Veritabanlarında Normalizasyonu Doğru Yapmak Neden Önemli?
“Database” kavramı, adı üstünde verinin “base” olarak tanımlandığı yerdir. Uygulamalar bu veritabanlarına bağlanır ve buradan sorgular ile veriler çekilir. Bu durumda veritabanını tasarlarken doğru tanımlamak aslında tahmin edildiğinden çok daha önemlidir.
Bir yazılım içinde string olarak tanımlayıp geçtiğimiz bir veri tipi, söz konusu veritabanı olduğunda birden fazla şekilde tanımlanabilir. Ne yazık ki çoğu zaman burada örneğin string ifadeler için nchar, tamsayı ifadeler için de bigint denip geçilir. Bu yazıda yapılan bu yanlışın özellikle büyük verilerde nasıl sorunlara yol açacağını gösteriyor olacağım.
Örnek Uygulama
Elimizde örnek olarak Türkiye Cumhuriyeti nüfus veritabanının bir tablosu olan kişi bilgilerinin tutulduğu tabloyu çok basit bir şekilde tasarlama görevi olduğunu düşünelim.
Öncelikle kayıt sayımız hayatta olan 85 milyon kişi. Hayattakilerin soyağaçlarını ve hayatını kaybedenleri vs. göz önünde bulundurduğumuzda 200 milyon satırlık bir tablo öngörebiliriz.
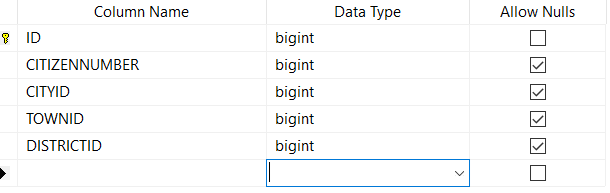
Her şeyden önce veritabanımızda otomatik artan bir ID alanımız olsun. Bir de vatandaşlık numarası. Diğer alanlar ise basitçe aşağıdaki gibi.
ID : Otomatik artan satır primary key'i
CITIZENNUMBER : 11 karakterlik vatandaşlık numarası
CITYID : Nüfusa kayıtlı olduğu şehrin ID numarası
TOWNID : Nüfusa kayıtlı olduğu ilçenin ID numarası
DISTRICTID : Nüfusa kayıtlı olduğu mahallenin ID numarası
NAMESURNAME : Kişinin ad soyad bilgisiKonunun özünden uzaklaşamamak için tabloyu çok geniş tutmuyorum. Ama yanlış tasarımın sonuçlarını görmek için sadece bir tablo ve sadece bu kadar alan bile yeterli aslında.
ID değerinden başlayalım. İlk aklımıza gelen otomatik artan bir alan olduğu için integer işaretlemek. Ancak kayıt sayısı 200 milyon olunca burayı ancak bigint kurtarır diyerek bigint seçiyoruz.
Sonraki alanımız CITIZENNUMBER. Türkiye’de bu alan 11 karakterlik bir sayı. Yeterince büyük olduğu için burasını da bigint yapıyoruz.
El alışkanlığı diğer tamsayı alanları da bigint yaptık mı tamamdır.
Peki şimdi bir hesap yapalım. Bigint türünde bir alan hafızada 8 B kaplar. Yani biz oraya 1 bile yazsak türü bigint olduğu için gerek diskte gerekse RAM'de 8 B’lık yer kaplar.
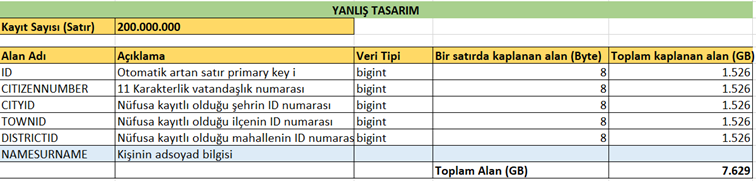
Kaba bir hesap ile aşağıdaki gibi 200 milyon satırlık bir tabloda tüm tamsayı alanları el alışkanlığı deyip bigint yaptığımızda sadece 5 tane tamsayı değerin diskte kapladığı alan 7.6 GB oluyor.
Peki bu değerin bu denli büyük olmasının önüne nasıl geçebiliriz?
Tabii ki doğru veri tipini seçerek. Bigint veri tipi -2^63 ile +2^63 arasındaki değerleri adresler.
Şimdi bu durumda "200 milyon satır için bu kadar büyük adres aralığına ihtiyaç var mı?" sorusunu sormak gerek. Bigint’ten farklı olarak bir de integer veri tipimiz var. Integer veri tipi ise -2^32 ile +2^32 arasındaki değerleri adresler. Yani yaklaşık -2 milyar ile +2 milyar arası. Bizim nüfusumuz hiç bir zaman 2 milyar üstü olmayacağı için bu kısmı integer tanımlayabiliriz ve integer değer sadece 4 byte’lık yer kaplar.
CITIZENNUMBER alanı için de aynısı geçerlidir. Burada da integer bizim için yeterlidir.
CITYID alanına gelince, şu anki şehir sayımız sadece 81 ve muhtemelen hiç bir zaman 255’ten büyük olmayacak. Bu durumda bu alan için 0-255 arası değerleri adresleyen tinyint uygun olabilir ve bu veri tipi hafızada sadece 1 byte yer kaplar.
TOWNID kişinin yaşadığı ilçenin ID değeri. Türkiye’de yaklaşık bin civarında ilçe var. Bu durumda bu değeri adreslemek için tinyint yetersiz, integer ise büyük kalır. Arada başka bir veri tipimiz daha var: Smallint. Smallint hafızada 2 byte'lık yer kaplar ve -2^15 ile +2^15 arasındaki değerleri adresler. Bu durumda -32.000 ile +32.000 arasındaki değerleri adresleyebiliriz.
DISTRICTID alanı kişinin yaşadığı mahallenin ID değeri. Türkiye’de yaklaşık 55.000 mahalle/köy bulunmakta. Bu durumda artık bu alan için smallint değeri de yetersiz olup integer kullanmak mantıklıdır.
Şimdi yeni değerlere göre hesabımızı tekrar yapalım.
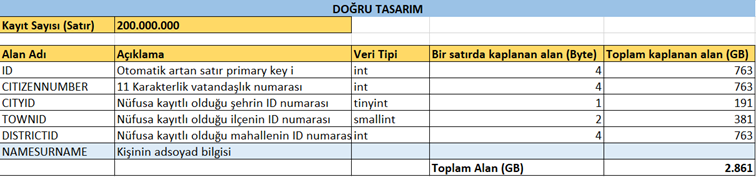
Görüldüğü gibi toplam alan 7.6 GB’tan 2.8 GB’a düştü. Bu kadar farkın gerçek dünyada bize ne kadar fayda sağlayacağına tekrar değineceğiz.
Şimdi string bir ifade olan NAMESURNAME alanına bakalım.
Türkiye’de Türk vatandaşı olanlar sadece Türkler değil ve yabancıları da göz önüne alarak en uzun isimlere göre bir sınır belirlememiz gerekiyor. Bildiğim kadarıyla İspanyollar dünyadaki en uzun isimlere sahip uluslar arasında. Sebebine gelince… Bizde dede ve ninenin isimleri çocuklara konulur ya saygıdan, işte onlar 7 göbek dedelerinin isimlerini koyuyorlar çocuklarına. Bu durumda maksimum isim karakter uzunluğunu bu örneği göz önünde bulundurarak belirleyelim ve 250 karakter olarak koyalım.
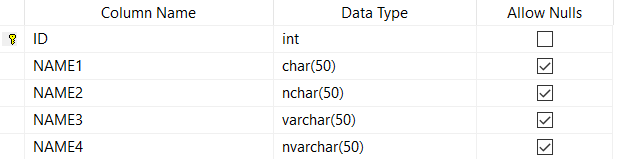
Veri tipi olarak ise char, nchar, varchar ve nvarchar gibi veri tiplerini seçebiliriz. Genel olarak bunların hepsine metin der geçeriz ama gördüğünüz gibi burada daha değişik veri tipleri var.
Bunların aralarında ne fark olduğunu anlamak için bir tablo oluşturup kolay anlaşılması için de uzunluğunu 50 karakter olarak belirliyoruz.
Test olarak kaydettiğimiz tablomuzun içine tüm alanlara “ÖMER” kelimesini ekliyoruz.

Şimdi tabloyu sorgulayalım.
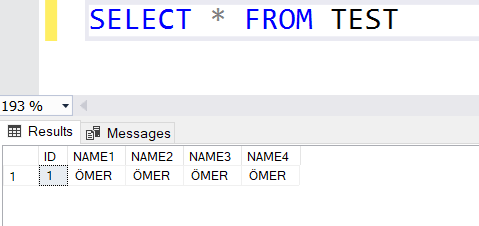
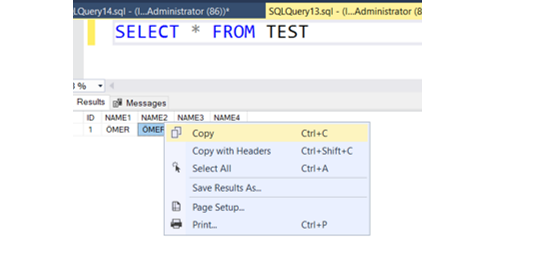
Görünürde tüm alanlar aynı gibi duruyor. Peki gerçekten öyle mi? NAME1 alanını kopyalayıp boşluğa yapıştıralım.
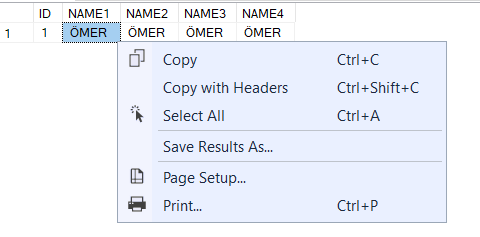
Gördüğünüz gibi imleç ÖMER kelimesinden epey bir uzakta yanıp sönüyor. Çünkü char veri tipinde sistem maksimum uzunluğa erişene kadar eklenen metne boşluk ekler. Yani 4 karakterlik bir veri için 46 karakter daha gereksiz yere hafızada yer tutma işlemi gerçekleşir.
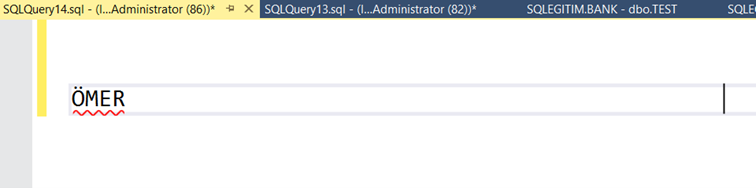
Peki şimdi de nchar veri tipine bakalım.
Yine char türünde olduğu gibi cursor'ü sonuna eklediğini görüyoruz. Bu durumda char ve nchar aynı gibi duruyor.
Şimdi de varchar ve nvarchar'a bakalım.
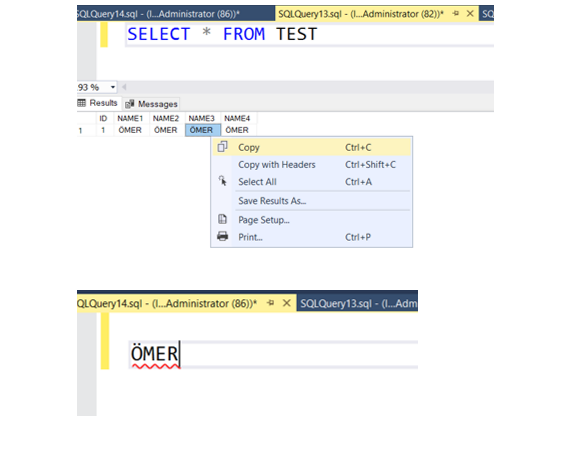
Görüldüğü gibi nvarchar ve varchar’da imleç metnin bittiği yerde duruyor. Buradan çıkaracağımız sonuç char ve nchar birbiri ile aynı iken ve maksimum sınırı dolduracak şekilde boşluk karakteri atarken varchar ve nvarchar'da sadece veri boyutu kadar içeride veri saklanmaktadır.
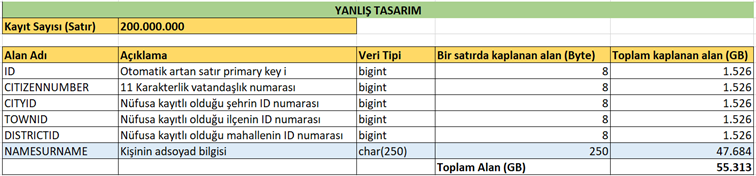
Peki şimdi bir hesap daha yapalım. Buradaki NAMESURNAME alanını char(250) yaparsak hafızada 250 karakter uzunluğundaki bir İspanyol ismi de 2 harfli “Su” ve 3 harfli “Ali”, “Can”, “Cem” gibi isimler de yine 250 karakter yer kaplayacaktır. Bu durumda bu tablonun hafızada kaplayacağı alana bakalım.
Char veri tipinde bir karakter 1 byte'lık yer kaplar. Yani bu durumda her bir satırda isim alanı 250 byte'lık yer kaplar.
Bu hesaba göre sadece isim alanı 47 GB’lık yer kaplar hale geldi.
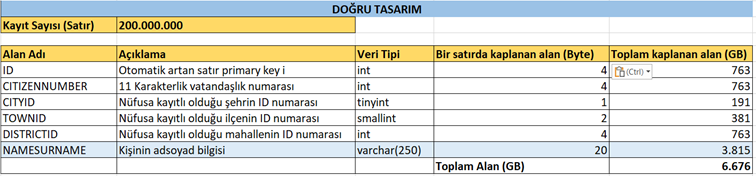
Oysa ortalama bir Türk ad soyad metni 20 karakter gibi bir yer kaplar. Buna göre alan türünü varchar(250) yaparsak herkes isminin uzunluğu kadar yer kaplar.
Bu durumda doğru bir tasarımla sistem sadece 3.8 GB’lık yer kaplar hale geldi.
Bu durumda char ve varchar’ın farkını anlamış olduk. Peki nchar ve nvarchar ile char ve varchar veri tipleri arasındaki fark nedir? Yani baştaki “n” harfi ne anlama geliyor?
Bu konuyu daha iyi anlamak için tabloya Çince bir veri gireceğiz. Google Translate’te aklıma ilk gelen kelime olan kitap kelimesinin Çincesini buldum ve tabloya yapıştırıyorum.
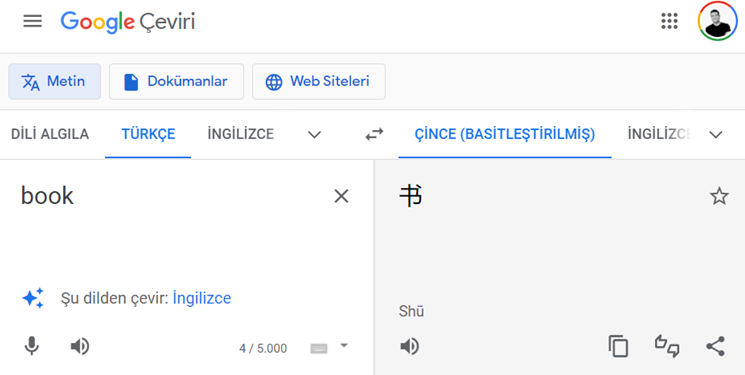

Şimdi de eklediğimiz bu kelimeyi Select sorgusu ile çekelim.
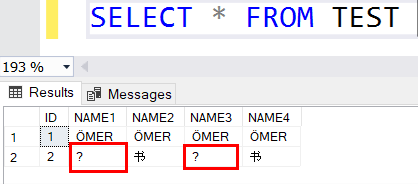
Görüldüğü gibi NAME1 ve NAME3 alanlarında soru işareti gelirken NAME2 ve NAME4 alanlarında Çince verimiz göründü. Buradan çıkaracağımız sonuç ise şu: “N” harfi Unicode anlamına gelir. Yani Çince ve Korecedeki gibi farklı uluslararası karakterleri destekler. Bu durumda bu karakterleri desteklemek için 1 byte’lık değer yetmez. Çünkü 1 byte maksimum 255 karakter tipi demektir. Oysa sırf Japoncada 6 binden fazla harf bulunmaktadır. Bu durumda nchar ve nvarchar veri tipleri her bir karakter için hafızada 2 byte'lık yer kaplar. O zaman sistem bu karakterleri de destekleyecek şekilde nchar ya da nvarchar şeklinde tasarlanmalıdır. Doğru tasarım nvarchar(250), yanlış tasarım ise nchar(250)’dir.
Şimdi yanlış tasarım ile doğru tasarımın farkına bakalım.
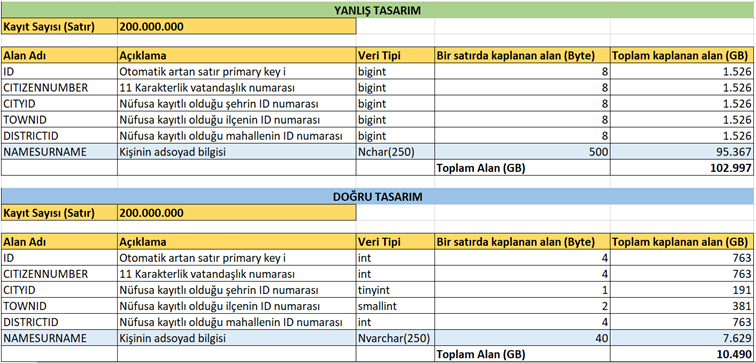
Gördüğünüz gibi yanlış tasarımda kaplanan alan 102 GB iken doğru tasarımda 10 GB’tır.
Şunu unutmamak gerekir ki bu sadece bir tablo ve toplamda çoğunluğu sayısal alanlar olan sadece 6 alandan bahsediyoruz. Bir veritabanında satır sayısı belki bu kadar olmasa da buna benzer yüzlerde tablo bulunabilir.
Bu yazıda veritabanında doğru normalizasyonun ne kadar önemli olduğundan bahsettik ve hiç bir şey yapmadan 10 katlık bir kazanç ya da kaybın nasıl oluşacağını öğrendik. Buradaki olay sadece yer meselesi de değil üstelik. Zira bu veriler memory’de işlenirken CPU da veri ne kadar büyük ise o derece daha fazla yorulur.
Sonuç olarak normalizasyon ve veri tiplerini bilmek tahmin edildiğinde daha önemlidir. :)
