Sarmal yöntemler ile makine öğrenmesinde değişken seçimi
Sarmal yöntemler, veri seti içerisindeki değişken alt küme kombinasyonlarından hangisinin makine öğrenmesi modelinde daha iyi performans göstereceğini bulmak için tüm olası değişken kombinasyonlarını tarayarak çalışmaktadır. Tüm değişken kombinasyonlarını deneyeceği için hesaplama açısından pahalıdır. Bu yöntem greedy algoritması olarak da adlandırılır.
Olası kombinasyonların performansı değerlendirilirken çeşitli sınıflandırıcılar ve kriterler kullanılır. Makine öğrenmesi probleminin türüne göre değerlendirme metrikleri veya seçilecek değişken sayısı bunlara birer örnektir. Eğer elimizde bir sınıflandırma problemi varsa accuracy, recall, precision ve f1-score gibi metrikler kullanılabilir. Hangi sarmal yöntemin kullanıldığına göre değişken çıkartarak veya ekleyerek seçilen sınıflandırma metriğinde en iyi performansı gösteren değişken kombinasyonu bulma işlemi, belirlenen değişken sayısı kriterine ulaşana kadar sürer.
Sarmal yöntemler step forward, step backward ve exhaustive search olmak üzere üç başlıkta değerlendirilebilir.
Step forward feature selection
Çalışma tek bir değişkenden oluşan tüm alt kümeler değerlendirilerek başlar. Her bir feature için modeller kurulur. Bütün modellerin performansları değerlendirilir ve en iyi performansı gösteren değişken seçilir.
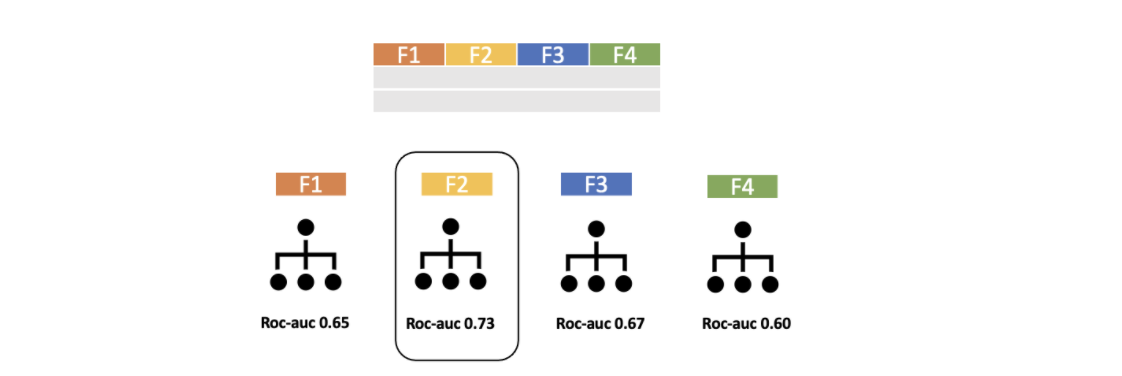
Seçilen değişkene veri kümesindeki diğer değişkenler tek tek eklenerek yeni alt kümeler oluşturulup, yeniden modeller kurulur. Bütün modellerin performansı değerlendirilip yine en iyi performansı gösteren seçilir.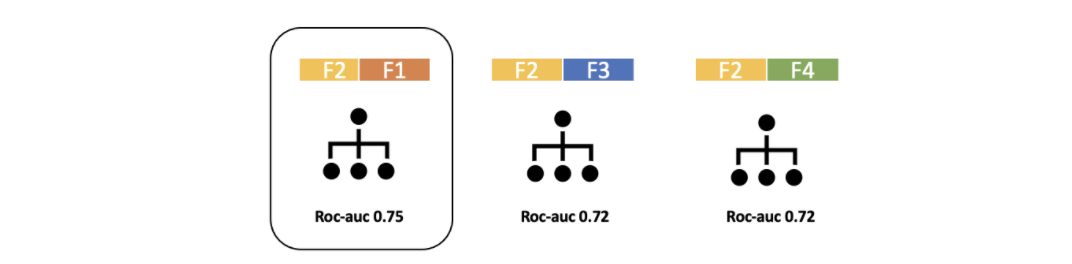
Bu aşamalar belirlenen kritere ulaşılana kadar devam eder.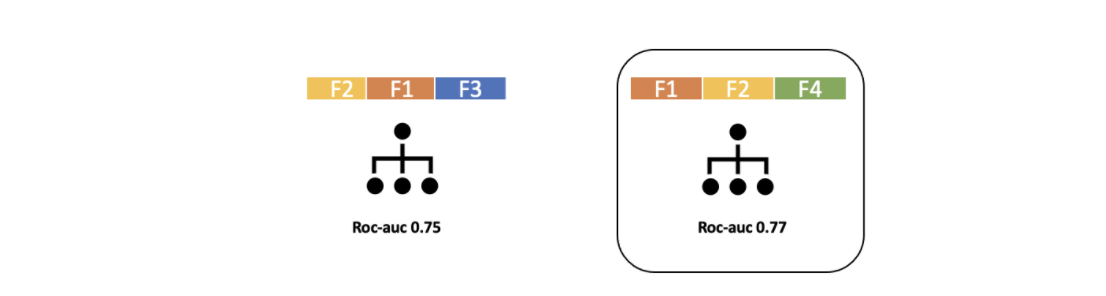
Örnek uygulama: Step forward
Sarmal yöntemleri uygulamak için Python'daki MLXtend kütüphanesini kullanacağız.
Uygulamada house price veri seti üzerinden ilerleyeceğiz. Çalışma kapsamında ev fiyat tahmin modeli oluşturulması istenmektedir.
İlk olarak gerekli kütüphaneleri import ediyor ve veri ön işlemelerini gerçekleştiriyoruz. Basit şekilde ilerlemek istediğim için sadece sayısal değişkenleri seçip, boş değer içeren değişkenleri veri setinden çıkarttım. Veri setinin son hali 1460 gözlem, 34 değişkenden oluşmakta.

Çıktı:

Veri setini eğitim ve test olarak ikiye ayırıyoruz. Step forward feature selection için MLXtend kütüphanesinden SFS’yi kullanıyoruz. SFS’nin içerisinde belirtilmesi gereken parametreler:
- Kullanılacak model
- k_features: Durdurma kriteri. Belirtilen sayıda değişkene ulaşıldığında durur.
- forward: True durumunda forward selection yapılacağını, False durumunda ise backward selection yapılacağını ifade eder.
- scoring: Değerlendirme metriği.
- cv: Cross validation için fold değeri
Aşağıdaki kod incelendiğinde uygulamada random forest algoritmasının kullanıldığı, forward selection yapıldığı, feature sayısı 20'ye ulaştığında işlemin duracağı, değerlendirme metriğinin r2 olduğu ve cross validation için fold değerinin 5 olduğu görülebilir.

Çıktı:
Çıktıyı incelediğimizde 17. özellik eklendikten sonra performansın düştüğü görülüyor. 18, 19 ve 20. özelliğin eklenmesi modelin performansını arttırmadı.
plotting.plot_sequential_feature_selection ile sonuçların performansını görselleştirebiliriz.
Çıktı: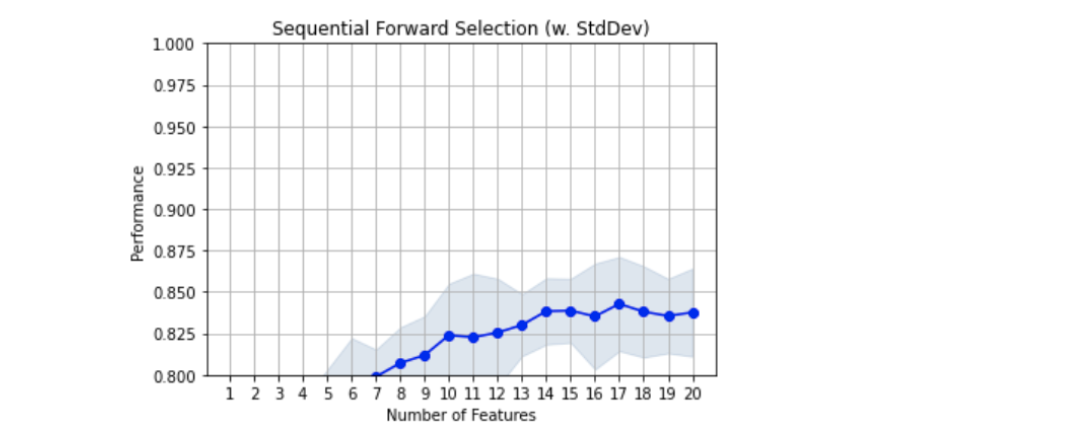
subsets_ aracılığıyla gerçekleşen 20 adımın her birinde seçilen değişkenleri görebiliriz.

Çıktı:
k_features 20 seçildiği için 20 değişken seçilene kadar süreç devam etmekte ama çıktı olarak yukarıda sadece ilk 8 adımı gösterdim. İncelediğimizde ilk adımda tek başına en iyi performansı gösteren değişkenin OverallQual olduğunu görüyoruz. OverallQual değişkeniyle beraber en iyi model performansını gösteren ikinci değişken ise GarageCars. Her adımda model performansını en iyi yapan değişken seçilerek devam edilmekte.
En iyi performans 17 değişken ile gerçekleşmişti. 17. adımdaki değişkenlerin isimlerini bir listeye atalım.
Çıktı:
Veri setindeki tüm değişkenlerle oluşturulan model ile seçilen 17 değişkenle oluşturulan modelin performansını kıyaslayalım.

Çıktı: Çıktı:
Çıktı:

17 değişkenle oluşturulan modelin 33 değişkenle oluşturulan model kadar iyi performans gösterdiğini gözlemlemiş olduk.
Step backward feature selection
Bu yöntemde tüm değişkenlerle tek bir model oluşturulur ve ardından veri setindeki tüm değişkenler ilk modelden ayrı ayrı çıkarılarak yeni modeller oluşturulur.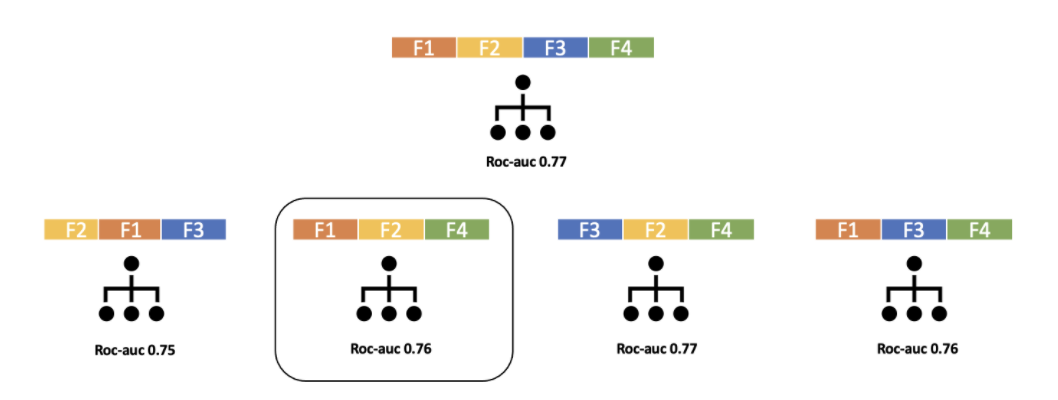
Çıkarıldıktan sonra en iyi model performansını sağlayan değişken çıkarılacak ilk değişken olarak seçilir. Onun çıkarıldığı model üzerinden işlem aynı şekilde tekrarlanır.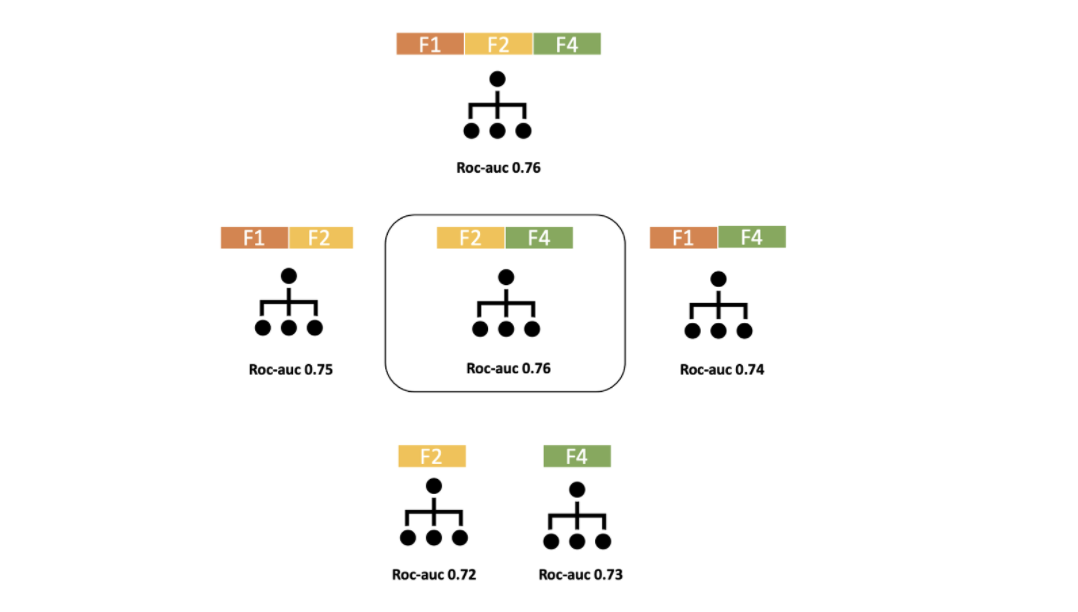
Örnek uygulama: Step backward
Step backward feature selection uygulamasını da house price verisi üzerinde gerçekleştireceğiz. Gerekli kütüphaneleri yükleyip veriyi hızlı şekilde uygulama yapabileceğimiz bir hale getiriyoruz.
Çıktı:

Veri setini train ve test olarak ayırıyor ve random forest algoritmasını kullanarak backward selection yapıyoruz. Değişken sayısı 13'e ulaştığında sona erecek.
Çıktı:

plotting.plot_sequential_feature_selection ile sonuçların performansını görselleştirelim.
Çıktı:
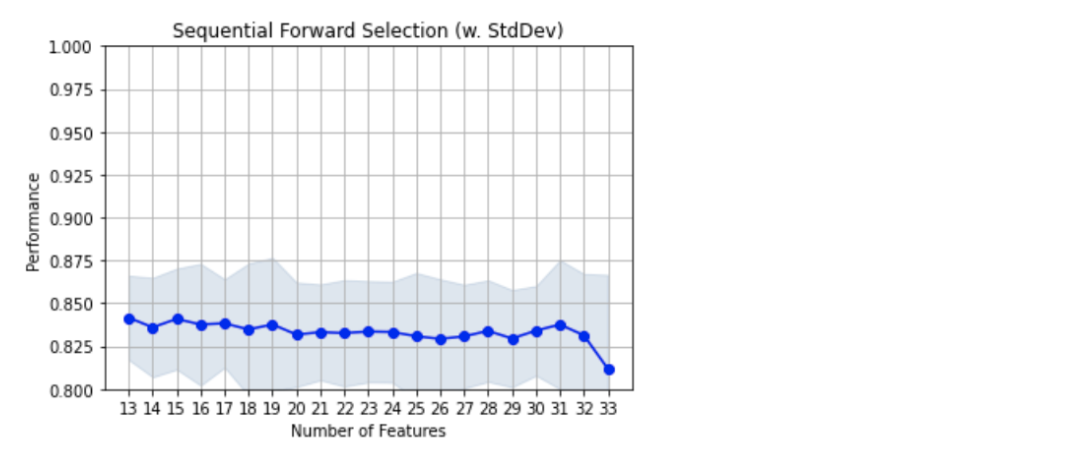
Değişken sayısını 13'e indirmenin model performansında önemli bir azalmaya sebep olmadığını görüyoruz. 13'ün altı da gözlemlenebilir.
Seçilen 13 değişkenin hangi değişkenler olduğuna bakalım.

Çıktı:
Kalan 13 değişkenle kurulan model ile tüm değişkenlerin olduğu modeli karşılaştıralım.
Çıktı:
Çıktı:
Performanslar birbirine hayli yakın.
Exhaustive Feature Selection
Bu yöntemde veri setindeki tüm değişkenlerin olası tüm kombinasyonlarının modelleri oluşturulur ve performansları değerlendirir.
Dört değişkenden oluşan bir veri seti olsun. Bir değişkenli olası tüm kombinasyonlar oluşturulur ve modellenir.
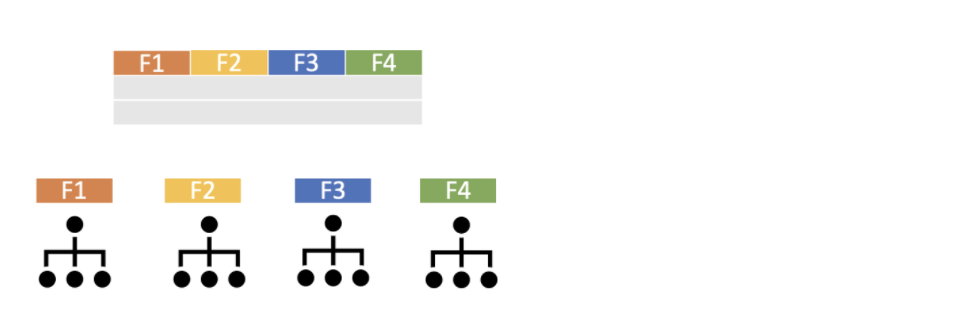
İki değişkenli olası tüm kombinasyonlar oluşturulur ve modellenir.
Üç değişkenli olası tüm kombinasyonlar oluşturulur ve modellenir.
Dört değişkenli olası tüm kombinasyonlar oluşturulur ve modellenir.

Oluşan tüm kombinasyonlardan en iyi performansı gösteren değişken kombinasyonu seçilir.
Örnek uygulama: Exhaustive
House price verisi üzerinde devam ediyoruz. Gerekli kütüphaneleri yükleyip, veriyi uygulamaya hazır hale getiriyoruz.
Çıktı:

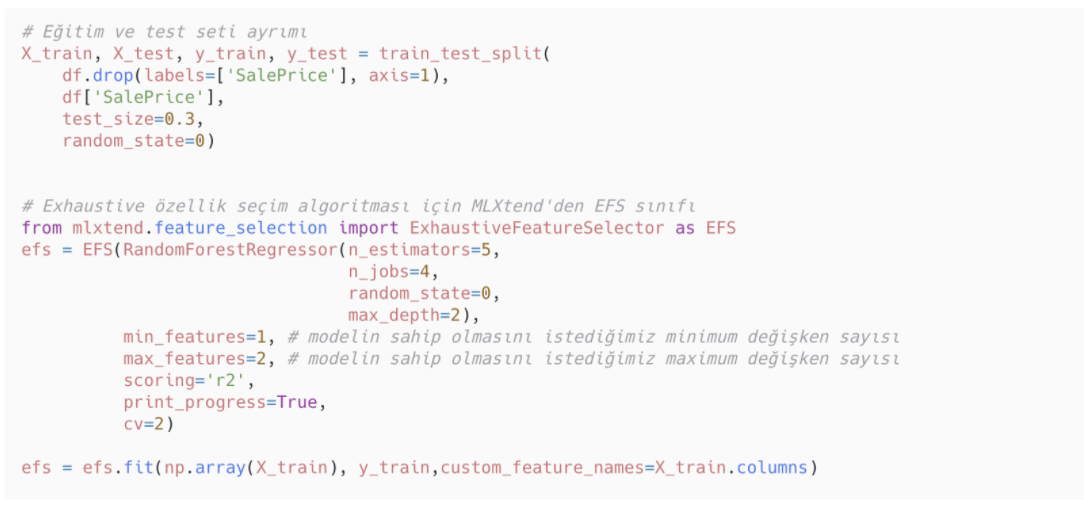
Veri setini train ve test olarak ikiye ayırıyoruz. Exhaustive feature selection için MLXtend kütüphanesinden EFS’yi kullanıyoruz. EFS’nin içerisinde belirtilmesi gereken parametreler:
- Kullanılacak model
- min_features: Modelin sahip olması istenen minimum değişken sayısı
- max_features: Modelin sahip olması istenen maksimum değişken sayısı
- scoring: Değerlendirme metriği
Çıktı:

Minimum 1 ve maksimum 2 değişkenli tüm olası değişken kombinasyonları tespit edildi. Çıktıda da görüldüğü gibi toplam kombinasyon sayısı 561.
En iyi kombinasyonu bulmak için best_idx_’i kullanalım.

Çıktı: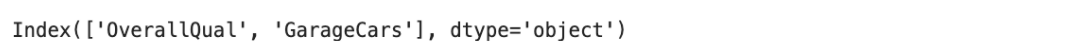
En iyi değişken kombinasyonuyla kurulan model ile tüm değişkenlerin olduğu modeli karşılaştıralım.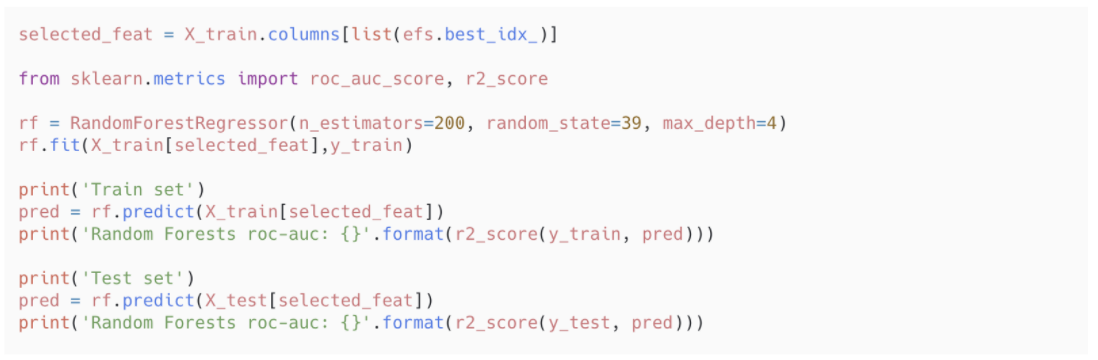
Çıktı:
Çıktı:
Exhaustive değişken seçimi hesaplama açısından pahalı olduğu için maksimum değişken sayısını az seçtim. Bu nedenle modelin performansının düşük olması kaçınılmaz. Eğer isterseniz maksimum değişken sayısını değiştirerek performanstaki değişimi daha iyi gözlemleyebilirsiniz.
Machine Learning hakkında daha geniş kapsamlı bilgiye erişmek ve kariyerinizde Machine Learning bilginizle fark yaratmak isterseniz Miuul'un sunduğu Machine Learning Engineer Path eğitimine göz atabilirsiniz.
Kaynaklar
