Veri Bilimi ile Tavsiye Sistemleri
Tavsiye sistemleri genel olarak kullanıcılara bazı teknikleri kullanarak, ürün veya hizmet önerme yapılarıdır. 1990 ve 1994 yıllarında ortaya çıkan iki farklı çalışma ile dijital kitaplık isimlendirmesiyle ilk kez gündeme gelmiştir. Radyo programları, e-ticaret siteleri, arkadaşlık uygulamaları, sosyal medya kanalları gibi birçok sistem ve altyapıda kullanılmaktadır.
İçeriklerin çok geniş olduğu yapılarda, kullanıcının kişisel ilgi alanlarına göre, sahip olunan içeriklerin filtrelenmesi ihtiyacına cevap verir. Geniş içerikler barından veri yapılarının kullanıcının ilgi alanları özelinde alt kümelere indirgenmesiyle, daha küçük veri setlerini kullanıcıya ulaştırma ihtiyacına çözüm üreten sistemlerdir.
Kısacası genel amaç çok olan olası içerik, ürün, hizmet, film vb. durumları filtrelemek; bu filtrelemeyi de yaparken kullanıcının ilgi alanları ile örtüşebilecek şekilde daha akıllı bir sistem oluşturma çabasıdır.
Bazı tavsiye sistemlerini göz atacak olursak:
- Basit tavsiye sistemleri (simple recommender systems): İş bilgisi ya da basit tekniklerle yapılan genel önerilerdir. Örneğin belirli kategorilerin en yüksek puanlıları, trend olanlar, efsaneler ve benzeri yapılar.
- Birliktelik kuralı öğrenimi (association rule learning): Birliktelik analizi ile öğrenilen kurallara göre ürün önerileri gerçekleştirilir. Çok sık bir şekilde birlikte satın alınan ürünlerin olasılıklarının çıkarılmasıyla bu olasılıklara göre belirli öneriler yapılmasına imkan sağlar. Sepet analizi olarak da adlandırılan bu yapı, çevrimdışı ve çevrimiçi birçok şirketin kullanabileceği türden bir analiz yöntemidir. Özellikle e-ticaret tarafında tavsiye sistemleri altyapısı olarak da yaygınca kullanılır.
- İçerik temelli filtreleme (content based filtering): Ürünlerin meta bilgilerine, açıklamalarına, özelliklerine göre benzerlikler üzerinden yapılan öneri sistemleridir. Başka bir deyişle benzerliğe göre öneriler yapılan uzaklık temelli yöntemlerdir. Örneğin bir ürün satın alındığında, satın alınan ürünün açıklamasına en benzer açıklamaya sahip olan ürünlerin tavsiye edilmesi yöntemidir.
- İş birlikçi filtreleme (collaborative filtering): Topluluğun kullanıcı ya da ürün bazında ortak kanaatlerini yansıtan yöntemlerdir. Bir örnek üzerinden açıklamak gerekirse; bir filmi beğenen topluluk başka bir filmi de beğendiyse, ilk filmi beğenen bir potansiyel izleyicinin ikinci filmi de beğenebileceği varsayılabilir. Bu kapsamda ilk filmi beğenip ikinci filmi henüz beğenmemiş olan kullanıcılara ikinci film önerilebilir. Bu teknik kullanıcı temelli (user-based), ürün temelli (item-based) veya model temelli (matrix factorization) gerçekleştirilebilir. Bu tekniklerde kullanıcı ve ürün temelli teknikler memory-based, model temelli teknik ise latent factor models (bir başka ifadeyle komşuluk metotları) olarak da adlandırılır.
Birliktelik kuralı öğrenimi (association rule learning)
Kullanıcılara ürün ya da hizmet önerme, yani tavsiyelerde bulunmak istenilen durumlarda kullanılan yöntemlerden biridir. Veri içerisindeki örüntüleri bulmak için kullanılan kural tabanlı bir makine öğrenmesi tekniğidir. Geçmişte veri madenciliği tekniği olarak da literatürde geçen birliktelik kuralı öğrenimi, ilerleyen dönemlerde yapay zeka tekniği olarak da karşımıza çıkabilmektedir. Bir örnek vermek gerekirse bir perakende satış yapan bir şirket olan Wallmart yaptığı analizler sonucunda ulaştığı gözlemlerde, bebek bezi ile bira arasında bir ilişki olduğu sonucuna varmıştır. Belirli bir zaman periyodunda, bebek bezi alanların çok büyük olasılıkla bira da aldığı görülmüştür. Wallmart bunun sonucunda reyonların dizilimini bu bilgiye göre oluşturup, satışlarında ciddi oranda bir artış meydana getirmiştir.
Bir örnek ile bu yapıyı betimleyelim. Her bir kullanıcı yaptıkları alışverişler sonucunda bir alışveriş fişi meydana getirmektedir. Bu alışveriş fişlerinde yüksek bir oranda birlikte alınan ürün çiftleri belirlenir. Gözlemlediğimiz oran, üzerinde çalıştığımız satın alınan ürün çiftlerinin birlikte alınma olasılığına dair istatistiki bir bilgi sunar. Birliktelik kuralını kısaca bu şekilde betimleyebiliriz.
Apriori algoritması
Apriori, sepet analizi yöntemidir. Ürünlerin birlikteliklerini ortaya çıkarmak için kullanılır. Apriori algoritması, bir önceki bölümde belirttiğimiz örnekteki birliktelik kuralı öğrenimini daha programatik olarak, daha büyük veri setleri üzerinde ve çeşitli istatistikleri de hesaplayacak şekilde uygulama imkanı sunar.
Apriori algoritması üzerinden hesaplanabilen, yorumları değerli olan üç temel metrik bulunur. Bu üç temel metrik ile veri seti içerisindeki ilişki örüntülerini, yapılarını gözlemleme ve ilişkileri istatistiksel bir ölçüt ile değerlendirme imkanı bulunur.
- Support (X,Y) = Freq(X,Y)/N: Support değeri X ve Y’nin birlikte görünme frekansının tüm işlemlere oranı olarak hesaplanır. Yani X ve Y’nin birlikte görülme olasılığıdır. Değer yüksek olması, bu ürünlerin yüksek bir seviyede birlikte görüldüğünü ortaya koyarken bu bilgiden yola çıkarak çeşitli pazarlama ve operasyonel stratejiler oluşturulabilir.
- Confidence(X,Y) = Freq(X,Y)/Freq(X): Confidence değeri X ve Y’nin birlikte görünme frekansının X’in frekansına oranıdır. X alındığında Y’nin satılması olasılığıdır. Yani bir ürünün satılması üzerinden diğerinin de satın alınması olasılığının ne şekilde etkinlediği gözlemlenir.
- Lift = Support(X,Y)/(Support(X)*Support(Y)): Lift değeri, X satın alındığında Y’nin satın alınma olasılığı Lift kadar artar yorumunun yapılasını sağlar.
Şimdi Apriori algoritmasının kullanıldığı bir örnek inceleyelim:

Örnekte görülebildiği üzere yapılan tüm işlemlerin sayısına göre ekmeğin satın alınma frekansı 4 ve sütün 6 iken, ekmek ve sütün birlikte satın alınma frekansı 3’tür. Bu kapsamda Apriori algoritmasının üç temel metriğini yukarıda gibi incelenirse ekmek satın alındığında süt satın alınma olasılığı gözlemlenebilir. Lift değerinin sonucunda ise ekmeğin satın alınması durumunda süt satın alımı 1 kat artar yorumu yapılabilir.
İçerik temelli filtreleme
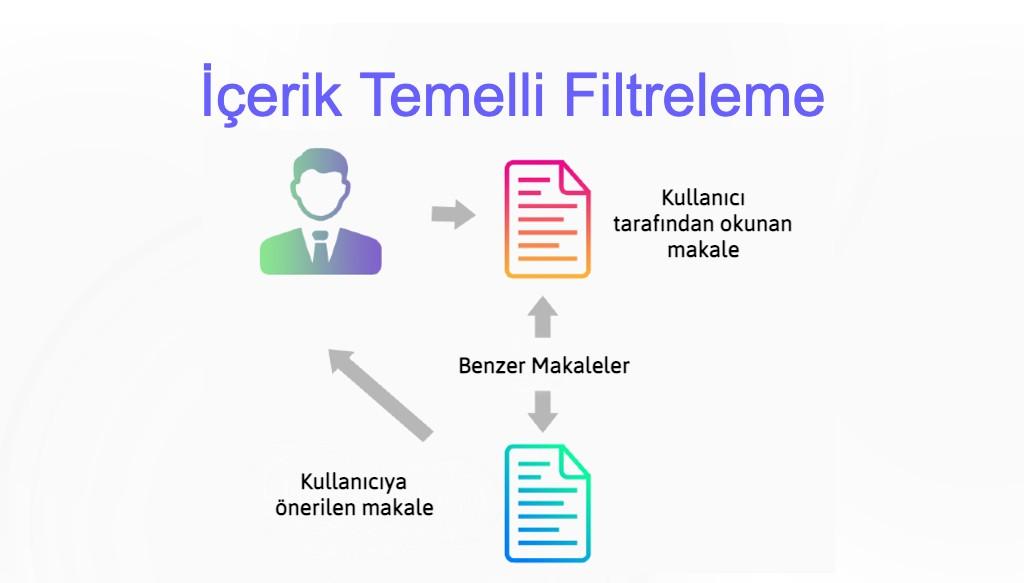
Temelinde ürün içeriklerinin benzerlikleri üzerinden tavsiyeler geliştirilen bir yöntemdir. Buradaki içeriğe ise bir ürünün kategori bilgisi, bir dizinin yönetmeni/oyuncu kadrosu, bir ürünün açıklamasındaki bilgiler şeklinde örnek verilebilir. Bu içeriklere dış bilgi/meta bilgiler denir. Elimizdeki nesnenin meta bilgileri üzerinden benzerlikler hesaplanır ve ilgili ürüne en benzer olan ürünler önerilir. İçerik temelli filtreleme yöntemi kullanıcı bilgilerine ve etkileşimlerine sahip olmadığımız, elimizde yalnızca içerik temelli bir yapı olan durumlarda kullanılır. Örnek olarak bir kullanıcı bir şarkı dinlediğinde sahip olduğumuz tek bilgi, dinlediği şarkıdır. Bu kullanıcıya dinlediği şarkının türünde başka bir şarkı önermek, içerik temelli filtreleme sonucu bir öneride bulunmaya örnektir.
Başka bir örnekte durumu derinlemesine incelemek gerekirse: Bir kullanıcının bir dizi izlediğini düşünelim. Kullacının izlediği dizinin açıklamalarındaki metinleri matematiksel ve ölçümlendirilebilir bir forma getirip, bu form üzerinden başka bir filmin ölçümlendirilebilir forma getirilmiş açıklamasına en yakın olan film önerilebilir. Buna metinleri matematiksel olarak temsil etme veya metinleri vektörleştirme denir. Ardından bu matematiksel temsiller üzerinden çeşitli metriklerle benzerlikleri hesaplayıp kullanıcıya öneri yapılabilir.
Metinlerin vektörel temsilleri
Açıklamalardaki kelimeler film indeksinde vektörleştirilerek matris oluşturulur. Bu kelimeler özelinde kullanım sayılarına göre sayısal değerlerle matrisimizde betimlenir. Bu sayısal değerler üzerinden Öklid uzaklığı hesabı ve cosine similarity hesabıyla filmlerin birbirine olan yakınlığı hesaplanıp, bu yakınlık derecesine göre önerilerde bulunulur. Bu vektörleştirme işlemlerinde yaygın olarak iki yöntem kullanılır:
- Count vector (word count, sayım vektörü): Metinsel ifadeleri matematiksel metriklere dönüştürme tekniğidir. Öncelikle eşsiz tüm terimleri (kelimeleri) sütunlara, bütün dokümanları (satırlara konulacak kavramlar, film açıklamaları, tweetler, ürün başlıkları vb.) satırlara yerleştiririz. Ardından terimlerin dokümanlarda geçme frekansları hücrelere yerleştirilir. Oluşan tablomuz vektörleştirilmiş bir matris halinde olur ve Öklid uzaklığı hesabı ve Cosine Similarity hesabı yapılabilir hale gelir.
- TF-IDF (term frequency-inverse document frequency): Kelimelerin hem kendi metinlerinde, hem de bütün odaklanılan verideki geçme frekansları üzerinden bir normalizasyon işlemi yapar. Count vector yönteminde ortaya çıkabilecek bazı yanlılıkları (frekansı yüksek olan değerlerin analiz sonuçlarını yanıltması gibi) giderir. TF-IDF dört adımda hesaplanabilir: İlk adımda count vector yani kelimelerin her bir dokümandaki frekansı hesaplanır. İkinci adımda term frequency (t teriminin ilgili dökümandaki frekansı / dokümandaki toplam terim sayısı) yani terimlerin frekansları hesaplanır. Üçüncü adımda inverse document frequency (IDF) hesaplanır. Dördüncü adımda TF*IDF hesaplanır.
IDF=1+(loge((toplam doküman sayısı+1)/içinde t terimi olan doküman sayısı+1)))
Son adımda L2 Normalizasyonu yapılır. Satırların kareleri toplamının karekökü bulunur. İlgili satırdaki tüm hücreler, bulunan değere bölünür. Böylece L2 Normalizasyonu yapılmış olur.
İş birlikçi filtreleme

Topluluğun kullanıcı ya da ürün bazında ortak kanaatlerini yansıtan yöntemlerdir. Kullanıcıların etkileşimlerine sahip olunan durumlarda kullanılır. Bu yöntemler yaygın olarak üç şekilde uygulanır:
- Item-based collaborative filtering (ürün temelli iş birlikçi filtreleme): Ürün benzerlikleri üzerinden tavsiyeler yapılır. Örneğin, izlenen bir filmin beğenilme yapısı (puan verilme alışkanlıkları) üzerinden benzer bir beğenilme yapısına sahip başka bir filmi kullanıcıya önerme tekniğidir. Kullanıcıların beğenilme alışkanlıkları üzerinden filmler arasında yüksek korelasyon değerlerinden gözlemler yapılır ve en yüksek korelasyonlu filmler önerilir.
- User-based (kullanıcı temelli iş birlikçi filtreleme) collaborative filtering: Kullanıcıların birbirlerine benzerlikleri üzerinden öneriler yapılır. Örnek olarak aksiyon filmleri izleyen bir kullanıcıya, kendi izleme alışkanlıklarına en benzer izleme geçmişine sahip başka bir kullanıcının izlediği filmlerin önerilmesini verebiliriz.
- Model-based collaborative filtering (kullanıcı temelli iş birlikçi filtreleme, matrix factorization): Oluşturulan veri setinde, her kullanıcının her filmi puanlamamasından ötürü oluşan boşlukları gidermek ve kullanıcılarla filmler icin olduğu varsayılan gizli özelliklerin (içeriklerin) ağırlıkları var olan veriler üzerinden bulunur. Bu ağırlıklar ile var olmayan gözlemler için tahminler yapılır. Çalışmanın asıl odağı ağırlıklardır.
Bu yazımızda e-ticaret sitelerinden, popüler yayın platformlarına kadar birçok sektörde kullanılan tavsiye sistemlerine değindik. Tavsiye sistemleri hakkında daha detaylı bilgi edinmek isterseniz Miuul'un Tavsiye Sistemleri üzerine oluşturduğu eşsiz eğitimlere mutlaka göz atın. Veri bilimini kariyer yolunuz haline getirmek istiyorsanız, Miuul’un Veri Bilimci Kariyer Yolculuğu tam olarak aradığınız eğitimi sizlere sunacaktır.
Kaynaklar
- Veri Bilimi Okulu, Öneri Sistemleri 101
- Miuul, Tavsiye Sistemleri
- Data Science Earth, Recommendation Engine (Tavsiye-Öneri Sistemleri)
- Wikipedia, Recommender system
