Filtreleme yöntemleri ile makine öğrenmesinde değişken seçimi
Değişken seçimi (feature selection), makine öğrenmesi modelleri oluşturmak için veri kümesinde bulunan tüm değişkenlerden bir alt küme oluşturma işlemidir. Kısaca değişken seçimi:
- Basit modeller oluşturmak ve yorumlamayı kolaylaştırmak için uygulanır. 100 değişkenli bir modelin sonucunu anlamak 10 değişkenli bir modelin sonucunu anlamaktan daha zordur.
- Eğitim süresini kısaltmak için uygulanır. Modelleri oluşturmak için kullanılan değişkenlerin sayısını azaltmak, hesaplama maliyetini düşürür. Model kararlarının saniyeden kısa sürede alınması gereken canlı bir ortamda modelin skorlama hızı önemlidir.
- Aşırı öğrenmeyi (overfitting) azaltarak genellenebilirliği arttırmak için uygulanır. Çoğu zaman değişkenlerin çoğu tahmin değeri çok az olan gürültülerdir. Gürültülü değişkenleri ortadan kaldırarak, bir makine öğrenimi modelinin genellemesini büyük ölçüde geliştirebiliriz.
- Yazılım geliştiriciler tarafından modelin uygulanmasını daha kolay hale getirmek için uygulanır. Yazılım geliştiricilerin, modeli beslenmesi gereken değişkenleri çağırmak için kod yazmaları gerekir. 10 ila 50 değişken için kod yazmak 400 değişken için kod yazmaktan çok daha kısa sürer.
- Gereğinden fazla değişkenlerden kurtulmak için uygulanır. Bir veri kümesindeki değişkenler birbiriyle yüksek korelasyona sahip olabilirler. Yüksek korelasyona sahip değişkenler aynı bilgiyi sağladıkları için böylesi değişkenlerden birini tutabilir ve geri kalanlarını bilgi kaybetmeden kaldırabiliriz.
- Yüksek boyutlu veri setlerinde kötü öğrenmeyi engellemek için uygulanır. Yüksek boyut, ağaç tabanlı yöntemler gibi bazı makine öğrenimi modellerinde düşük performansa neden olur. Değişken sayısını azaltmak daha sağlam ve tahmini başarısı yüksek modeller oluşturur.
Değişken seçme yöntemleri, belirli bir veri kümesinden elde edilebilecek değişken kombinasyonlarının tüm olası alt kümelerini arayacak ve en iyi makine öğrenimi modeli performansını üreten değişken kombinasyonunu bulacaktır. Ama bu hesaplama maliyeti nedeniyle iyi bir seçenek değildir. Farklı değişken alt kümeleri, farklı makine öğrenimi algoritmaları için optimum performans sağlayabilir. Bu yalnızca bir değişken alt kümesi olmadığı, kullanmayı planladığımız makine öğrenimi algoritmasına bağlı olarak potansiyel birçok optimum değişken alt kümesi olduğu anlamına gelir. Bundan dolayı çok sayıda değişken seçme yöntemi geliştirilmiştir.
Değişken seçme yöntemleri üç ana başlığa ayrılır:
- Filtreleme Yöntemleri (Filter methods)
- Sarmal Yöntemler (Wrapper methods)
- Gömülü Yöntemler (Embedded methods)
Bu yazıda ise filtreleme yöntemlerine eğileceğiz.
Filtreleme yöntemleri herhangi bir makine öğrenmesi algoritmasından bağımsız değişken seçimi yapar (model agnostic) ve yalnızca değişkenlerin özelliklerine bağlıdır. Veri setinde çok düşük bilgi sağlayan veya hiç sağlamayan değişkenlerin veri setinden hızlı bir şekilde çıkarılması için çok uygundur.
Tek değişkenli (univariate) ve çok değişkenli (multivariate) olmak üzere iki türlü filtreleme yöntemi vardır.
Tek değişkenli filtreleme yöntemleri, her bir değişkeni belirli kriterlere göre değerlendirir ve sıralar. İki adımdan oluşur:
- Değişkenleri belirli bir kritere göre sıralamak. Filtreleme yöntemleri tipik olarak tek değişkenlidir. Her bir değişken ayrı ayrı ve bağımsız olarak sıralanır.
- En yüksek sıralamaya sahip değişkenlerin seçilmesi. Değişkenler diğer değişkenlerden bağımsız olarak sıralandığından, değişkenler arasındaki etkileşim filtre yöntemlerinde dikkate alınmaz. Bu nedenle gereksiz değişkenleri seçme eğilimindedirler.
Tek değişkenli filtreleme yöntemlerinde sıralama için uygulanabilecek çeşitli istatistiksel testler bulunmaktadır:
- Chi-square
- ANOVA
- Mutual Information Varaince
Çok değişkenli filtreleme yöntemleri ise değişkenleri diğer değişkenlerle ilişkisel olarak inceler. Bu filtreleme yöntemleri ile gereksiz (redundant) değişkenler, yinelenen (duplicated) değişkenler ve ilişkili (correlated) değişkenler ile başa çıkılabilir.
Temel filtreleme yöntemleri
- Sabit değişkenler (constant features): Veri kümesinin tüm satırlarında aynı değere sahip olan değişkenlerdir. Modele hiçbir bilgi sağlamazlar. Varyansı sıfır olan tüm değişkenler kaldırılır.
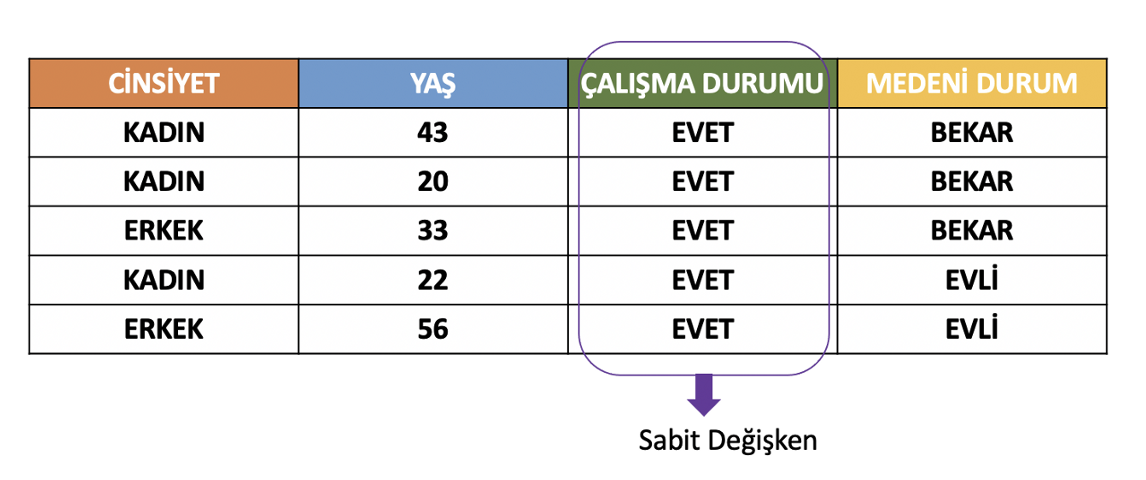 Sabit değişkenlerin bulunması ve veri setinden çıkarılması için uygulanabilecek Python kodu:
Sabit değişkenlerin bulunması ve veri setinden çıkarılması için uygulanabilecek Python kodu: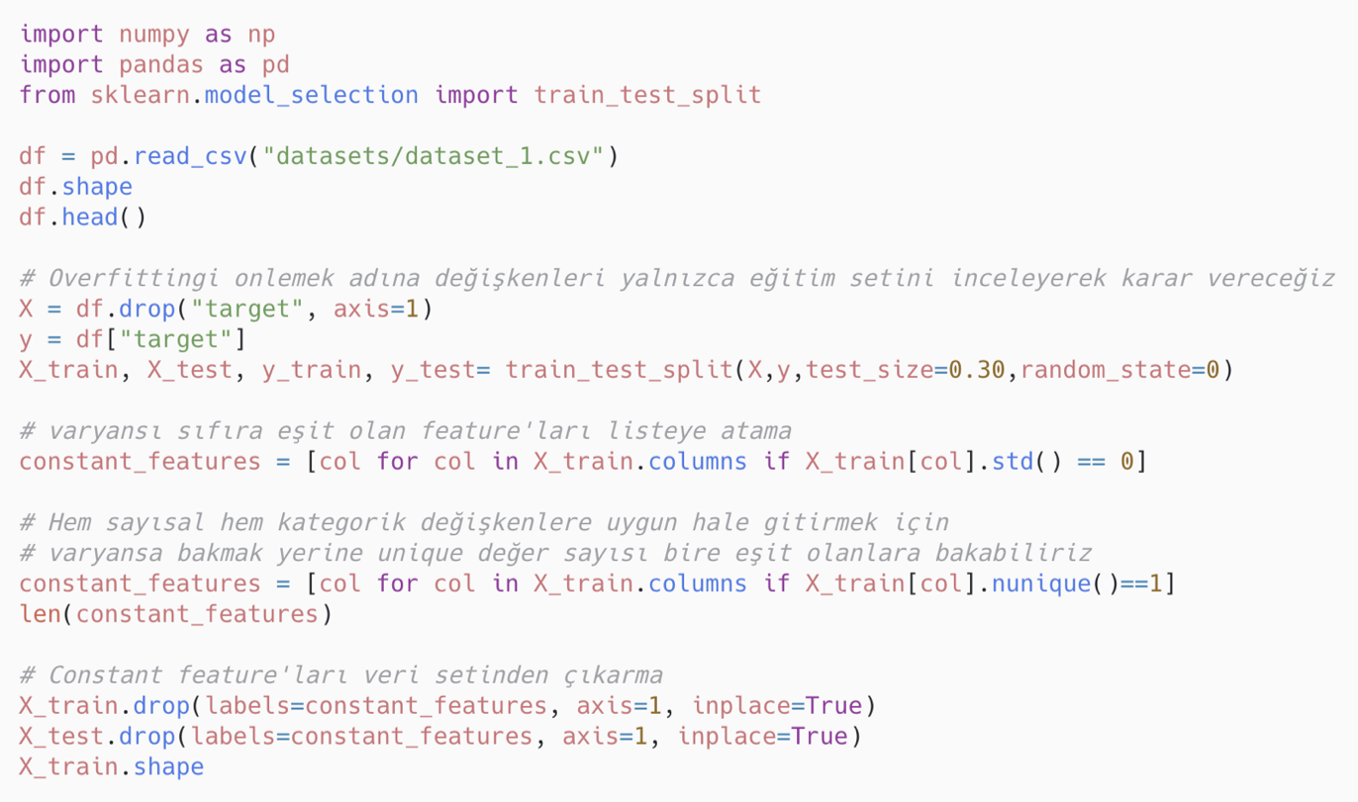
- Yarı sabit değişkenler (quasi-constant features): Veri setinin gözlemlerinin büyük çoğunluğu için aynı değeri gösteren değişkenlerdir. Genellikle model için çok az bilgi sağlar ama istisnalar vardır. Bu gibi değişkenleri kaldırırken dikkatli olmak gerekir.
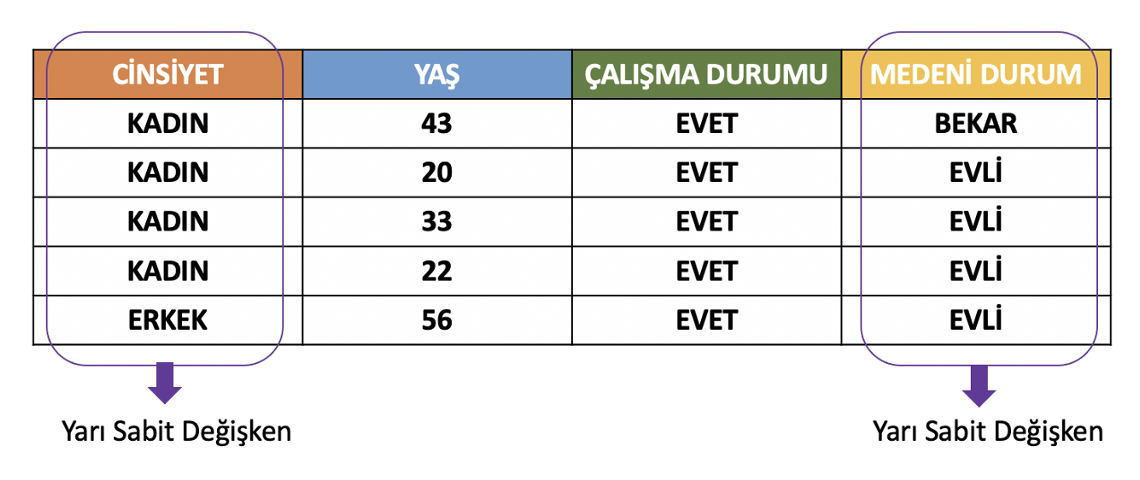
Yarı sabit değişkenleri bulunması ve veri setinden çıkarılması için uygulanabilecek Python kodu:
- Yinelenen değişkenler (duplicated features): Farklı adlara sahip olup birebir aynı gözlem değerlerini içeren değişkenlerdir. Bunların veri setinden çıkarılması daha yorumlanabilir makine öğrenimi modelleri için önemlidir.
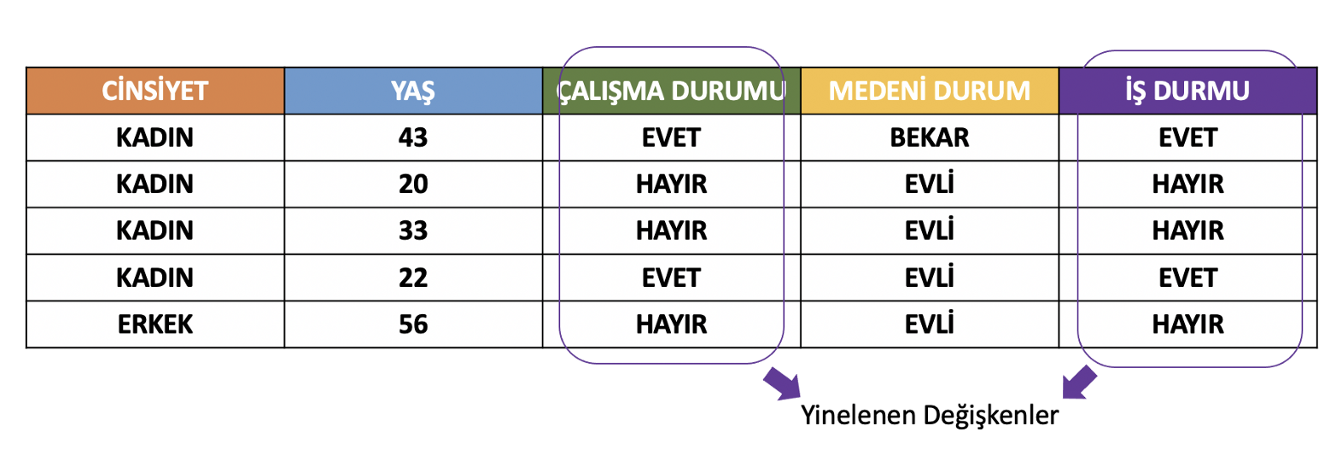
Yinelenen değişkenlerin bulunması ve veri setinden çıkartılması için uygulanabilecek Python kodu: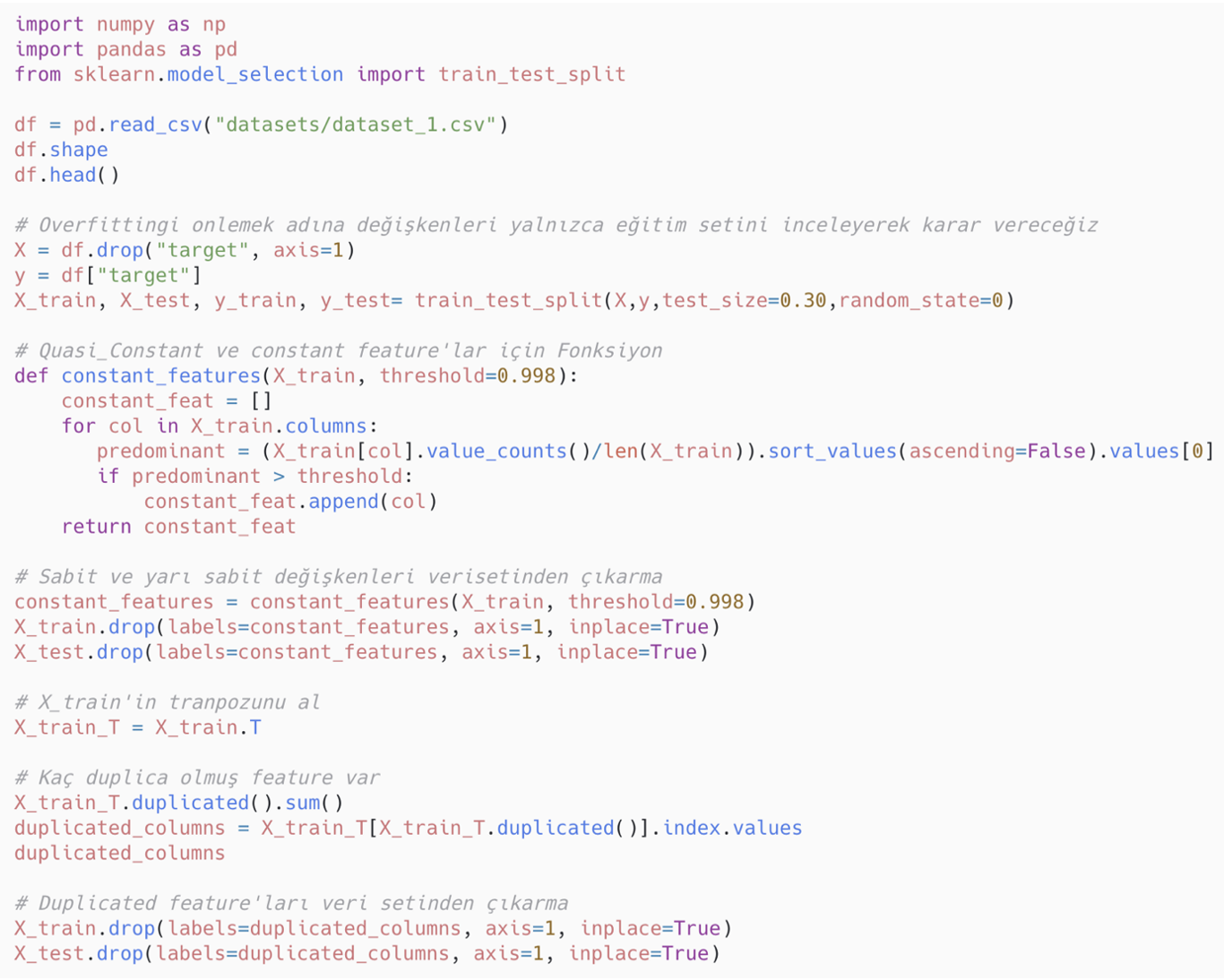
- Korelasyon filtreleme yöntemleri: Korelasyon, iki veya daha fazla değişken arasındaki doğrusal ilişkinin bir ölçüsüdür. İki değişken arasındaki yüksek korelasyon birini diğeri üzerinden tahmin edebileceğimiz anlamına gelmektedir. Bu nedenle özellikle doğrusal makine öğrenmesi modellerinde bağımlı değişkenle yüksek korelasyonlu değişkenler aranır. Bağımlı değişken haricinde diğer değişkenler arasındaki yüksek korelasyon model için fazla bilgi sağlamaz bu nedenle yalnızca birini seçmek yeterli olacaktır. İyi makine öğrenmesi modelleri için, genel olarak bağımlı değişkenle yüksek düzeyde ilişkili ancak kendi aralarında ilişkisiz değişkenler aranır.
En bilinen ve yaygın olarak kullanılan korelasyon ölçüsü, Pearson korelasyon katsayısıdır. Pearson korelasyon katsayısı -1 ile 1 arasında değerler alabilir. Pozitif değerler, bir değişkenin değeri ne kadar yüksekse, diğer değişkenin değerinin o kadar yüksek olduğunu gösterir. Negatif korelasyon değerleri ise bir değişkenin değeri ne kadar yüksekse, diğer değişkenin değerinin o kadar düşük olduğunu gösterir. Bizim ilgilendiğimiz şey, Pearson korelasyon katsayısının mutlak değeridir.
Korelasyonu yüksek olan değişkenleri kaldırmanın iki yöntemi vardır:
Yöntem 1 (Brute Force): Değişkenlerin eğitim setindeki sıralamalarına göre tek tek korelasyonları inceler. İlk değişken seçilir ve sırayla ikinci, üçüncü ve sırasıyla diğer değişkenlerle kıyaslanır. İlk değişkenle yüksek korelasyon gösteren değişkenler veri setinden kaldırılır. Daha sonra ikinci değişkene geçilir ve üçüncü, dördüncü ve diğer değişkenlerle aralarındaki korelasyona bakılıp aynı işlem uygulanır. Veri kümesinin son değişkenine kadar bu devam eder. Hızlıdır ama daha fazla bilgi içerebilen değişkenleri veri setinden çıkarma riski vardır. Örneğin, birinci değişkenle ikinci ve üçüncü değişken arasında yüksek korelasyon görüldüğünü ve veri setinden kaldırıldığını varsayalım. İkinci değişkenin bağımlı değişkeni birinci değişkenden daha iyi tahmin etme durumu olabilir.
Brute force yöntemi ile yüksek korelasyonlu değişkenlerin bulunması ve veri setinden çıkarılması için kullanılabilecek Python kodu:
Yöntem 2: Aralarında yüksek korelasyon görünen değişkenler kümelenir ve her kümeden en iyi değişken seçilir, diğerleri veri setinden kaldırılır. En iyi değişkeni seçmenin yolu bizlere kalmış durumda. Oluşan kümelerdeki değişkenlerle makine öğrenmesi modeli kurulup, bağımlı değişken için en önemli değişkeni seçebiliriz. Bunun haricinde kümedeki en yüksek varyansa sahip değişkeni de seçebiliriz.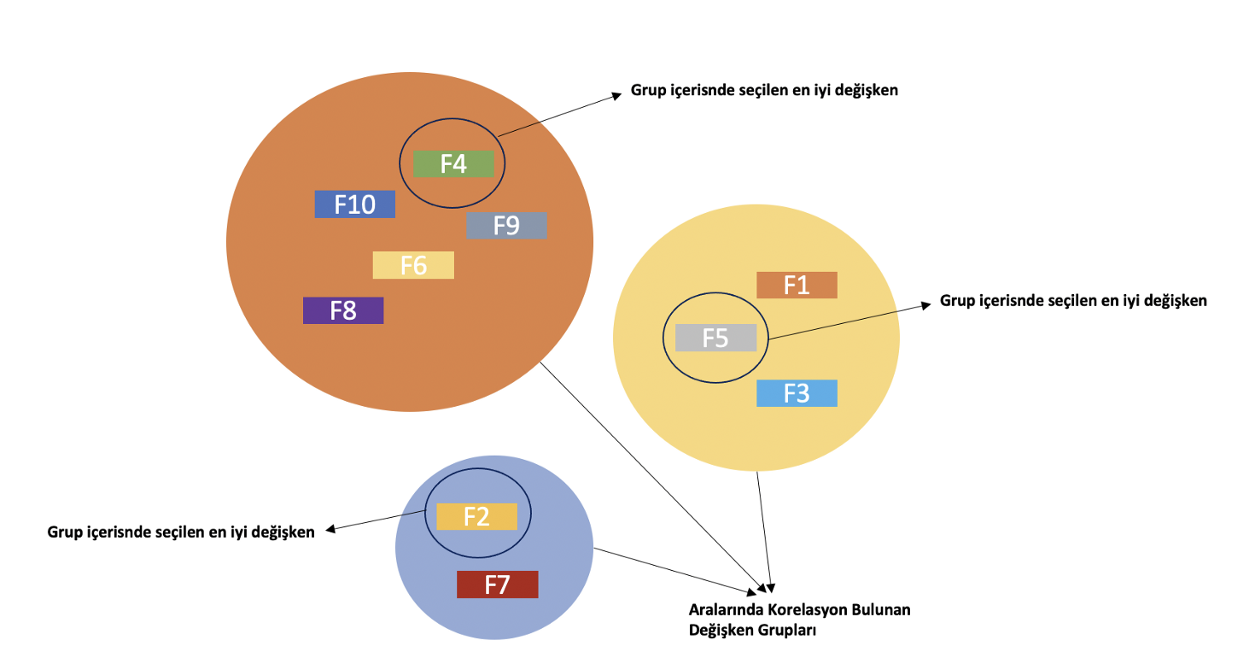
- İstatistiksel filtreleme yöntemleri: İstatistiksel filtreleme yöntemlerinde değişkenler belli kriterlere göre sıralanır ve en yüksek sıralamaya sahip olan değişkenler seçilir.
Chi-square (Ki Kare): Ki-kare testi, iki değişkenin bağımlılığını belirlemek için kullanılan istatistiksel bir bağımsızlık testidir. İki olayın birbiriyle olan bağımsızlığını test eder. Kategorik değişkenler için uygulanır. İki değişken bağımsız olduğunda daha küçük Ki-Kare değerine sahip olunur. Yani yüksek Ki-Kare değeri, bağımsızlık hipotezinin yanlış olduğunu gösterir. Basit bir deyişle, Ki-Kare değeri ne kadar yüksek olursa, değişkenler daha fazla bağımlıdır ve model eğitimi için seçilebilir.
Bu test bağlamında Scikit-Learn, istatistiksel analize dayalı olarak K sayıda özelliği seçen SelectKBest adlı bir özellik seçimi sunar.
Anova: Birbirinden farklı olan iki veya daha fazla grubun ortalamalarını kontrol etmek için kullanılan istatistiksel bir yöntemdir. Kategorik değişkenlerin sınıfları arasında sayısal bir değişkene göre anlamlı farklılık olup olmadığını ölçer. Anova ile değişken seçimi için uygulanabilecek Python kodu:
Mutual information: Bir değişkenin başka bir değişken hakkında ne kadar bilgi verdiğini ölçer. Scikit-learn kullanarak, mutual_info_classif veya mutual_info_regression yardımıyla bir değişken ile hedef arasındaki karşılıklı bilgiyi belirleyebiliriz. Mutual information ile değişken seçimi için uygulanabilecek Python kodu:
Machine Learning hakkında daha geniş kapsamlı bilgiye erişmek ve kariyerinizde Machine Learning bilginizle fark yaratmak isterseniz Miuul'un sunduğu Machine Learning Engineer Path eğitimine göz atabilirsiniz.
Kaynaklar
- Machine Learning Mastery, How to Choose a Feature Selection Method For Machine Learning
