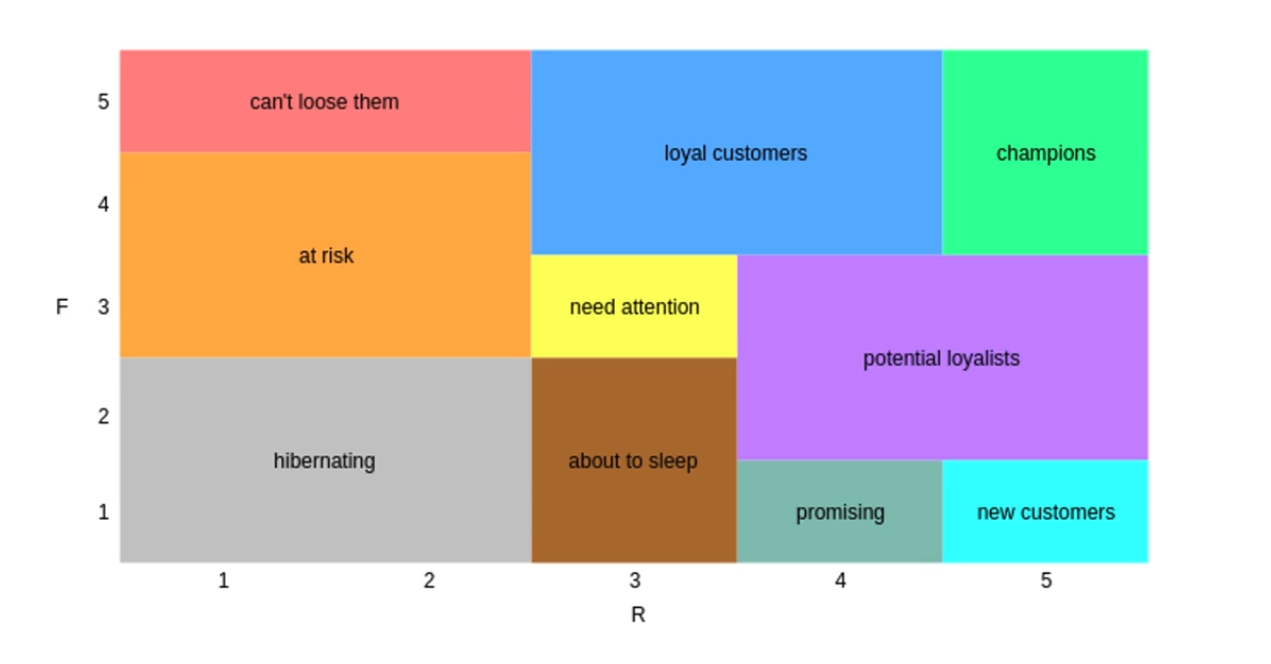
Aşağıdaki görselde X ekseni recency skorlarından ve Y ekseni frequency skorlarından oluşturulmuştur. Kısaca bir segmentasyon grafiği görülebilmektedir. İlgili örnekte monetary skorunun ihmal edilme sebebi CRM analitiği çalışmalarında müşterilerin şirket ile kurduğu ilişkilerde frekans (transaction-işlem) değerinin daha önemli bulunmasıdır. Şirket ile düşük frekansta bir ilişkisi olan bir müşteri için parasal değere bakmanın çok bir anlamı bulunmayabilir. Şirket için daha yüksek frekans değerine sahip bir müşteri daha çok satın alma işlemi gerçekleştirebilir. Bu nedenle üç boyut üzerinden incelenen RFM skoru RF olarak iki boyut üzerinden de değerlendirilebilir.
Görselde 10 farklı segment (can’t loose them, loyal customers, champions, at risk, need attention, potential loyalists, hibernating, about to sleep, promising ve new customers) görülebilmektedir. Her bir segment için farklı aksiyonlar gerekmektedir. Örneğin “can’t loose them” grubu çok uzun zaman önce alışveriş yapmış ancak alışveriş sıklığı yüksek müşterileri temsil etmektedir. Bu müşterilerin şirketi terk etme olasılığının yüksek olduğu gözükmektedir. Bu nedenle bu gruptaki müşterilere özel değerlendirmeler yaparak ilgili müşterileri şirkete tekrar kazandırmamız gerekmektedir. Aynı şekilde “need attention” ve “about to sleep” grubundaki müşterilere özel promosyonlar sunarak müşterileri tekrar alışveriş yapmaya teşvik etmek gerekir. Her bir grup için farklı stratejilerin geliştirmesi, müşteri terk etme oranının düşmesine ve yeni müşterilerin kazanılmasına olanak sağlamaktadır.
Buraya kadar teorik olarak anlattığımız RFM analizi ile müşteri segmentasyon uygulamasını Python ile bir örnek üzerinden inceleyelim.
İş problemi
Bir e-ticaret şirketi müşterilerini segmentlere ayırıp bu segmentlere göre pazarlama stratejilerini belirlemek istiyor.
Veri seti
Elimizde Online Retail II isimli, İngiltere merkezli çevrim içi bir mağazanın 01.12.2009 - 09.12.2011 tarihleri arasındaki satışlarını içeren bir veri seti bulunmaktadır. Veri setinde bulunan değişkenler ve açıklamaları aşağıdaki gibidir:
- InvoiceNo: Fatura numarası. Her işleme yani faturaya ait eşsiz numara. C ile başlıyorsa iptal edilen işlem anlamına gelmektedir.
- StockCode: Ürün kodu. Her bir ürün için eşsiz numarayı temsil etmektedir.
- Description: Ürün ismi.
- Quantity: Ürün adedi. Faturalardaki ürünlerden kaçar tane satıldığını ifade etmektedir.
- InvoiceDate: Fatura tarihi ve zamanı.
- UnitPrice: Ürün fiyatı (Sterlin cinsinden).
- CustomerID: Eşsiz müşteri numarası.
- Country: Ülke ismi. Müşterinin yaşadığı ülke.
# Çalışmalara gerekli kütüphaneleri import ederek başlayalım.
import datetime as dt
import pandas as pd
pd.set_option('display.max_columns',None) # Tüm sütunların görünmesini sağlar.
pd.set_option('display.float_format',lambda x: '%.3f' %x) # Float değerlerde noktadan sonraki üç basamağı gösterir.# Veriyi okuyalım.
# online_retail_II.xlsx dosyasında iki sayfa olduğu için sheet_name ile kullanacağımız sayfayı belirtiyoruz.
df_= pd.read_excel("online_retail_II.xlsx", sheet_name = "Year 2009-2010")
df = df_.copy()
df.head()Veri setinin ilk beş gözlemi aşağıdaki gibidir.

RFM analizi ile müşteri segmentasyon uygulaması için sırası ile aşağıdaki adımlar uygulanacaktır:
- Veriyi anlama (Data understanding)
- Veri hazırlama (Data preparation)
- RFM metriklerinin hesaplanması (Calculating RFM metrics)
- RFM skorlarının hesaplanması (Calculating RFM scores)
- RFM segmentlerinin oluşturulması ve analiz edilmesi (Creating & analysing RFM segments)
Veriyi anlama
Veriyi anlamak, bir problemin çözümü için atılan ilk ve en önemli adımlardandır. Veri setinin boyutu, veri setinde yer alan eşsiz ürün sayısı, hangi üründen kaçar adet satıldığı gibi değerlerin incelenmesi problemin çözümü için önemli ipuçları sağlamaktadır.
Örnek uygulamanın takip edilebilirliğinin daha kolay olması adına, elde edilen sonuçlar her bir kodun devamında yorum olarak gösterilmiştir. Veri seti 525461 gözlem birimi ve 8 değişkenden oluşmakta, Description ve Customer ID değişkenlerinde null değerler yer almakta ve veri setinde 4681 adet eşsiz ürün bulunmaktadır. Her bir üründen kaçar adet olduğu bilgisi de ayrıca yorum olarak gösterilmiştir.
# Veri setimizin boyutuna bakalım:
df.shape # (525461, 8)
# Veri setindeki her bir değişkende kaç null değer olduğunu tespit edelim:
df.isnull().sum()
# Invoice 0
# StockCode 0
# Description 2928
# Quantity 0
# InvoiceDate 0
# Price 0
# Customer ID 107927
# Country 0
# dtype: int64
# Eşsiz ürün sayısını inceleyelim:
df["Description"].nunique() # 4681
# Hangi üründen kaçar adet olduğu bilgisine erişelim:
df["Description"].value_counts().head()
# WHITE HANGING HEART T-LIGHT HOLDER 3549
# REGENCY CAKESTAND 3 TIER 2212
# STRAWBERRY CERAMIC TRINKET BOX 1843
# PACK OF 72 RETRO SPOT CAKE CASES 1466
# ASSORTED COLOUR BIRD ORNAMENT 1457
# Name: Description, dtype: int64Peki en çok hangi ürün sipariş edilmiştir ve fatura başına toplam kazanç nedir? En çok sipariş edilen ürünü bulmak için ürün kırılımında quantity miktarlarının toplam değerleri dikkate alınmalıdır.
# En cok sipariş edilen ürün hangisi?
df.groupby("Description").agg({"Quantity":"sum"}).sort_values("Quantity",ascending=False).head()
# Quantity
# Description
# WHITE HANGING HEART T-LIGHT HOLDER 57733
# WORLD WAR 2 GLIDERS ASSTD DESIGNS 54698
# BROCADE RING PURSE 47647
# PACK OF 72 RETRO SPOT CAKE CASES 46106
# ASSORTED COLOUR BIRD ORNAMENT 44925
df["Invoice"].nunique() # 28816
# Fatura başına toplam kaç para kazanılmıştır?
# Bunu bulabilmek için TotalPrice adında yeni bir değişken tanımlıyoruz:
df["TotalPrice"] = df["Quantity"]*df["Price"]
df.head()Aşağıda görülebildiği gibi dataframede problemin çözümü için faydalı olabileceği düşünülen TotalPrice isminde yeni bir değişken oluşturulmuş olup bu değişken fatura başına kazanılan toplam parayı ifade etmektedir.

Veriyi hazırlama
Veri, analiz için hazırlanırken eksik değerlerin durumu özel olarak incelenmelidir. Bu problem özelinde eksik değerler yanı sıra ‘C’ ile başlayan ve iade edilen ürünleri temsil eden satırların da veri setinden çıkartılması uygun görülmüştür.
# Description ve Customer ID değişkenlerindeki null satırları silelim:
df.dropna(inplace=True)
# İade edilen faturaların başında C ifadesi bulunmaktadır. Bunları dataframeden çıkaralım:
df = df[~df["Invoice"].str.contains("C",na=False)]# Verinin betimsel analizi için:
df.describe().T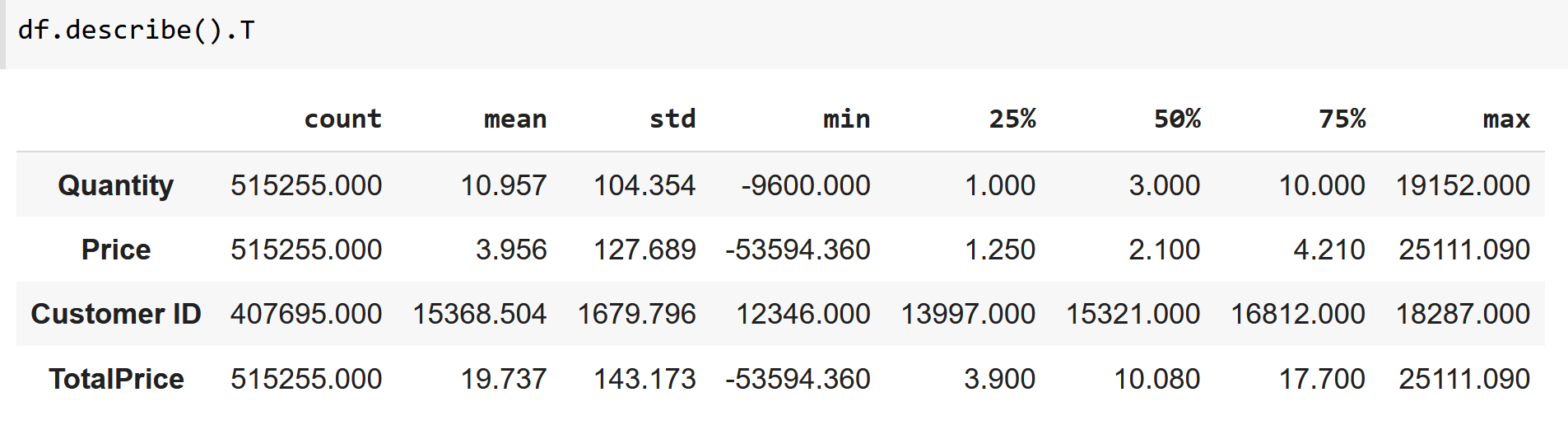
Tabloda görülebildiği gibi Quantity ve Price değişkenlerinin minimum değerleri negatif. Normal şartlarda ürün adedi ve tutarı negatif olamayacağı için ilgili satırlar hatalı veri olarak değerlendirilmiş ve veri setinden çıkartılmıştır.
# Quantity ve Rrice değerleri 0’dan küçük olamayacağı için bu satırları da veri setinden çıkaralım:
df = df[(df['Quantity'] > 0)]
df = df[(df['Price'] > 0)]# Tekrar verinin betimsel analizini inceleyelim. Eksi değerlerin veri setinden çıktığı görülebilmektedir.
df.describe().T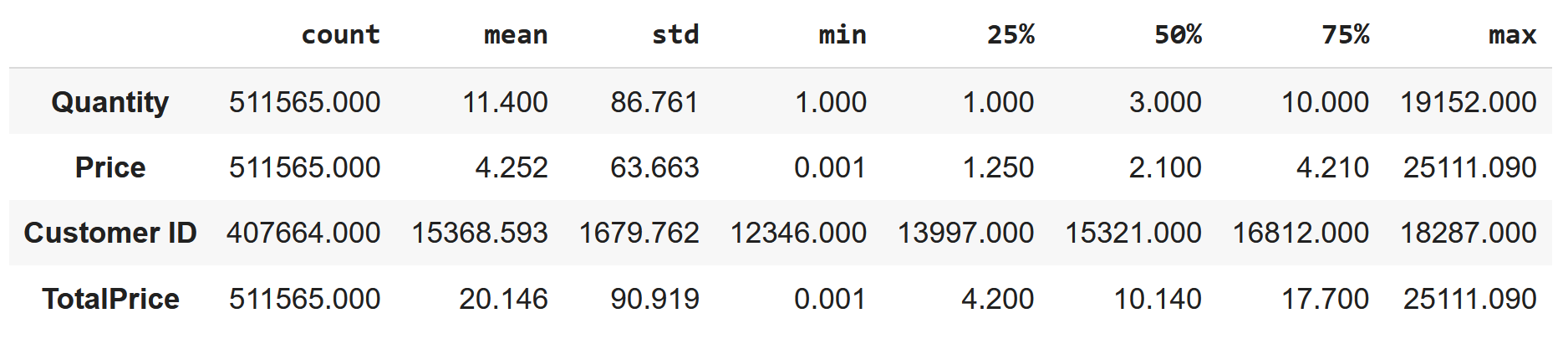
RFM metriklerinin hesaplanması
Müşterilerin şirket için değerlerini öğrenebilmek için Recency, Frequency ve Monetary değerlerinin hesaplanması gerekmektedir. InvoiceDate, Invoice ve TotalPrice değişkenleri kullanılarak ilgili değerler hesaplanabilir.
# Recency, Frequency, Monetary
# Veri setindeki son fatura tarihine göre bir analiz tarihi belirleyelim:
df["InvoiceDate"].max() # Timestamp('2010-12-09 20:01:00')
today_date = dt.datetime(2010, 12, 11)
type(today_date) # datetime.datetime
# rfm adında yeni bir dataframe oluşturalım ve R, F, M metriklerini atayalım:
rfm = df.groupby('Customer ID').agg({'InvoiceDate': lambda InvoiceDate: (today_date - InvoiceDate.max()).days,
'Invoice': lambda Invoice: Invoice.nunique(),
'TotalPrice': lambda TotalPrice: TotalPrice.sum()})
rfm.head()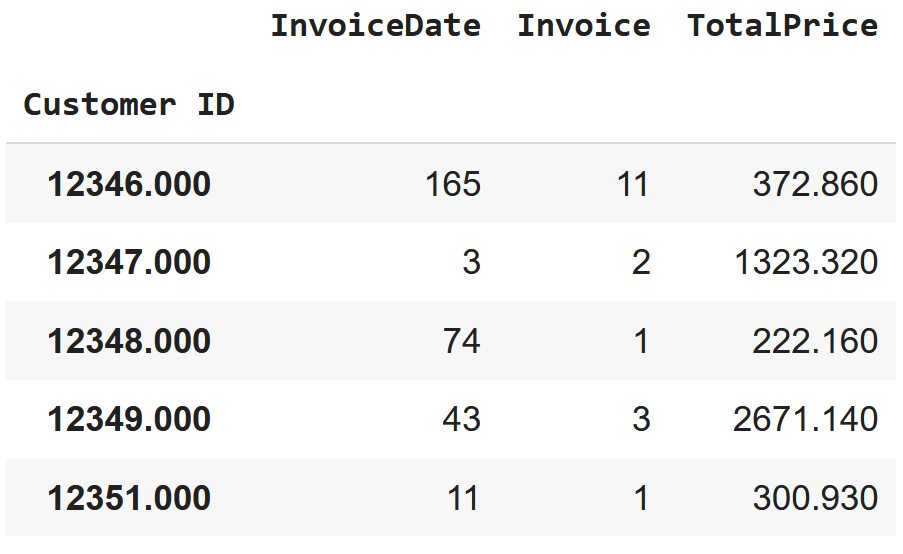
# rfm dataframeinin kolon isimlerini güncelleyelim:
rfm.columns = ['Recency', 'Frequency', 'Monetary']
# rfm dataframeine ait değişkenlerin istatistiki bilgilerini inceleyelim:
rfm.describe().T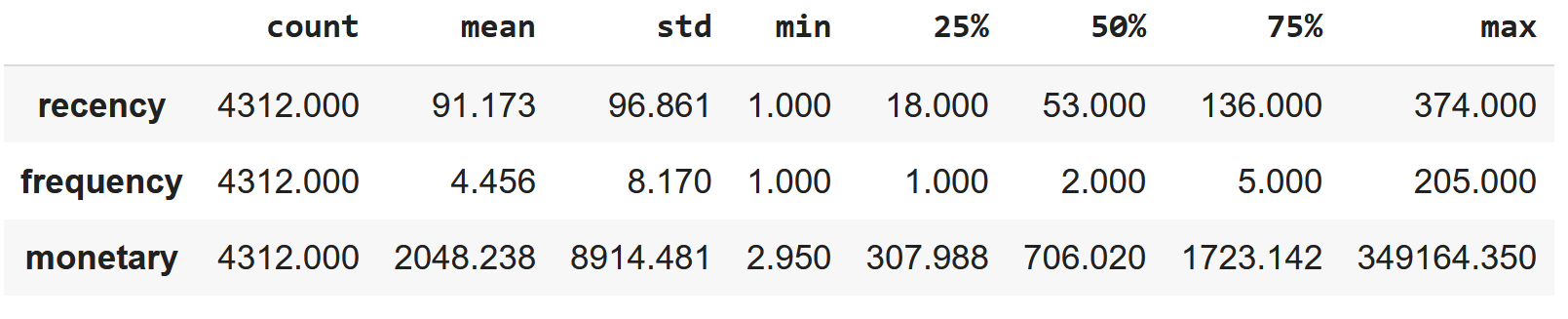
Görülebildiği üzere her bir müşteri için Recency, Frequency ve Monetary değerleri hesaplanmıştır. İlerleyen aşamada ilgili değerler Recency skoru, Frequency skoru ve Monetary skoruna dönüştürülecektir.
RFM skorlarının hesaplanması
R, F ve M değerleri, değişkeni özelliklerine göre eşit boyutlu parçalara ayırmaya yarayan qcut fonksiyonu yardımı ile 5 eşit parçaya ayrılarak Recency skoru, Frequency skoru ve Monetary skoruna dönüştürülür. Burada dikkat edilmesi gereken nokta Frequency ve Monetary skorlarının 5’ten 1’e doğru etiketlenmesi, Recency skorunun ise 1’den 5’e doğru etiketlenmesidir. Yazının ilk bölümlerinde bu durum Recency değerinin bir müşterinin en son alışveriş yaptığı tarihin üzerinden geçen sürenin az olmasının değeri ile açıklanmıştı. Yani düşük olan Recency değeri, Recency skoru haline getirildiğinde yüksek bir değere sahip olup şirket için daha yüksek önem derecesine sahip olacaktır.
Tekil R, F ve M skorlarının bütüncül bir RFM Skoru haline getirilmesi gerekmektedir. Ancak örnekte, daha önce bahsedildiği gibi uygulamanın daha kolay yapılabilmesi ve anlaşılabilmesi adına yalnızca Recency skoru ve Frequency skoru kullanılarak bir RFM skoru hesaplanmıştır.
rfm["Recency_score"] = pd.qcut(rfm['Recency'], 5, labels=[5, 4, 3, 2, 1])
rfm["Frequency_score"] = pd.qcut(rfm['Frequency'].rank(method="first"), 5, labels=[1, 2, 3, 4, 5])
rfm["Monetary_score"] = pd.qcut(rfm['Monetary'], 5, labels=[1, 2, 3, 4, 5])
rfm["RFM_SCORE"] = (rfm['Recency_score'].astype(str) + rfm['Frequency_score'].astype(str))
rfm.head()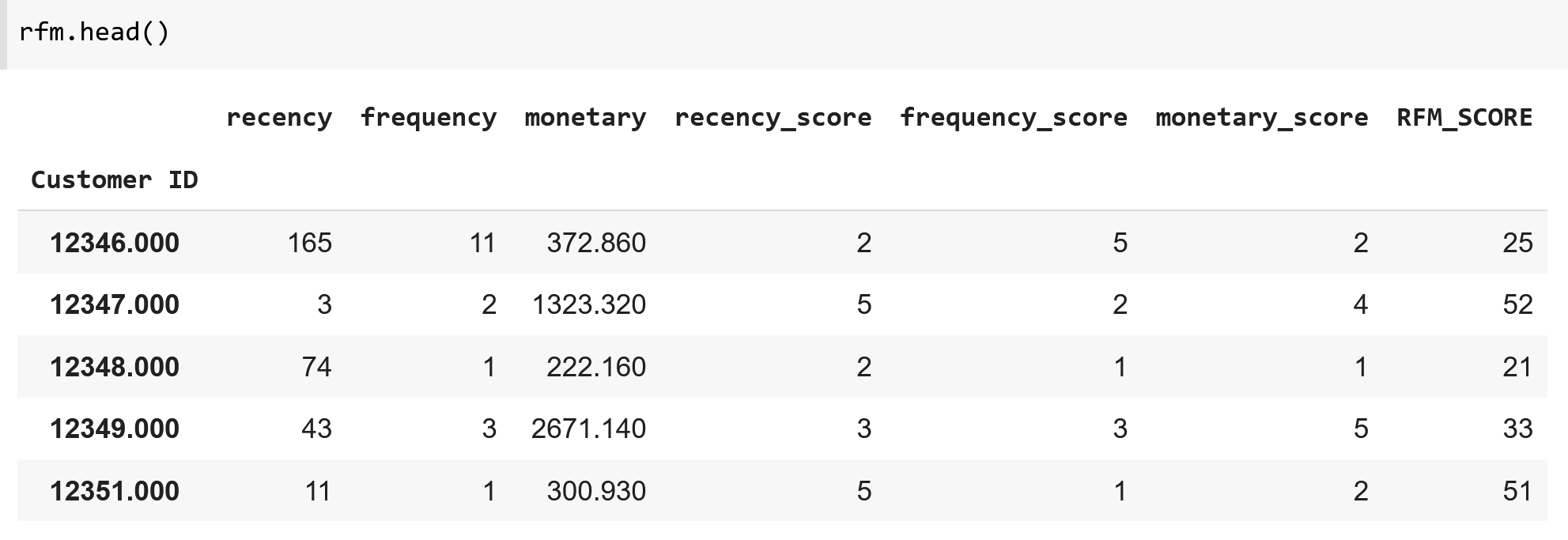
Yukarıdaki tabloda üç boyutlu RFM skoru yerine, parasal değeri temsil eden Monetary skorunun göz ardı edilmesi ile oluşturulan iki boyutlu RFM skorlarına ilişkin bir kesit görülebilmektedir. 12346 numaralı müşteri ile 12348 numaralı müşterinin RFM skoru, diğer müşterilere oranla en son alışveriş yaptıkları tarihin daha eski bir tarih olması nedeniyle 2 rakamı ile başlamaktadır. Benzer şekilde 12346 numaralı müşteri daha sık alışveriş yaptığından F skoru 5 iken 12348 numaralı müşterinin alışveriş sıklığının daha düşük olması F skorunun 1 olmasına neden olmuştur. Sonuçta olarak 12346 numaralı müşteri için RFM skoru 25, 12348 numaralı müşteri içinse 21 olarak elde edilmiştir.
RFM segmentlerinin oluşturulması ve analiz edilmesi
RFM skorlarının hesaplanmasının ardından müşteriler artık belirli segmentlere ayrılabilir. Bu aşamada her bir müşterinin RFM skorunun şirket açısından ne anlam ifade ettiğinin dikkatli bir şekilde irdelenmesi gerekmektedir. Aşağıda örnek olarak bir segmentasyon işlemi görülebilmektedir. Örneğin iki boyutlu RFM skoru 41 olan müşteriler “promising” (umut vadeden) grubuna dahil edilirken 33 olan müşteriler “need attention” (dikkat gerektiren) grubuna dahil edilmiştir.
# RFM segmentlerinin oluşturulması
seg_map = {
r'[1-2][1-2]': 'hibernating',
r'[1-2][3-4]': 'at_Risk',
r'[1-2]5': 'cant_loose',
r'3[1-2]': 'about_to_sleep',
r'33': 'need_attention',
r'[3-4][4-5]': 'loyal_customers',
r'41': 'promising',
r'51': 'new_customers',
r'[4-5][2-3]': 'potential_loyalists',
r'5[4-5]': 'champions'
}
# RFM skorlarını isimlendirelim
rfm['segment'] = rfm['RFM_SCORE'].replace(seg_map, regex=True)
rfm.head()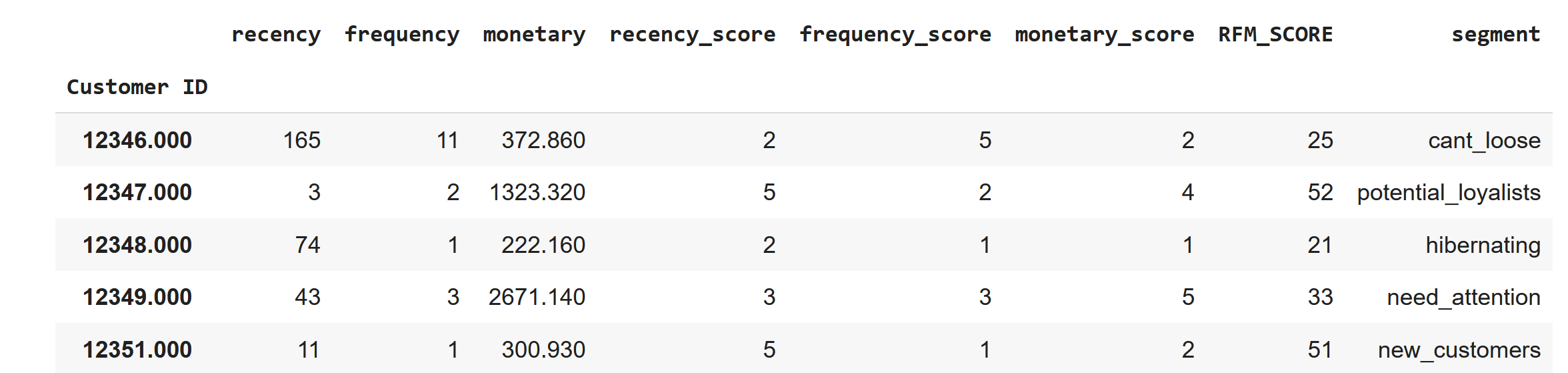
Bu aşamadan sonra şirketin, her bir segment özelinde farklı stratejiler geliştirmesi gerekmektedir. Örneğin “can’t loose” segmentindeki ilk beş gözlemi inceleyelim:
rfm[rfm["segment"]=="cant_loose"].head()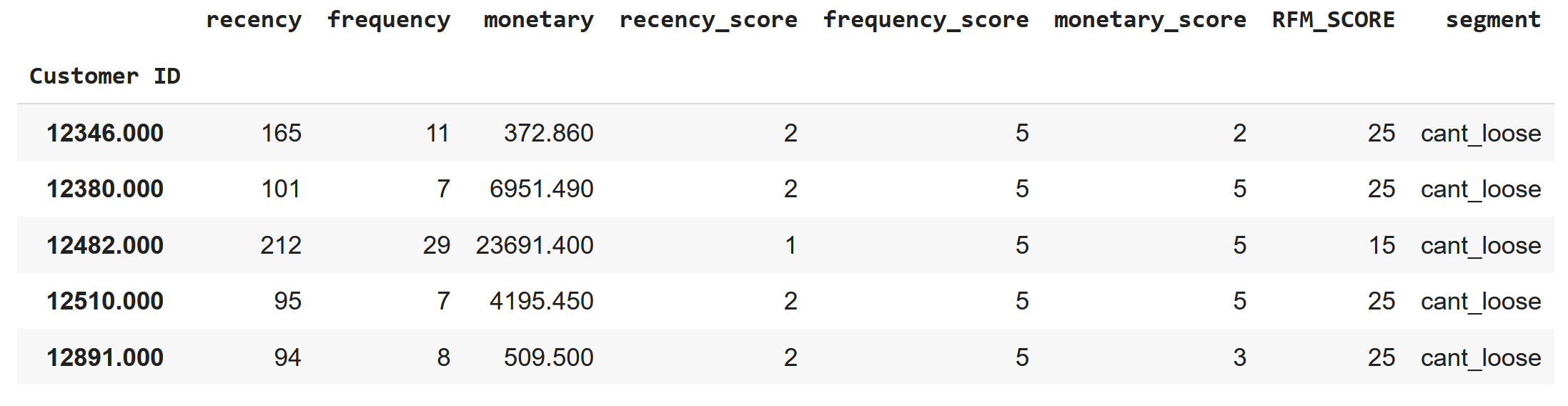
Aynı şekilde “new customers” segmentine ait gözlemleri inceleyelim:
rfm[rfm["segment"] == "new_customers"].head()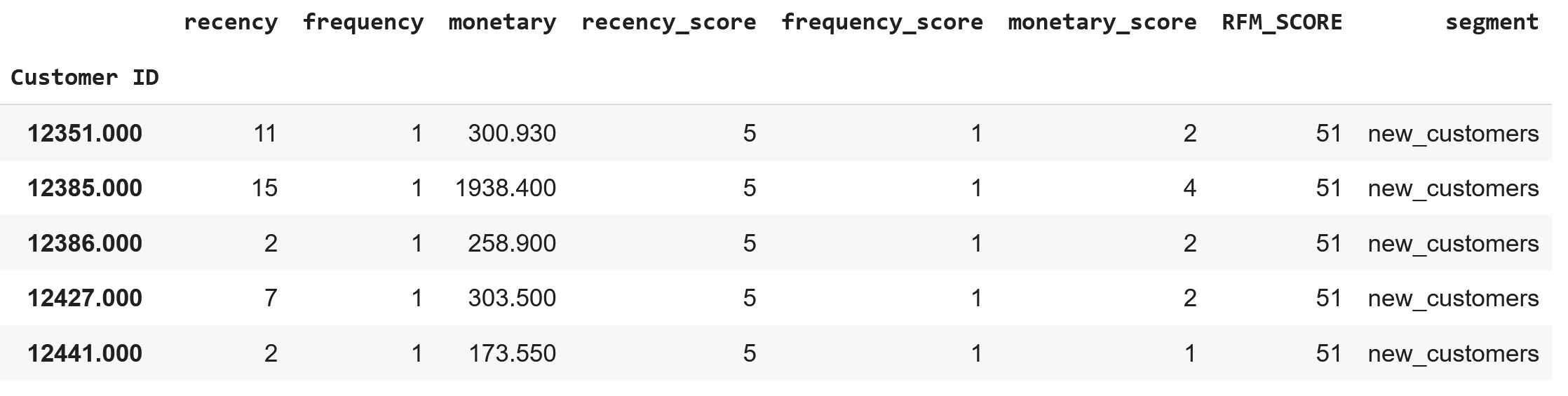
Artık şirket belirli bir segmentten müşterilere ait bilgileri ayrı bir .csv dosyasına aktarılabilir ve o segment özelinde çeşitli stratejiler geliştirebilir. Örnek olarak “new customers” segmentindeki müşterilerin bilgilerini yeni bir dataframede görüp verileri bir .csv dosyası olarak kaydedelim:
new_df = pd.DataFrame()
new_df["new_customer_id"] = rfm[rfm["segment"] == "new_customers"].index
new_df["new_customer_id"] = new_df["new_customer_id"].astype(int)
new_df.to_csv("new_customers.csv")
rfm.to_csv("rfm.csv")Bu yazıda RFM kavramı üzerinde durup şirketler için RFM'in önemi ve bu skorun nasıl hesaplandığını ele aldık. Teorik bilginin yanında uçtan uca bir uygulama ile RFM'i yakından tanıdık. RFM konusunda daha detaylı bilgiye erişmek isterseniz Miuul’un sunmuş olduğu CRM Analitiği programını inceleyebilirsiziniz. Kariyer rotanızı veri bilimine çevirdiyseniz Data Scientist Path’e göz atabilirsiniz.
Kaynaklar
- Miuul, CRM Analitiği
- Miuul, Data Scientist Path
- Techtarget, RFM analysis (recency, frequency, monetary)
