Büyük Verinin Vazgeçilmezleri: Hadoop & Spark
Geleneksel yöntemlerle işlenemeyen veriler için kullandığımız büyük veri kavramı hem yazılımsal anlamda hem de kütüphaneler, fonksiyonlar ve benzeri araçlar anlamında çok çeşitli yapılar içermesine karşın bu kavram dile getirildiğinde akla ilk gelen sistemler elbette Apache Hadoop ve Apache Spark oluyor. Bu yazıda büyük veri ekosisteminin bu vazgeçilmezlerini inceleyecek ve ekosisteminin diğer oyuncularına da bir göz atacağız.
Apache Hadoop
Apache Hadoop açık kaynak kodlu, güvenilir, ölçeklenebilir paralel hesaplama yazılımı projesidir. Büyük veri kapsamında akla ilk gelen yapılardandır. Büyük verinin tüm bileşenleri Apache Hadoop üzerine kurulmuştur. Dolayısıyla büyük veri dünyasının temelini oluşturmaktadır. Apache Hadoop, geleneksel yöntemler ile etkin olarak işlenmesi mümkün olmayan verilerin işlenebilmesine olanak tanır. Bir bilgisayar kümesinin belirli bir işi yapmak için tek bir bilgisayar gibi birlikte hareket etmesini sağlamaktadır. Apache Hadoop’un avantalarını kısaca sıralamak gerekirse:
- Veri saklama ve işleme gücü
- Açık kaynak olması
- Hızlı olması
- Esneklik sağlaması
- Ölçeklenebilirlik sağlaması
- Hata toleransına sahip olması
Başka bir deyişle sistem çalışırken, bir makinenin bozulması tolere edilebilirdir ve aynı zamanda cluster (küme) sayısı yani bilgisayar sayısı istenildiği takdirde artırılabilir.
Apache Hadoop bazı temel bileşenlere sahiptir.
- Hadoop Common: Büyük veri teknolojileri, diğer bir ifadesi ile tüm Hadoop modüllerini destekleyen ortak gereksinimlerdir.
- Hadoop Dağıtık Dosya Sistemi (HDFS): Yerel dosya sistemleri olan FAT32 ve NTFS gibi Hadoop sistemi özelinde çalışan bir dosya sistemidir. HDFS dosya sisteminin FAT32 ve NTFS’den farkı büyük boyutlardaki veriyi dağıtık şekilde depolamaya ve kontrol etmeye imkan sağlamasıdır.
- Hadoop Yarn: Kaynak yönetimi ve iş planlaması için kullanılan Apache Hadoop’un daha etkin bir şekilde kullanılmasına olanak sağlayan bir bileşendir.
- Hadoop MapReduce: Büyük veri dünyasının fonksiyonel anlamda temelini oluşturan bileşendir. Aynı ağdaki dağıtık bilgisayar kümeleri üzerinde büyük veri analizi yapılabilmesi için geliştirilmiş bir programlama modelidir.
Apache Hadoop küme yapısı
Birden fazla bilgisayarın bir küme halinde bir arada çalışmasıdır.
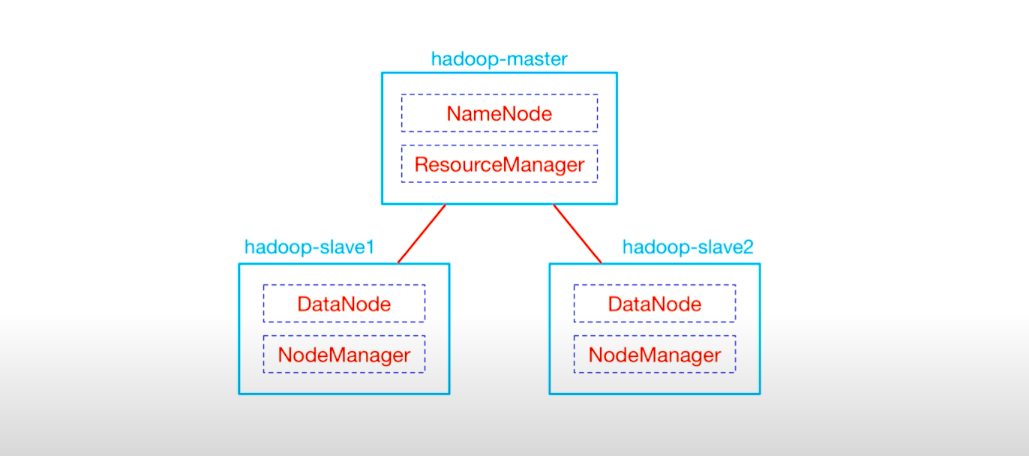
Bu yapıda bir yönetici bir master node ve slave nodelar bulunur. Bir iş yapılması gerektiğinde master node işi planlar ve diğer slave nodelara dağıtır. Bu aşamanın ardından işlemler gerçekleştirilir ve sonuçlar toplanıp bir araya getirilerek iş tamamlanır.
MapReduce
MapReduce çalışma sistemini aşağıdaki tabloda verilen örnek üzerinden inceleyelim.
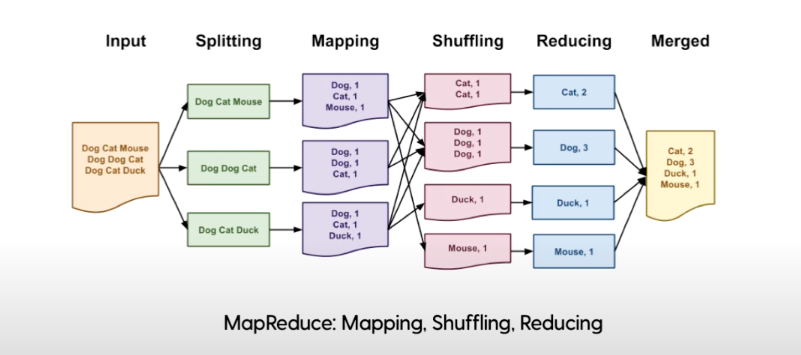
Input kısmında bazı hayvan isimleri birden fazla kez yazılmış şekilde bir girdi mevcuttur. Amaç girdi içerisinde hangi hayvandan kaç tane olduğunu elde etmektir. Splitting aşamasında satırlara bölünme işlemi gerçekleştirilir.
Ardından mapping aşamasında her bir bölümde yer alan hayvanlar kendi içinde sayılır. Bu aşamada görev HDFS üzerindeki girdi verilerini işlemektir. Girdi verisi satır satır map fonksiyonundan geçirilir. Map fonksiyonu veriyi işler ve yeni veri parçacıkları oluşturur.
Mapping basamağından sonra gelen shuffle ve reduce aşamalarının görevi, map aşamasından gelen veriyi işlemek ve indirgemektir. Bu basamaklar genel olarak reduce olarak da anılır.
Map ve reduce süreçleri boyunca yapılanlar küme üzerindeki tüm bilgisayarlara gönderilir. Tüm görevlerin başarılı sonuçlanması durumu, verilerin taşınması durumu ve benzeri işlemler kontrol edilir.
Merged basamağında ise parçalara bölünerek, aşama aşama halledilen işlemlerin sonuçları bir araya getirilir.
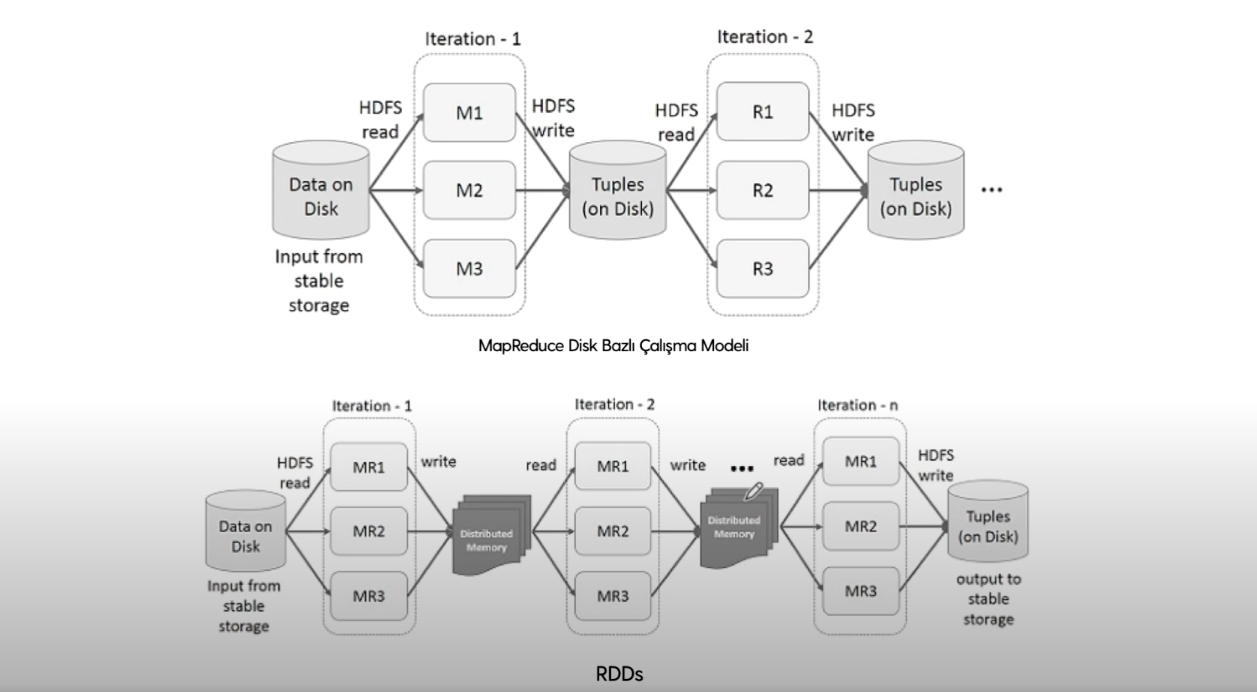
Apache Hadoop, disk tabanlı çalışan bir modeldir. Yani her MapReduce görevinde diskten okuma ve diske yazma işlemi yapılır.
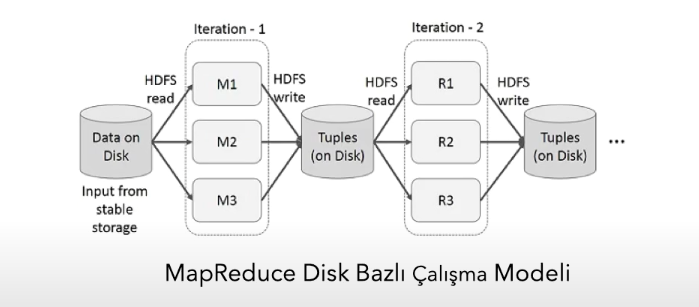
Bu sebeple makine öğrenmesi gibi iteratif işlemlere ihtiyaç duyulduğunda bu işlemler sürekli diske gidip gelme ve diske okuma yazma yapılmasından kaynaklı olarak çok zaman alır ve kaynakları meşgul eder. Bu sebeple disk bazlı çalışma modeli yerine RAM bazlı (yani in memory -geçici bellek) çalışma yaklaşımıyla Hadoop’a alternatif olarak değil ama MapReduce disk bazlı çalışma modeline alternatif olarak geliştirilen Apache Spark olarak bilinen RDD çalışma prensibi yaygın olarak kullanılmaktadır.
Apache Spark
Apache Spark küme üzerinde hızlı ve genel amaçlı bilgi işleme sistemidir. MapReduce’a alternatif olarak gelmiştir. MapReduce modelinde yer alan disk bazlı çalışma sisteminin yarattığı maliyetlerden dolayı ortaya çıkmıştır. Bu kapsamda Apache Spark'ın çeşitli avantajları bulunmaktadır:
- Apache Hadoop’a göre 100 kat daha hızlı çalışmaktadır.
- Java, Scala, Python ve R ile uygulama geliştirilebilir.
- Spark SQL, Spark MLlib, Spark Streaming, GraphX gibi ortamlar aynı uygulamada kullanılabilir. Başka bir deyişle genelleştiricidir.
Apache Spark’ın bileşenleri ise şunlardır:
- Spark Core: Hafıza yönetimi, görevlerin dağıtılması, hata kurtarma, saklama ve dosya sistemlerine erişim Spark Core içerisinde yer almaktadır
- RDD: MapReduce’un alternatifidir. RDD, Apache Spark’ın programlama modelidir. Verinin bellek içi tutularak paralel işlenmesini ifade etmektedir.
- Spark SQL: SQL ya da bir dataframe API kullanarak Spark programlarında yapılandırılmış veriyi sorgulama imkanı sağlar.
- Spark MLlib: Apache Spark’ın ölçeklenebilir makine öğrenmesi kütüphanesidir. Apache Spark’ın bellek içi çalışma şeklinden ötürü iteratif işlemler barındıran makine öğrenmesi gibi işlemlerde verimli zaman ve kaynak kullanımı açısından çözüm sunmaktadır.
- Spark Streaming: Akan verinin ölçeklenebilir, yüksek hacimli ve hata toleranslı bir şekilde işlenmesine olanak sağlayan temel Spark API’sine ait bir Spark uzantısıdır.
- GraphX: Paralel grafik tabanlı hesaplama işlemleri için kullanılan bir kütüphanedir.
RDD
RDD, dayanıklı dağıtık veri setleri anlamına gelir. RDD’de yapılan işlemler veriyi RAM’e taşımak, RAM üzerinde dönüşüm işlemlerini ve gerekli iteratif işlemleri gerçekleştirmek ve işlemlerin bitiminden sonra veriyi tekrar diske yazmaktır. Bu durum bellek içi (in memory) veri işleme olarak da adlandırılır.
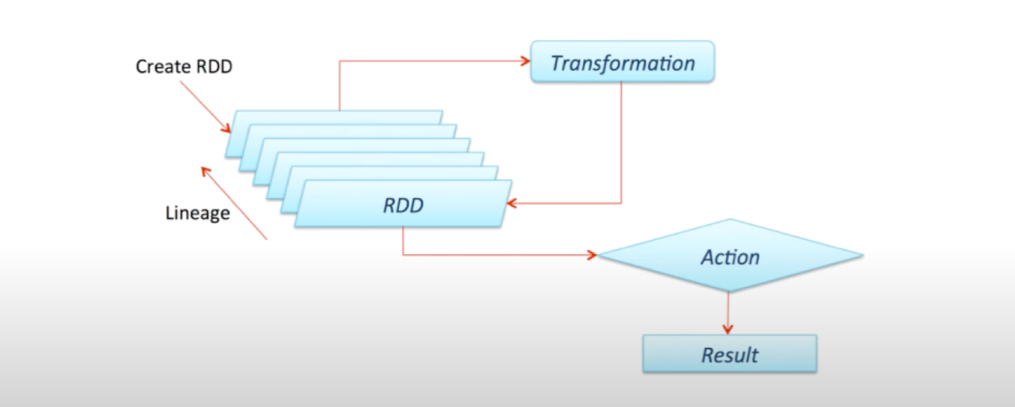
RDD üç aşamadan oluşmaktadır:
- RDD’leri oluşturma: Dayanıklı dağıtık veri setlerini oluşturma aşamasıdır.
- Dönüştürme: Üretilen bir işlem olduğunda, bu işlem önce askıda bekletilir. Başka bir deyişle RAM’de tutulur. Bu işlem tutulurken mevcut RDD’ler üzerinden dönüştürme işlemleri gerçekleştirilir.
- Aksiyon: Dönüştürme işlemlerinin ardından mevcut RDD’ler toplanarak işlenir ve sonuçlar aksiyon basamağı ile beraber harekete geçirilir.
Aksiyon basamağı tetiklenmeden uygulama işlemi (execution) gerçekleşmemektedir. Bu yapısıyla tembel çalışma, literatürdeki ismiyle lazy evaluation olarak adlandırılır. Lazy olarak adlandırılmasına rağmen bu yöntem hız ve performans artırılması açısından verimli bir imkan sağlanmaktadır.
Hadoop MapReduce ve Apache Spark’ın Farkı
Günlük hayattan bir örnek ile Hadoop MapReduce ve Apache Spark’ın farkını pekiştirelim:
- Yemek sofrasına oturmuş bir ailenin ebeveynlerinden biri, çocuklarından birine mutfaktan bir çatal getirmesini söyler. Çocuk mutfağa gider. Çatalı alır, masaya geri gelir ve oturur. Derken çocuktan kaşık istenir. Çocuk yine söyleneni gerçekleştirir ve masaya oturur. Ardından çocuktan tuzluk istenir ve çocuk tekrar mutfağa gider ve tuzluğu alır. Geri gelip masaya oturur. Bu durum Apache Hadoop’un çalışma prensibine örnektir.
- Başka bir yemek sofrasında, çocuktan bir çatal istendiğinde, çocuk mutfağa gider ve orada bekler. Çocuktan kaşık istenir. Çocuk kaşığı alır ve mutfakta beklemeye devam eder. Çocuktan tuzluk da istenir. Çocuk tuzluğu da alır ve bekler. Son olarak ebeveynlerinden artık ondan bir şey istenmeyeceğine dair bir aksiyon komutu geldiğinde askıda bekletilen bu iteratif işlemleri sonlandırıp, çocuk sofraya elindekilerle birlikte oturur. Bu durum da Apache Spark’ın çalışma prensibine örnektir.
Apache Spark sistemi, veriyi RAM’e dağıtık bir şekilde taşır. Kümedeki bilgisayarların RAM’inde işlenmek üzere bazı görevler dağıtılır. Bu görevler gerçekleştirilir, dönüştürme işlemleri hayata konur ve aksiyon fonksiyonları tektiklendiğinde işlemler diske yazılarak kalıcı hale getirilir.
Büyük veri ekosisteminin diğer üyeleri
Büyük veri, hem yazılımsal anlamda hem de kütüphaneler, fonksiyonlar ve benzeri araçlar anlamında çok çeşitli yapıları içerisinde barından zengin bir ekosistemdir.
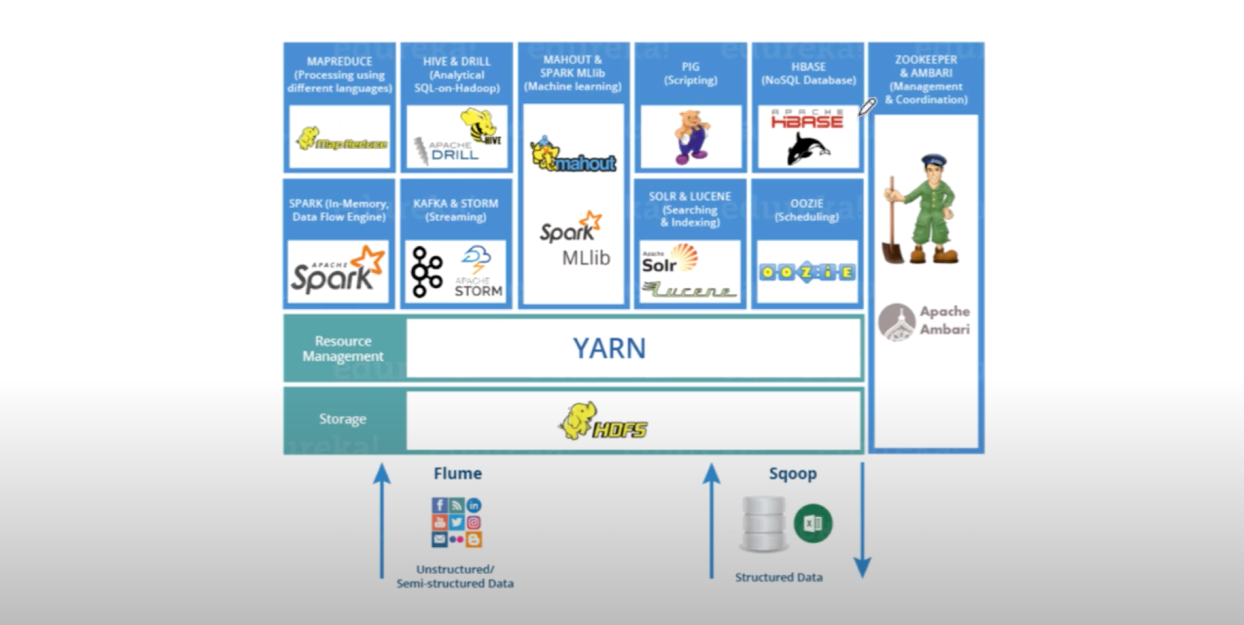
Bu ekosistemin sık kullanılan bazı araçlarını inceleyelim:
Zookeeper & Apache Ambari:
- Apache Hadoop kümelerinin kurulumu, yönetimi ve gözetimi için geliştirilmiş web tabanlı araçlardır. Kümelerin durumunun ve performanslarının takip edilebileceği bir gösterge panelini içerir. Kümeye hakim olma amacıyla kullanılan araçlardır.
Hive & Apache Drill:
- Arka planda SQL komutlarını MapReduce’a çevirerek, büyük veri üzerinde SQL sorguları kullanılabilmesini sağlayan araçlardır.
Kafka & Apache Storm:
- Akan verilerde sıkça kullanılan, büyük veri akışının gerçek zamanlı bir şekilde düşük gecikmeyle gerçekleşmesini sağlayan ve gerçek zamanlı veri işleme imkanı tanıyan araçlardır.
Mahoot & Spark MLlib:
- Makine öğrenmesi görevleri için geliştirilen kütüphanelerdir.
Pig:
- SQL türevi, daha scripting kısımları ile ilgilenecek yönüyle bazı görevleri yerine getirmek için kullanılan araçlardandır.
Lucene & Apache Solr:
- Arama ve indeksleme işlemleri için kullanılan araçlardır.
Apache Hbase:
- NoSQL veritabanı yönetim sistemidir. Büyük boyutlu verilerle gerçek zamanlı okuma yazma erişimi yapmak amacıyla gerektiğinde kullanılan açık kaynak kodlu sütun bazlı bir veri tabanıdır.
Oozie:
- İşlerin, akışların ve zamanlamaların planlanması için kullanılan araçtır.
Sqoop:
- Yapısal veri tabanlarından (SQL veya Excel veri ortamlarından) tabular olarak betimlenen excel formuna benzer verilerden Hadoop ortamına veri aktarmak için kullanılır.
Flume:
- Yapısal olmayan türdeki verilerin HDFS ortamına aktarımı için kullanılan araçtır.
PySpark:
- Büyük veri kapsamında Spark ile çalışabilmeyi sağlayan bir kütüphanedir. Büyük veri ekosisteminin, özellikle Spark tarafına bakan yönleriyle, SQL işlemleri, makine öğrenmesi uygulamaları, veri ön işleme işlemleri, modelleme gibi çok çeşitli ihtiyaçlar kapsamında çözüm sunar.
Büyük veri analitiği hakkında detaylı bilgi edinmek isterseniz Miuul'un Büyük Verinin Temelleri üzerine oluşturduğu eşsiz eğitimlere mutlaka göz atmalısınız. Veri bilimini veya veri mühendisliğini kariyer rotanıza koyduysanız Miuul’un Data Scientist Path veya Data Engineer Path eğitim programları tam olarak aradıklarınızı sizlere sunacaktır.
Kaynaklar
