LOFO ile Makine Öğreniminde Özellik Seçimi
Makine öğreniminde ana odak çoğunlukla değişken türetme süreci oluyor. Burada atılan adımların model başarısını doğrudan etkileyebileceğini söylemek yanlış sayılmaz. Bu süreçte kimi zaman eldeki veri ile hedef değişken arasında mantıklı korelasyonlar yakalayacak şekilde yeni özellikler arayışı içerisinde oluruz. Peki veriye eklenen her özellik model başarısını arttırır diyebilir miyiz?
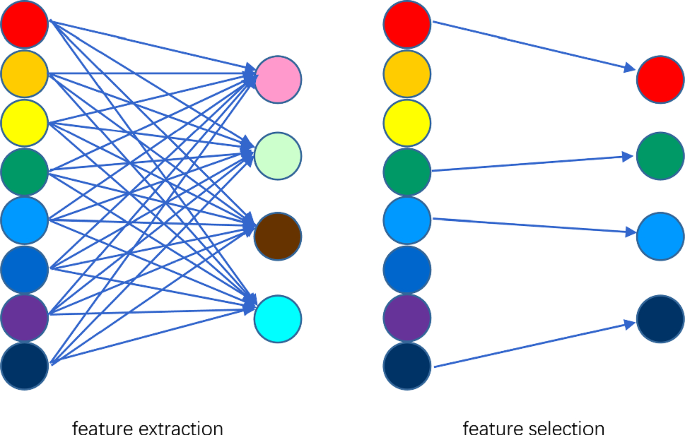
Değişken türetme & özellik seçimi
Özellik seçiminin (feature selection) önemi
Daha başarılı sonuç elde etme amacıyla modele eklenen gereksiz özellikler, modelin performansını bozmakla kalmayıp tahmin sürecini de yavaşlatabilir. Özellik seçimi, modelin performansını büyük ölçüde etkiler ve makine öğreniminin temel taşlarından biridir.
Bu süreç özünde hedef değişkene ulaşmada en fazla katkıda bulunan özellikleri otomatik veya manuel olarak seçmeye çalıştığımız bir süreç. Verilerin içinde gereksiz özelliklerin olması model doğruluğunu azaltabilir, modelin alakasız özelliklere göre öğrenmesine neden olabilir. Bu ise modelleme sürecinde sonuca yaklaşırken ortaya çıkan denklemlerin ya da kurulan ağaçların yanlış bir yapıya göre oluşmasına sebebiyet verecektir.
Özellik seçimi sürecinde, türetilen nihai veri seti modellendikten sonra değişkenlerin önem düzeyinin model üstündeki etkisine odaklanılır ve böylelikle değişkenlerin veriden çıkarılıp çıkarılamayacağı kararı verilir. Önem düzeyi düşük olan değişkenlerin çıkarılmasının ardından model tekrar kurularak esas odaklanılması gereken değişkenler üzerinden süreç tekrarlanır ve başarı artırımı hedeflenir.
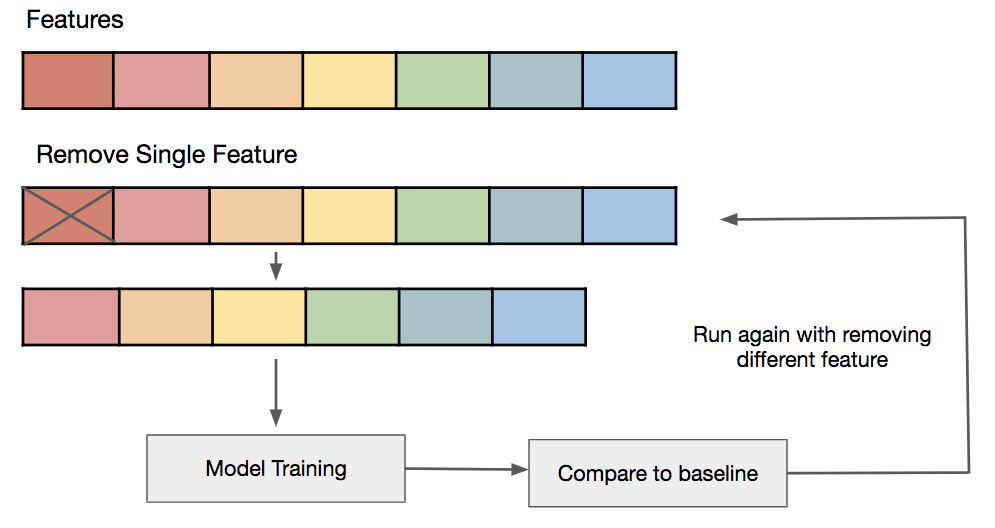
Kaynak
LOFO'nun çalışma prensibi
Özellik seçimi sürecinde veri bilimciye yardımcı olabilecek çözümler arasında en etkililerinden biri leave one feature out olarak bilinen LOFO'dur. LOFO öncelikle tüm değişkenleri kullanarak modelin performansını hesaplar. Daha sonra her iterasyonda bir özellik dışarda bırakacak şekilde değişkenlerin model üstündeki etkilerini hesaplayarak her değişken özelinde puanlar oluşturur. Her özelliğin öneminin ortalama ve standart sapmasını hesaplayarak değişken önemini raporlar ve bir seçim yapılmasını sağlar. Oluşturulan puanları daha sonra yorumlamak üzere hem lokal hem de global değişken olarak saklar.
LOFO algoritmasının yapısında bulunan one-hot-encoding fonksiyonu sayesinde kategorik değişkenlerde, değişken sınıfları iterasyona katılarak rare-analyze işlemi gerçekleştirilmiş olur. One-hottan geçirilmiş olan değişken sınıflarının aldığı puanlarla kategorik analiz işlemi tamamlanarak gerekirse ilgili sınıfın veri dışında tutulması sağlanır.
Yapısında modelleme barındıran LOFO, varsayılan olarak LightGBM ile entegre çalışmaktadır. Sayısı kullanıcı tarafından belirlenen cross-validation uygulanır ve hassas modeller ile etkili değişken seçimi yapılması hedeflenir.
Değişkenleri kategorik ve kategorik olmayan değişkenler özelinde değerlendiren LOFO, değişkenleri korelasyon matrisinden geçirir. Puanlanmış olan özellikler, belirlenen eşik değerin altında ya da üstünde kalmalarına göre değerlendirir.
Örnek uygulama
Herhangi bir feature engineering işlemi uygulamadan sadece özellik seçiminin önemi ve LOFO’nun tek başına gösterdiği etkiyi gözlemleyebilmek adına Student Performance Data Set ile örnek bir uygulama yapalım.
LOFO algoritmasının bilgisayarınıza kurulumu için terminal ekranından aşağıdaki kodu çalıştırıyoruz.
pip install lofo-importanceVeri seti 1044 satır ve 33 değişkenden oluşmakta. Kullanacağımız kütüphaneleri ve veri setlerini Python'da çağıralım.
import pandas as pd
import matplotlib.pyplot as plt
from lightgbm import LGBMRegressor
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import KFold
from lofo import LOFOImportance, Dataset, plot_importance
df1=pd.read_csv("/Users/cemistanbullu/Desktop/DSMLBC/datasets/students/student-mat.csv",sep=";")
df2=pd.read_csv("/Users/cemistanbullu/Desktop/DSMLBC/datasets/students/student-por.csv",sep=";")
df = df1.append(df2,ignore_index=True)Makine öğrenmesi için gerekli bazı tanımlamaları gerçekleştiriyoruz.
label_enc = [x for x in df.columns if df[x].nunique()==2]
for x in label_enc:
df = label_encoder(df,x)
cat_cols_new = [col for col in df.columns if df[col].dtypes == "O"]
df = one_hot_encoder(df, cat_cols_new, drop_first=True)
X = df.drop(['G3'], axis=1)
y = df["G3"]
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.20, random_state=46)Ardından LightGBM'i regresyon problemi için çağırıyoruz. Kaç katlı cross-validation uygulamak istiyorsak bu değeri KFold() fonksiyonu içerisine verip bir dataset objesi tanımlıyoruz. Dataset fonksiyonu içerisinde veriyi, tahmin etmek istediğimiz değişkeni ve bağımsız değişkenleri tanımlıyoruz. LOFOImportance() nesnesi tanımlayarak içerisine oluşturulan dataseti, cross-validation nesnesini, modeli, ve skor metriğini giriyoruz. Daha sonra işlemleri başlatıp sonuçları yorumlayabilmek için bir dataframe içerisine bastırıyoruz. Dataframe içerisinde değişken etki puanı, standart sapması ve her bir cross-validationdaki puan yer almakta.
model = LGBMRegressor().fit(X_train,y_train)
cv = KFold(n_splits=10, shuffle=True, random_state=42)
dataset = Dataset(df=df, target="G3", features=[col for col in df.columns if col != 'G3'])
lofo_imp = LOFOImportance(dataset, cv=cv, model=model,scoring="r2",n_jobs=1)
importance_df = lofo_imp.get_importance()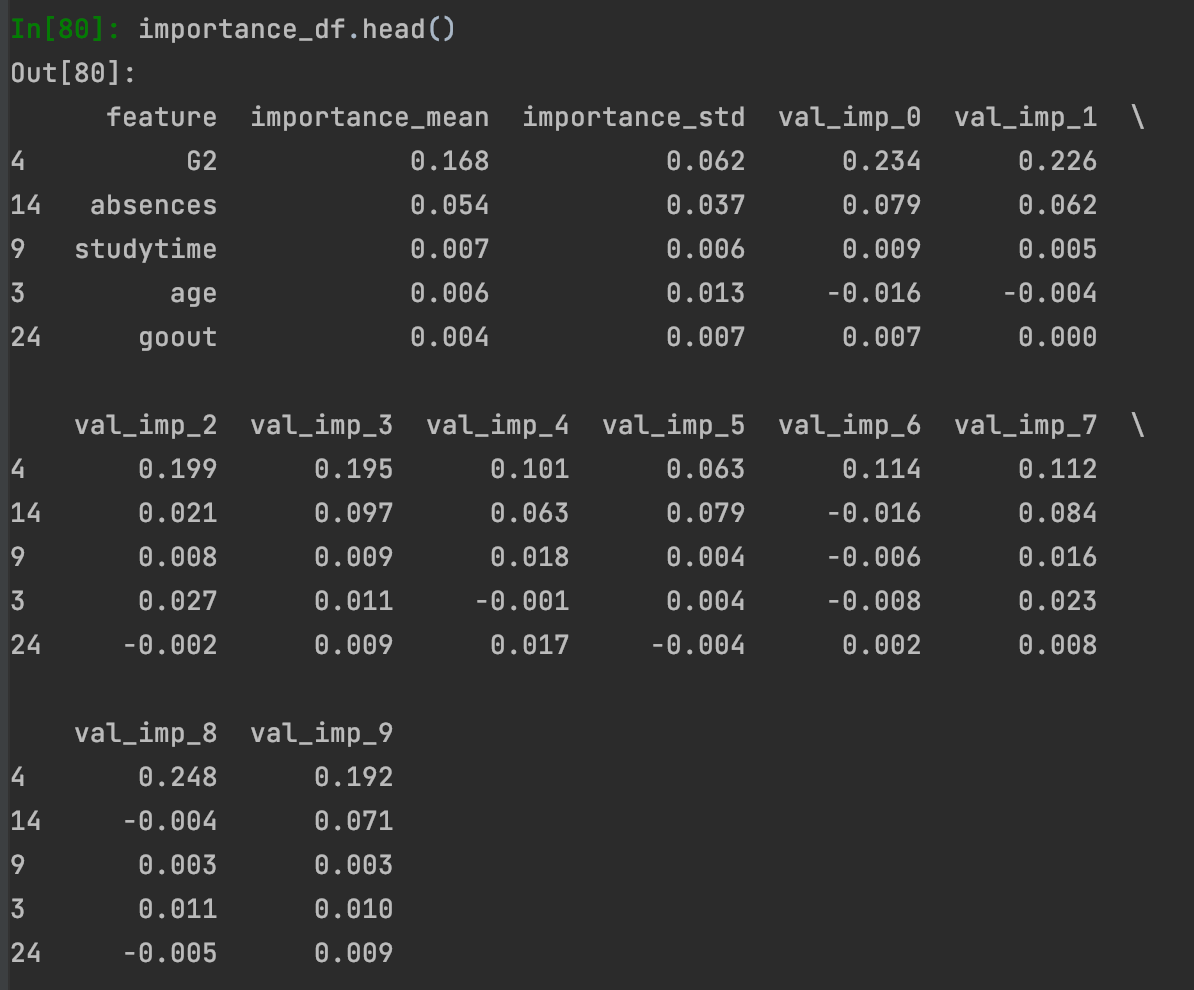
LOFOImportance sonuçlarını grafik üzerinden inceleyelim.
plot_importance(importance_df, figsize=(12, 20))
plt.show()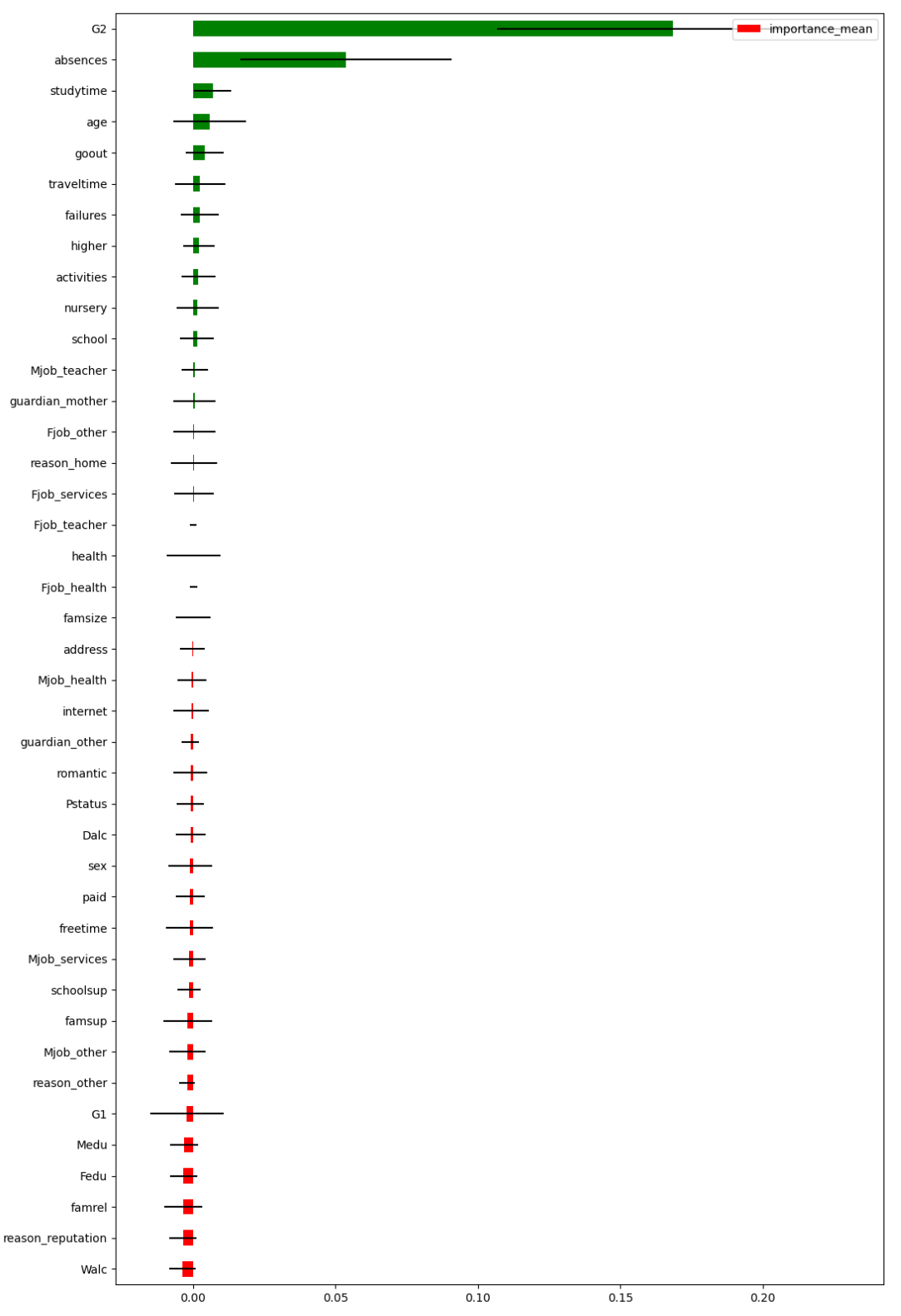
Sıfırın altında kalan değişkenler, model üzerinde olumsuz bir etkiye sahip. Tüm veri ile validasyon seti üzerinden tahmin gerçekleştirip hatamızı daha sonra karşılaştırma yapabilmek adına tutalım.
y_pred = model.predict(X_val)
first_result = mean_squared_error(y_val, y_pred)Model üstünde negatif etkiye sahip olan değişkenleri daha sonra çıkartabilmek için bir liste içerisinde sadece isimlerini tutalım.
negative = importance_df[importance_df["importance_mean"] < 0]["feature"].tolist()
Negatif puanlı değişkenleri veriden çıkartıp bizim için optimum sonucu sağlayan veriyle hiperparametre optimizasyonu yaparak yeniden model kuralım.
X2 = df.drop(negative, axis=1)
X2 = X2.drop(['G3'], axis=1)
y2 = df["G3"]
X_train2, X_val2, y_train2, y_val2 = train_test_split(X2, y2, test_size=0.20, random_state=46)
model2 = LGBMRegressor()
lgbm_params = {"learning_rate": [0.01, 0.1],
"n_estimators": [500, 1000],
"max_depth": [3, 5, 8],
"colsample_bytree": [1, 0.8]}
lgbm_cv_model = GridSearchCV(model2,
lgbm_params,
cv=10,
n_jobs=-1,
verbose=1).fit(X_train2, y_train2)
lgbm_tuned = LGBMRegressor(**lgbm_cv_model.best_params_).fit(X_train2, y_train2)LOFO’nun sunmuş olduğu bilgi ışığında hazırladığımız veri ile çalışarak modeli optimum hale getirdik. Buradan gelen tahmin hatası ile tüm veriyle kurulan modelin tahmin hatasını karşılaştırdığımızda hatanın azaldığını, model başarısının yükseldiğini gözlemleyeceğiz.
y_pred2 = lgbm_cv_model.predict(X_val2)
second_result = mean_squared_error(y_val2, y_pred2)
second_result < first_result
Machine Learning hakkında daha geniş kapsamlı bilgiye erişmek ve kariyerinizde Machine Learning bilginizle fark yaratmak isterseniz Miuul'un sunduğu Machine Learning Engineer Path eğitimine göz atabilirsiniz.
Kaynaklar
- Github, Lofo-importance, 14 Ocak 2019
- Medium, Feature Selection: Beyond feature importance?, 22 Eylül 2019
