Elasticsearch Nedir? Neden Kullanılmalıdır?
Bizlerin internette geçirdiği süreyi düşünelim. Ne kadar da çok vakit geçiriyoruz değil mi? Geçirdiğimiz vakit arttıkça, web sitelerinde biriken veri miktarı da doğru orantılı artıyor. Web sitelerinde devasa miktarda veri üretiliyor ve bunlara big data (büyük veri) deniliyor. Üretilen bu verilerin büyük bir kısmı dağınık halde bulunuyor ve tek başlarına anlamsız ve yapılandırılmamış haldeler. İşletmeler için bu verilerin anlamlı hale gelmesi önemlidir. Verinin doğru ve hızlı bir şekilde erişilebilir ve analiz edilebilir olması, müşteri sadakati sağlama, pazarlama stratejisi geliştirme gibi birçok açıdan hayati öneme sahiptir. Metin arama araçlarının çoğu, bu tür büyük, dağınık ve tek başına anlamsız veri topluluklarında işe yaramıyor. Elasticsearch, tüm bu sorunlarla baş etmek için geliştirilmiş bir (metin) arama aracıdır. Elasticsearch java dilinde yazılmış, dağıtık mimariye sahip açık kaynak kodlu bir projedir. Belli dökümanların indexlenmesi ve aranabilmesini kolaylaştıran bir yapıda olan Elasticsearch’te, üzerinde tutulan her doküman bir JSON nesnesidir. Shay Banon, Elasticsearch'ün ilk versiyonunu 2010 yılı Şubat ayında piyasaya sürmüştür.
Elasticsearch, doğru kullanıldığında birçok big data aracından daha hızlıdır. Veri depolama işlemleri yapan ve bu verileri sorgulama işlemleri yapmamızı sağlayan bir yapıdadır.
Elasticsearch ne için kullanılır?
Elasticsearch'ün hızı, ölçeklenebilirliği ve birçok içerik türünü dizine ekleme yeteneği, aşağıdaki birçok kullanım seçeneğini sağlamaktadır:
- Uygulama arama
- Web sitesi arama
- Kurumsal arama
- Günlüğe kaydetme ve günlük analizi
- Altyapı ölçümleri ve kapsayıcı izleme
- Uygulama performansı izleme
- Coğrafi veri analizi ve görselleştirme
- Güvenlik analitiği
- İş analitiği
Neden Elasticsearch?
Hız: Temel olarak milyonlarca satırdan oluşan verileri, Elasticsearch’e JSON formatında atarsak, milisaniyeler içerisinde verilere ulaşabiliriz.
Ölçeklenebilirlik: Elasticsearch laptop veya istenilen sunucularda çalıştırılabilir. Clusterın kurulumu Elasticsearch tarafından otomatik olarak yapılmaktadır.
Kolay kullanım: Sağladığı RestAPI’ler sayesinde kolay kullanılabilen ve zengin kütüphaneleri ile geniş programlama dillerini destekleyen bir yapıdır.
Özellikleri:
- Apache Lucene alt yapılıdır.
- Java tabanlıdır.
- Açık kaynaktır.
- Dağıtık ve ölçeklenebilir yapıda çalışabilir.
- Veri tipine uygun biçimde otomatik mapping yapabilme özelliğine sahiptir.
- Cluster yapısına sahiptir.
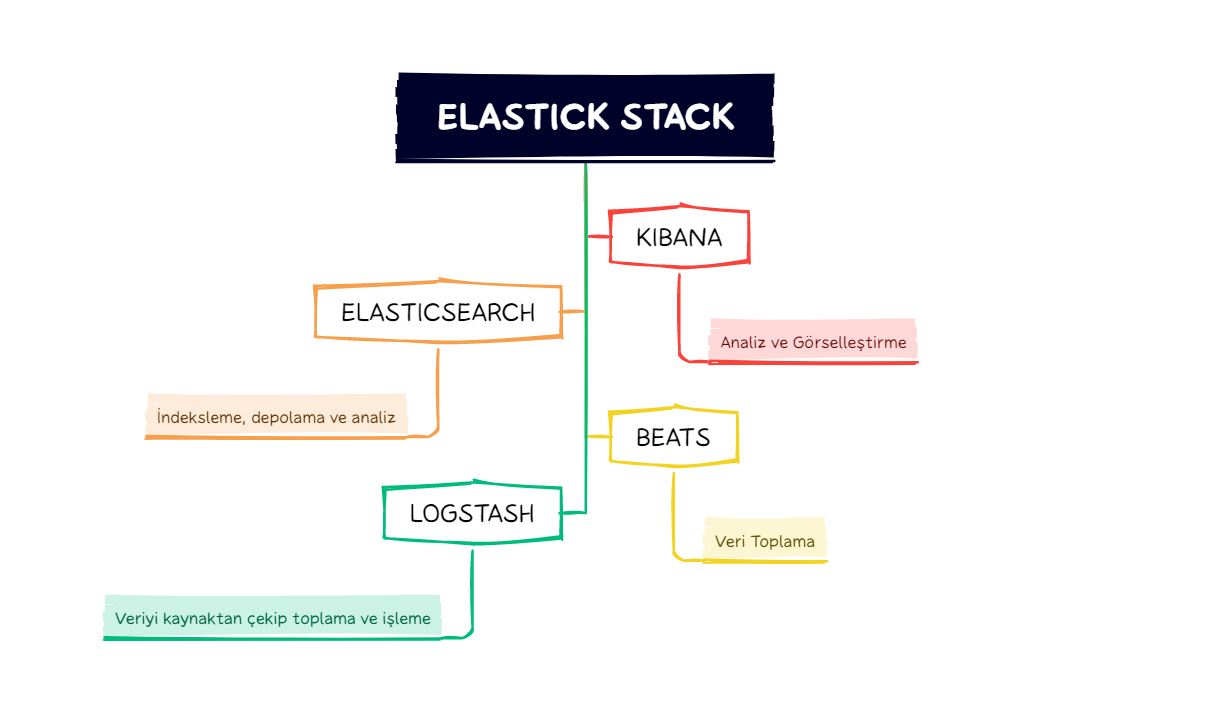
- Kibana ve Logstash araçları ile beraber kullanılabilir.
- Hızlı kurulum ve kolay konfigürasyon özelliğine sahiptir.
- Veri aktarma kolaylığına sahiptir.
- NoSQL veri tabanlarından aktarım yapmayı mümkün kılar.
Elasticsearch Bileşenleri
Type: İlişkisel veritabanlarındaki tablolar olarak adlandırılabilir. Aynı index içerisinde birden fazla type barındırabilir.
Document: İlişkisel veri tabanlarındaki rows, documents olarak temsil edilirler. Typeler birden fazla documenta sahiptir.
Field: Diğer veritabanlarındaki columnlar, Elasticsearch’te field (alan/kolon) olarak adlandırılır. Documentlar birden fazla fielda sahiptir.
Mapping: Verileri indexlerken hangi tipte oldukları bilgisini göstermemiz gereken işlemdir.
Cluster: Verileri bir arada tutan, indexleme arama gibi yeteneklerin yürütüldüğü küme veya node koleksiyonudur.
Full-text search: Anahtar bir kelimenin aratılmasıyla, anahtar kelime ile eşleşen dokümanların bulduğu sonuca hızlı bir şekilde erişim sağlamasına verilen isimdir.
Index: Elasticsearch'te aranabilen en büyük kavramdır. İlişkisel veritabanındaki tabloya benzerdir. Her indexin bir şeması var. Bu şemada documentin hangi veri türüne sahip olduğunu tanımlanıyor. Elasticsearch’in kendisini bir database olarak düşünebiliriz.
Shard: Elasticsearch bir cluster yapısına sahip olduğu için büyük veri kümelerini kaydetmek istediğinde ve yüksek trafik anında sisteme yeni makineler ekler ve yapımızı ölçeklendirme işlemi yapılabilir. Shard performansı artırır ve node üzerinde işlemlerin dağıtılmasını ve paralelleştirilmesini sağlar.
Node: Servera verilen isimdir. Verilerin depolandığı makinelerin her birisine verilen isimdir. Clusterlar arama ve indexleme gibi yetenekleri nodelar (düğümler) sayesinde gerçekleşir.
Replica: Verilerin her birinin kopyasının bulunduğu başka makinelerdir. Makinelerden birinde sorun çıktığı veya çöktüğü zaman bunlar devreye girer.
Elsaticsearch ile ilgili daha detaylı bilgiye erişmek ve sektörden gerçek veriler ile çeşitli projeler üzerine çalışmak için Miuul Data Engineer Path kariyer yolculuğu programını inceleyebilirsiniz.
Kaynaklar
- Miuul, Data Engineer Path
- Gtech, Elastic Search Esnek Arama
- Wikipedia, Elasticsearch
- Kommunity, Elasticseach ve Kibana
- Elastic, Elasticsearch
