ML101: Gözetimsiz öğrenme
Etiketlenmemiş veriler ile tahmine dayalı bir makine öğrenmesi gerçekleştirilmek istendiğinde gözetimsiz makine öğrenmesi uygulamalarına başvurulur. Gözetimsiz makine öğrenmesinde etiketlenmemiş veri kümeleri, insan müdahalesine ihtiyaç duyulmadan analiz edilir. Değişkenler arası kalıplar ve veri gruplarının ilişki yolları ortaya çıkarılır. Değişkenlerdeki benzerlikler ve farklılıkların nedenleri keşfedilerek gerçek sonuçları bilinmeyen verilerde makine öğrenmesi uygulanır. Yönteme gözetimsiz öğrenme denmesinin nedeni modellerin etiketlenmemiş veri kümesiyle eğitilmesidir.
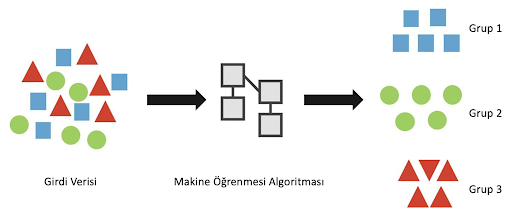
Gözetimsiz öğrenme nerede kullanılır?
Müşteri segmentasyon uygulamalarında, birbirine benzer kullanıcıları tespit eden öneri sistemlerinde, sahtekarlık tespiti çalışmalarında ve kusurlu mekanik parçaların tespit edilmesi gibi anomali tespit uygulamalarında gözetimsiz öğrenme kendine yer bulmaktadır.
Gözetimsiz öğrenme ne zaman kullanılır?
Verilerin etiketi, yani ilgili satırları temsil eden ve tahmin edilmesi gereken gerçek bir değerin olmadığı zamanlarda gözetimsiz makine öğrenmesine başvurulabilir.
Gözetimsiz öğrenme nasıl çalışır?
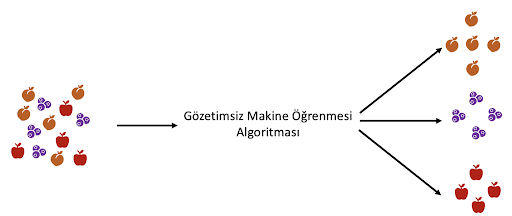
Gözetimsiz öğrenmede model, kendisini verilerden eğiterek geliştirir. Elimizde bir grup cinsini bilmediğimiz meyvenin olduğunu ve yalnızca bu meyvelere ait özellikleri bildiğimiz düşünelim. Bu durumda meyvelerin cinsini (elma, şeftali, böğürtlen gibi) belirlemek için kümeleme algoritmasını kullanabiliriz. Amaç modelin elma, şeftali ve böğürtleni ayırt edebilmeyi öğrenmesini sağlamaktır. İşe elma, şeftali ve böğürtlenin özellikleri karşılaştırarak başlanır. Algoritma şekil, boyut ve renk gibi karakteristik özelliklere göre bir sınıflandırma yapacaktır. Örneğin elma ne büyük ne de küçük boyutlu, basık şekilli ve kırmızı renklidir. Şeftali elmaya benzer ancak turuncu renktedir. Böğürtlen ise küçük, yuvarlak ve mor renklidir. Model bu kimlik bilgilerine dayalı olarak meyve cinsleri (sınıflar) arasında birbirinden ayrılan noktaları öğrenecektir. Bir elmanınkine benzer veri noktaları bir küme, bir şeftali ve böğürtleninkilere benzer veri noktaları da ayrı birer küme oluşturacaktır.
Gözetimsiz öğrenme teknikleri nelerdir?
Gözetimsiz öğrenme yöntemleri arasında kümeleme başlığı altında k-ortalama kümelemeyi ve müşteri özelinde tavsiyelerde bulunan tavsiye sistemlerinin vazgeçilmez algoritması olan aprioriyi sayabiliriz.
K-ortalama kümeleme (K-means clustering)
K-ortalama algoritması bir kümeleme algoritmasıdır. Başında bulunan “K” tahmin edilecek değişkenin kaç kümeye ayrılacağını yani değişken içerisinde kaç tekil gözlem bulunduğunu temsil eder. Örneğin yukarıda bahsetmiş olduğumuz örnekte elma, şeftali ve böğürtlen mevcuttu. Bu problemde “K” değeri 3 olacaktır. Peki ama bu algoritma nasıl çalışıyor?
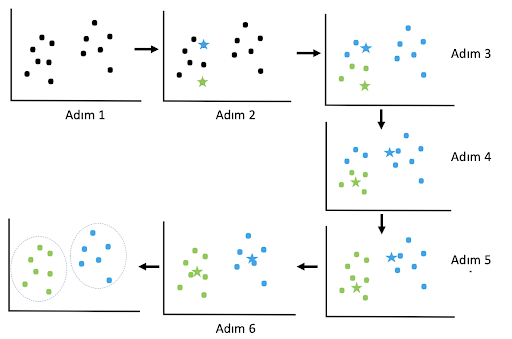
Model “K” sayıda ortak merkez nokta bulmaya çalışır. Yukarıdaki görseldeki ikinci adımda da görüldüğü üzere başlangıçta veriler arası farklar bilinmediği için kümeler arası merkezler rastgele bir şekilde seçilir. Ortak noktalar belirlendikten sonra, merkez-veri arası en yakın küme merkez noktaları hesaplanır ve ilk temsili grup atamaları öklid mesafesi metriğini kullanarak, üçüncü adımdaki gibi yapılır. Ardından kümelerin tüm veri noktalarının ortalaması hesaplanarak merkezler yeniden belirlenir. En tutarlı merkezi belirlemek için uzaklıklar hesaplanır ve merkez seçimi her durum için tekrarlanır. Merkez noktası öklid hesabına göre belirlendikten sonra veri kümeleri oluşturulmuş olur.
K-ortalama algoritması, bankacılık sektöründe kredi kartı dolandırıcılığı, kara para aklama ve sahtekarlık tespiti gibi anomali içeren alanlarda yaygın olarak kullanılmaktadır.
K-ortalama kümeleme algoritmasını FLO’nun gerçek hayat verisi ile uygulamalı bir şekilde çalışmak için Miuul'un Data Scientist Path eğitimine kayıt olabilirsiniz.
Apriori
Apriori algoritması, veri bilimi dünyasında tavsiye sistemlerinde karşımıza çıkan gözetimsiz makine öğrenmesi araçlarından birisidir. Veri setinde bulunan ürünlerin, kullanıcıların, analizi gerçekleştirilen maddeler ne ise onların birlikte görülme durumlarını analiz edip kurallar ve sonuçlar çıkaran bir yöntemdir.
Apriori algoritması, sık tekrarlanan öğeleri bulmak için tasarlanmış bir algoritmadır. Support ve confidence parametreleri kullanılır. Support, öğelerin veride görülme sıklığını ifade ederken confidence koşul olasılığını temsil eder. Veri boyunca sıklıklar her sepet bazında belirlenerek karşılaştırılmaya başlanır. Sepetler daha büyük ve sık oluncaya dek tüm verideki ürünler için karşılaştırılır.
Apriori algoritmasının en çok kullanıldığı senaryo ürün birlikteliği analizidir. Müşterinin hali hazırda aldığı ürünlere ek olarak, aldığı ürünlerle beraber en çok tercih edilen ürünü veya ürünleri alması tavsiye edilir. E-ticaret sitelerinde ve market raflarında sıklıkla kullanılmaktadır.
Apriori algoritmasını Armut’un gerçek hayat verisi ile uygulamalı bir şekilde çalışmak için Miuul'un Data Scientist Path eğitimine kayıt olabilirsiniz.
Gözetimsiz makine öğrenmesinde sıklıkla kullanılan kümeleme ve birliktelik kuralları çıkaran apriori yöntemlerine değindik. Özetle gözetimsiz öğrenme yöntemleri, büyük hacimli etiketsiz verilerden içgörüler, kurallar ve sınırlar elde ederek veri grupları arasındaki farkları ortaya çıkaran yöntemlerdir.
Gözetimsiz makine öğrenimi, sonuçlarını kesin olarak doğrulayabileceğimiz veriler kullanılarak yapılmadığı için analiz sonunda elde edilen sonuçların geliştirici ya da iş uzmanı tarafından detaylı incelemeden geçmesi gerekmektedir. Örneğin tavsiye sistemlerinde çıkan birliktelik kurallarının iş bilgisine uyup uymadığının ilgili birimin denetiminden geçmesi gerekmektedir.
Kaynaklar
- Scikit-learn, 2.3. Clustering — Scikit-Learn 1.1.1 Documentation.
- TechTarget, What Is Unsupervised Learning?
- reddit.com, K-Means Clustering Algorithm.
